This blog entry was co-authored with Josh Long, Developer Advocate extraordinaire at Broadcom, stewards of Spring technologies.
The newly announced Spring AI 1.0, a comprehensive solution for AI engineering in Java, is now available after a significant development period influenced by rapid advancements in the AI field. The release includes numerous essential new features for AI engineers.
Java and Spring are in a prime spot to jump on this whole AI wave. Tons of companies are running their stuff on Spring Boot, which makes it super easy to plug AI into what they’re already doing. You can basically link up your business logic and data right to those AI models without too much hassle.
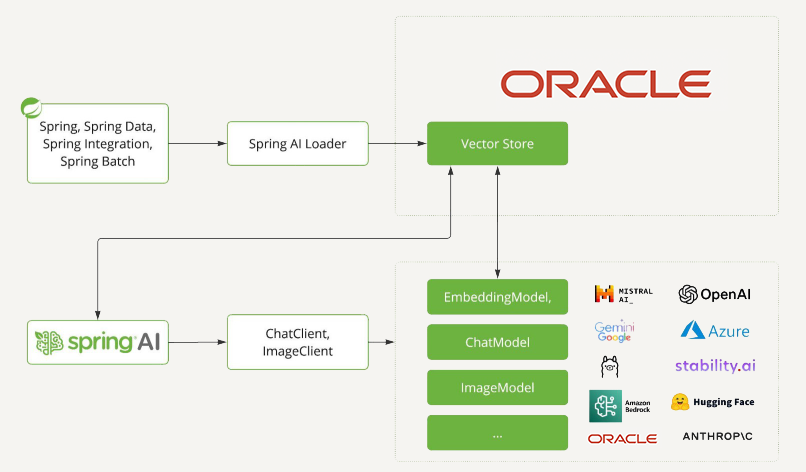
Spring AI provides support for various AI models and technologies. Image models can generate images given text prompts. Transcription models can take audio and convert them to text. Embedding Models are models that convert arbitrary data into vectors, which are data types optimized for semantic similarity search. Chat Models should be familiar! You’ve no doubt even had a brief conversation with one somewhere. Chat models are where most of the fanfare seems to be in the AI space. They’re awesome. You can get them to help you correct a document or write a poem. (Just don’t ask them to tell a joke.. yet.) They’re awesome but they have some issues.

(The picture shown is used with permission from the Spring AI team lead Dr. Mark Pollack)
Let’s go through some of these problems and their solutions in Spring AI. Chat Models are open-minded and given to distraction. You need to give them a system prompt to govern their overall shape and structure.
AI models don’t have memory. It’s up to you to help them correlate one message from a given user to another by giving them memory.
AI models live in isolated little sandboxes, but they can do really amazing things if you give them access to tools – functions that they can invoke when they deem it necessary. Spring AI supports tool calling which lets you tell the AI model about tools in its environment, which it can then ask you to invoke. This multi-turn interaction is all handled transparently for you.
AI models are smart but they’re not omniscient! They don’t know what’s in your proprietary databases – nor I think would you want them to! So you need to inform their responses by stuffing the prompts – basically using the all mighty string concatenation operator to put text in the request that the model considers before it looks at the question being asked. Background information, if you like.
You can stuff it with a lot of data, but not infinite amounts. How do you decide what should be sent and what shouldn’t? Use a vector store to select only the relevant data and send it in onward. This is called retrieval augmented generation, or RAG.
AI chat models like to, well, chat! And sometimes they do so so confidently that they can make stuff up, so you need to use evaluation – using one model to validate the output of another – to confirm reasonable results.
And, of course, no AI application is an island. Today modern AI systems and services work best when integrated with other systems and services. Model Context Protocol (MCP) makes it connect your AI applications with other MCP-based services, regardless of what language they’re written in. You can assemble all of this in agentic workflows that drive towards a larger goal.
And you can do all this while building on the familiar idioms and abstractions any Spring Boot developer will have come to expect: convenient starter dependencies for basically everything are available on the Spring Initializr. Spring AI provides convenient Spring Boot autoconfigurations that give you the convention-over-configuration setup you’ve come to know and expect. And Spring AI supports observability with Spring Boot’s Actuator and the Micrometer project. It plays well with GraalVM and virtual threads, too, allowing you to build super fast and efficient AI applications that scale.
What’s this mean for you?
It means that you, with your Oracle database deployments, are already well positioned to be a part of these game changing new paradigms! In this article, we’re going to look at how to get started with Oracle Database and its vector support, look at what it brings to the table, and how it can do the heavy lifting in any AI-first and data-driven Spring Boot and Spring AI application.
If you’ve already got an Oracle database installed, then you can skip this section. For the rest of you, listen up. Oracle is the premium database regardless of the storage format, be it relational, documents (JSON), graph, spatial, time series, vectors, and more. It provides more features than you can shake an LLM-rendered stick at. Common knowledge! Did you know you can run it for free? And not just for development, too; we mean you can run it in production for a decent amount of scale and size. It’s called Oracle Database Free. The current version, specifically, is called Oracle Database 23ai Free. It includes many features found in Oracle Database Standard and Enterprise Editions, but with some resource limits including 1 CPU, 2 GBs of RAM, and 12GB of user data on disk.
That’s more than enough to get most applications off the ground!
Its license is quite permissive, allowing you to run it in development, testing, and production environments for free. Oracle Database 23ai Free it’s available on Windows, Linux, and macOS for both Intel and ARM architectures. You may also run it inside container runtimes such as Docker and Podman.
You can get the container image, more details on the features, and everything else here.
Let’s look at how to use Oracle Database and Spring AI to build an AI-first, scalable, observable, and fast application.
The sample application
We’re building a fictitious dog adoption agency called Pooch Palace. It’s like a shelter where you can find and adopt dogs online! And just like most shelters, people are going to want to talk to somebody, to interview the dogs. And we’re gonna build a service to facilitate that, an assistant.
We’ve got a bunch of dogs in the relational database that we’ll install when the application starts up. Our goal is to build an assistant to help us find the dog of (somebody’s!) dream, Prancer, who is described rather hilariously as “A demonic, neurotic, man hating, animal hating, children hating dogs that look like gremlins.” This dog’s awesome. You might’ve heard about him. He went viral a few years ago when his owner was looking to find a new home for him. The ad was hysterical, and it went viral! Here’s the original post, in Buzzfeed News, in USA Today; and in the New York Times.
We’re going to build a simple HTTP endpoint that will use the Spring AI integration with an LLM (in this case, we’ll use Open AI though you can use anything you’d like including Ollama, Amazon Bedrock, Google Gemini, HuggingFace, and scores of others – all supported through Spring AI) to ask the AI model to help us find the dog of our dreams by analysing our question and deciding – after looking at the dogs in the shelter (and in our database) – which might be the best match for us.
First things first: go to the Spring Initializr specify an artifact ID of `oracle`, and add the following dependencies to your Spring AI project: Web, Actuator, GraalVM, Devtools, OpenAI, Oracle Vector Database, and Docker Compose. We’re using Java 24 and Apache Maven, but you go whichever way you’d like.
Download the .zip file, open it in your favorite IDE, and let’s get going. The first tithing we should do is customize the Docker Compose compose.yml file. It’s been generated in such a way that Spring Boot will automatically connect to it correctly, but the port won’t be exposed so you won’t be able to connect to it. And the username and password by which you should connect will also be unspecified. So, change your compose.yml to look like this:
services:
oracle:
image: ‘gvenzl/oracle-free:latest’
environment:
– ‘ORACLE_PASSWORD=secret’
– ‘APP_USER=test’
– ‘APP_USER_PASSWORD=test’
ports:
– ‘1521:1521’
This will seed a default username and password for you, a developer to use. And it’ll export the port so you can connect to this relational database from a client or an IDE client.
Put the following in your application.properties, and we’ll walk through the changes.
spring.application.name=oracle
# observability
management.endpoints.web.exposure.include=*
# scale
spring.threads.virtual.enabled=true
# docker
spring.docker.compose.lifecycle-management=start_only
# sql
spring.sql.init.mode=always
spring.datasource.password=test
spring.datasource.username=test
spring.datasource.url=jdbc:oracle:thin:@localhost:1521/FREEPDB1
# ai
spring.ai.vectorstore.oracle.remove-existing-vector-store-table=true
spring.ai.vectorstore.oracle.initialize-schema=true
spring.ai.vectorstore.oracle.dimensions=1536
spring.ai.vectorstore.oracle.index-type=ivf
spring.ai.vectorstore.oracle.distance-type=cosine
We’ve used comments to mark off certain sections in the document. In the scale section, we’ve got virtual threads enabled. We will talk about that in a second.
The observability section tells the Spring Boot Actuator, which surfaces information about our application, to show every endpoint. You probably don’t want to do this in production without locking down these endpoints! But it’s surely useful to understand what’s visible, right now, for this demonstration.
In the docker section, we’ve told the spring boot docker compose support to not automatically stop and then restart the Docker image each time. Instead, it’ll start it only if it’s not already running.
In the sql section, we’ve specified the connectivity details for Oracle Database. Again, you’d still be productive during development even if you didn’t specify this, but having these values handy can be convenient if you want to point your favorite database tool to the database.
If you want to connect this database from the command line, install the Oracle SQLcl command line and then run:
sql test/test@localhost:1521/FREEPDB1
The spring.sql.init.mode=always property is interesting because it tells spring boot to automatically run schema.sql and data.sql, in the src/main/resources folder, to initialize our database. This will be convenient for ensuring we have valid schema and data for our sample application. (We’ll look at that in a moment)
In the ai section we’ve got configuration on how we want Spring AI to use Oracle Database as a vector store to support semantic similarity searches a bit later on.
There’s one property you don’t see here: the credential for your OpenAI account. Spring Ai provides Spring Boot-style autoconfiguration and will automatically create a connection to the model of your specification, assuming you’ve furnished credentials. This application is using OpenAI, so you’ll need to specify one more property (after signing up for a free account and getting an API key): `spring.ai.openai.api-key=<YOUR_KEY>`.
Or, alternatively, you could use Oracle’s awesome AI models, too! Spring AI supports them, though we’ll probably dive more into that in a subsequent article.
Now let’s seed our database with valid schema and data. Create src/main/resources/schema.sql:
create table if not exists dog
(
id integer primary key,
name varchar(255) not null,
owner varchar(255) null,
description varchar(255) not null
);
Create src/main/resources/data.sql:
delete from dog;
insert into dog (id, name, description)
values (87, ‘Bailey’, ‘A tan Dachshund known for being playful.’);
insert into dog (id, name, description)
values (89, ‘Charlie’, ‘A black Bulldog known for being curious.’);
insert into dog (id, name, description)
values (67, ‘Cooper’, ‘A tan Boxer known for being affectionate.’);
insert into dog (id, name, description)
values (73, ‘Max’, ‘A brindle Dachshund known for being energetic.’);
insert into dog (id, name, description)
values (3, ‘Buddy’, ‘A Poodle known for being calm.’);
insert into dog (id, name, description)
values (93, ‘Duke’, ‘A white German Shepherd known for being friendly.’);
insert into dog (id, name, description)
values (63, ‘Jasper’, ‘A grey Shih Tzu known for being protective.’);
insert into dog (id, name, description)
values (69, ‘Toby’, ‘A grey Doberman known for being playful.’);
insert into dog (id, name, description)
values (101, ‘Nala’, ‘A spotted German Shepherd known for being loyal.’);
insert into dog (id, name, description)
values (61, ‘Penny’, ‘A white Great Dane known for being protective.’);
insert into dog (id, name, description)
values (1, ‘Bella’, ‘A golden Poodle known for being calm.’);
insert into dog (id, name, description)
values (91, ‘Willow’, ‘A brindle Great Dane known for being calm.’);
insert into dog (id, name, description)
values (5, ‘Daisy’, ‘A spotted Poodle known for being affectionate.’);
insert into dog (id, name, description)
values (95, ‘Mia’, ‘A grey Great Dane known for being loyal.’);
insert into dog (id, name, description)
values (71, ‘Molly’, ‘A golden Chihuahua known for being curious.’);
insert into dog (id, name, description)
values (65, ‘Ruby’, ‘A white Great Dane known for being protective.’);
insert into dog (id, name, description)
values (45, ‘Prancer’, ‘A demonic, neurotic, man hating, animal hating, children hating dogs that look like gremlins.’);
(Now’s a good time to remind you that the code for this example is also available online here and you can just copy-and-paste this into your application, too!)
With these changes – the .SQL files, the compose.yml file and application.properties – you’ve got a valid (if empty) application. You can run the application on the command line:
./mvnw spring-boot:run or just run the main class in your IDE.
Jump to the main class of the application, OracleApplication.java. It’s a stock-standard and empty Spring Boot application.
We’re going to be talking to a database – Oracle – to store our dog records. Let’s build a data access layer – an entity and a repository.
interface DogRepository extends ListCrudRepository<Dog, Integer> {}
record Dog(@Id int id, String name, String owner, String description) {}
The first definition provides a convenient data access layer. You can inject a DogRepository into your code and use it to – among other things – find all Dog objects from the dog table.
We’re going to build a simple HTTP endpoint (a Spring MVC controller) that takes requests from the user and then forwards them to the autoconfigured ChatModel through the convenient Spring AI ChatClient.
Here’s our controller. We’ll walk through what it’s doing after the example.
@Controller
@ResponseBody
class DogAssistantController {
private final ChatClient ai;
DogAssistantController(ChatClient.Builder ai, VectorStore vectorStore, ChatMemory chatMemory) {
var systemPrompt = “””
You are an AI powered assistant to help people adopt a dog from the adoption\s
agency named Pooch Palace with locations in Antwerp, Seoul, Tokyo, Singapore, Paris,\s
Mumbai, New Delhi, Barcelona, San Francisco, and London. Information about the dogs available\s
will be presented below. If there is no information, then return a polite response suggesting we\s
don’t have any dogs available.
“””;
var ragAdvisor = new QuestionAnswerAdvisor(vectorStore);
var memoryAdvisor = new PromptChatMemoryAdvisor(chatMemory);
this.ai = ai//
.defaultSystem(systemPrompt) //
.defaultAdvisors(ragAdvisor, memoryAdvisor)//
.build();
}
@GetMapping(“/{user}/inquire”)
String inquire(@PathVariable String user, @RequestParam String question) {
return this.ai.prompt()
.advisors(a -> a.param(AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY, user))
.user(question)
.call()
.content();
}
}
This is a simple Spring MVC controller that exposes one endpoint /{user}/inquire and expects a request parameter called question. In order for it to do its work, it’ll use the Spring AI ChatClient. We build one by injecting the builder into the constructor and then configuring a few interesting defaults on the built instance that will apply to all requests handled with this ChatClient. Keep in mind that it’s trivial to create many different ChatClients in the same applications with different use cases.
The first thing we’ve configured is a system prompt. The system prompt tells the LLM in what manner it should behave; it frames the questions for the LLM and gives it a persona. Here, we’re instructing the LLM that it’s meant to be an assistant at our fictitious dog adoption agency called Pooch Palace.
We’re also configuring a QuestionAnswerAdvisor. The QuestionAnswerAdvisor is an interceptor. It knows to consult the vector database (the configured Oracle Database), and ask it for any data that might be germane to our request which it can then put in the request before sending the request on to the backed LLM. This type, by the way, from an extra dependency that you’ll need to manually add to your pom.xml:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>
Next, we configure a PromptChatMemoryAdvisor. This advisor keeps track of the conversations in which messages exist and then stores them. Why? Well, remember: LLMs are stateless, so you need to remind them of what’s been said by giving them a transcript on each subsequent request. There’s an in-memory variation of this advisor, but we have the amazing Oracle Database at your fingertips – remembering things is what it does! So let’s use the JDBC variant to make our persistence durable. Add the following dependency:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-model-chat-memory-jdbc</artifactId>
</dependency>
You’ll need to wire up two beans:
@Bean
JdbcChatMemoryRepository jdbcChatMemoryRepository(DataSource dataSource) {
return JdbcChatMemoryRepository.builder().jdbcTemplate(new JdbcTemplate(dataSource)).build();
}
@Bean
MessageWindowChatMemory jdbcChatMemory(JdbcChatMemoryRepository chatMemoryRepository) {
return MessageWindowChatMemory.builder().chatMemoryRepository(chatMemoryRepository).build();
}
These beans in turn depend on there being a relational table in the database in which to store your conversations. Add the following to the bottom of schema.sql:
CREATE TABLE if not exists ai_chat_memory
(
conversation_id VARCHAR2(36 CHAR) NOT NULL,
content CLOB NOT NULL,
type VARCHAR2(10 CHAR) NOT NULL,
“timestamp” TIMESTAMP NOT NULL,
CONSTRAINT ai_chat_memory_type_chk CHECK (type IN (‘USER’, ‘ASSISTANT’, ‘SYSTEM’, ‘TOOL’))
);
CREATE INDEX if not exists ai_chat_memory_conversation_id_timestamp_idx
ON ai_chat_memory(conversation_id, “timestamp”)
If you look at the controller method, inquire, you’ll see that we’re specifying the username as the key by which to store the conversation. You won’t accidentally get somebody else’s conversations, and vice versa. This example is a little silly in that the username is arbitrary and comes from the URL’s path variable. It’s a trivial matter to add Spring Security to this application and use the currently authenticated user’s name as the key, instead.
If you run a request right now you’ll get nothing.We’ve got the dogs in the dog table, but there could be trillions of those! We don’t want to send all the data in every LLM request, only those that could potentially match. So we will store them in Oracle Database as a vector type. The QuestionAnswerAdvisor will know to consult this vector data to find conceptually similar data and send only the subselected results from that query along with the question to the model. Here’s how we initialize the vector data:
@Bean
ApplicationRunner dogumentInitializer(JdbcClient db, VectorStore vectorStore, DogRepository repository) {
return args -> repository.findAll().forEach(dog -> {
var dogument = new Document(“id: %s, name: %s, description: %s”.formatted(
dog.id(), dog.name(), dog.description()
));
vectorStore.add(List.of(dogument));
});
}
This definition registers an object, an instance of ApplicationRunner, that Spring Boot will invoke when the application starts up. In it, we inject the DogRepository and VectorStore, looping through all the dogs in the database and then transforming them into Spring AIDocument objects. There’s no schema here, as such. Whatever you put in the string, just make sure it’s consistent from one document to another.
Relaunch the application and let’s try it all out, together! We’re using the http CLI. You can translate to curl or whatever other HTTP client you like.
http –form POST :8080/jlong/inquire question==”do you have any neurotic dogs?”
On one run, we got the following response:
Yes, we have a neurotic dog available for adoption. Meet Prancer, a demonic, neurotic dog who has a bit of a temperament issue—he tends to be man-hating, animal-hating, and children-hating, and he looks like a gremlin. If you’re interested, please let me know!
(Your response will probably vary.)
It worked! We’ve got a convenient, natural language assistant to help people match with the Prancers of their dreams!
There’s so much more you could do from here. You could use Spring AI’s tool calling support to let the LLM invoke business logic in your code and schedule a time to pickup the dog.
You could centralize that business logic and export it for consumption via the MCP protocol.
You could turn the whole thing into an agentic, giving it goals and letting the output of LLMs drive the execution of the code.
Truly the possibilities are endless!
Production worthy AI
Now, it’s time to turn our eyes toward production.
Security
It’s trivial to use Spring Security to lock down this web application. You could use the authenticated Principal#getName` to use as the conversation ID too. What about the data stored in the database, like the conversations? Well, you have a few options here. Oracle Database supports encryption at rest. In Oracle Database, this feature is called TDE (transparent data encryption). Basically, as you read or write values, it’s stored securely on disk. No changes required to the code for this.
Scalability
We want this code to be scalable. Remember, each time you make an HTTP request to an LLM (or many relational databases), you’re doing blocking IO. IO that sits on a thread and makes that thread available to any other demand in the system until the IO has completed. This is a waste of a perfectly good thread. Threads aren’t meant to just sit idle, waiting. Java 21 gives us virtual threads, which – for sufficiently IO bound services – can dramatically improve scalability. That’s why set up spring.threads.virtual.enabled=true in the application.properties file.
GraalVM Native Images
GraalVM is an AOT compiler, led by Oracle, that you can consume through the GraalVM Community Edition open source project or through the very powerful (and free) Oracle GraalVM distribution.
If you’ve got that setup as your SDK, you can turn this Spring AI application into an operating system and architecture specific native image with ease:
./mvnw -DskipTests -Pnative native:compile
This takes a minute or so on most machines but once it’s done, you can run the binary with ease.
./target/oracle
This program will start up in a fraction of the time that it did on the JVM. You might want to comment on the ApplicationRunner we created earlier since it’s going to do IO on startup time, significantly delaying that startup. On my machine it starts up in less than a tenth of a second.
Even better, you should observe that the application takes a very small fraction of the RAM it would’ve otherwise taken on the JVM.
That’s all very well and good, you might day, but I need to get this running on my cloud platform (Oracle Cloud, natch) and that means getting it into the shape of a Docker image. Easy!
./mvnw -DskipTests -Pnative spring-boot:build-image
Stand back. This might take another minute still. When it finishes, you’ll see its printed out the name of the Docker image that’s been generated.
You can run it, remembering to override the hosts and ports of things it would’ve referenced on your host.
docker run -e SPRING_AI_OPENAI_API_KEY=$SPRING_AI_OPENAI_API_KEY \
-e SPRING_DATASOURCE_URL=jdbc:oracle:thin:@host.docker.internal:1521/FREEPDB1 docker.io/library/oracle:0.0.1-SNAPSHOT
Vroom!
We’re on macOS, and amazingly, this application when run in a macOS virtual machine emulating Linux, runs even faster – and right from the jump, too! – than it would’ve on macOS directly! Amazing!
Observability
This application’s so darn good I’ll bet it’ll make headlines, just like Prancer, in no time. And when that happens, you’d be well advised to keep an eye on your system resources and – importantly – the token count. All requests to an LLM have a cost – at least one of complexity, if not dollars and cents. Thankfully, Spring AI has your back. Launch a few requests to the model, and then up the SPring Boot Actuator metrics endpoint (powered by Micrometer.io): http://localhost:8080/actuator/metrics and you’ll see some metrics related to token consumption. Nice! You can use Micrometer to forward those metrics to your time-series database of choice to get a single pane of glass, a dashboard.
Oracle Cloud (OCI)
You’ve got as smart, scalable, and efficient a program as possible, but where should you run it? Oracle Cloud (OCI) is a fine choice! Oracle OCI stands for Oracle Cloud Infrastructure. It’s Oracle’s cloud computing platform — similar to AWS, Azure, or Google Cloud — offering infrastructure and platform services to run applications, store data, and build cloud-native solutions. There are tons of ways you could run your new-fangled Docker image there. OCI offers compute instances for both Intel and ARM architectures. You can get started easily by signing up for the Always Free Tier which will give you access to compute instances, Oracle Autonomous Database, a load balancer, and a few other resources for free.
Oracle Autonomous Database
And if you thought OCI was a nice way to run your Spring Boot application, you’d better believe they do the best job running Oracle the database itself! https://www.oracle.com/autonomous-database/ Oracle Autonomous Database is the Oracle Database we’ve just looked at, fully managed for you. All the upside, and none of the administrative downside. And if that wasn’t enough you can also run it on Microsoft Azure, Google Cloud Platform, and yes, even on Amazon Web Services (AWS).
Next Steps
You’ve just built a production-worthy, AI-ready Spring AI and Oracle Database powered application in no time at all. We’ve only begun to scratch the surface! Check out Spring Ai 1.0 at the Spring Initializr today and learn more about Oracle Database and the vector support here!
Resources
- Link to the Spring AI 1.0 blog
- Josh’s Youtube channel https://youtube.com/@coffeesoftware
- The code https://github.com/joshlong-attic/2025-05-01-spring-ai-oracle-vector
- Oracle Autonomous Database https://www.oracle.com/autonomous-database
- Oracle Database 23ai Free https://www.oracle.com/database/free
