Recently, Oracle introduced Oracle AI Agent Memory Python package, a model and framework-agnostic memory solution that gives enterprise AI teams a governed memory core on Oracle AI Database: short-term threads with summaries and context cards, long-term durable memories with vector search, automatic LLM-based memory extraction, and the governance and isolation production agents require.
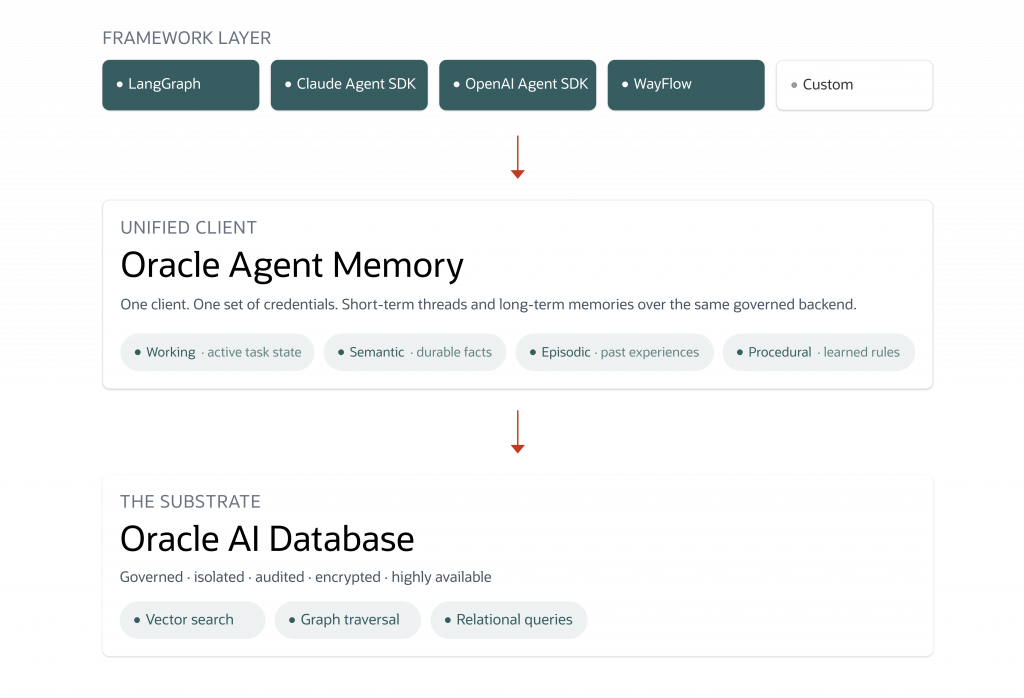
Oracle AI Agent Memory is available now via PyPI as oracleagentmemory and documented in the Oracle Help Center. It is designed to replace the patchwork memory stack most production agents inherit with a single governed memory substrate built on Oracle AI Database.
This is the difference between an agent that is memory-augmented, given a vector store to consult, and one that is memory-aware, responsible for reading from and writing to its own governed, durable state with one enterprise-grade backend.
“Agent memory has shifted from a research curiosity to a production requirement in under two years. Teams shipping serious agentic systems need a backend that handles vectors, structured data, and transactional consistency in one place, not three stitched together. Oracle AI Database is one of the few platforms that delivers all of that natively, which is why we built Hindsight to run on it as a first-class backend.”
— Chris Latimer, Co-Founder & CEO of Vectorize
Why Agent Memory, Why Now

Most agent implementations treat memory as a bolt-on. A vector store consulted at retrieval time, a chat history table glued on beside it, and whatever hand-written extraction logic the team can maintain.
That stack holds together for a demo. It falls apart from the moment an enterprise AI team asks questions that actually matter. Who owns the memory? Where is it governed? How do we isolate tenants? How do we audit what the agent learned, and how do we forget it on request?
Context windows have grown over the years, but no context window is large enough to hold the full state of a long-running agent: weeks of user preferences, accumulated domain knowledge, prior tool outcomes, evolving task state, and the reasoning history that makes each decision defensible.
Agents need memory for the same reasons people do: to hold an active state while working on a problem, to retain facts learned over time, to recall specific past experiences, and to encode behavioral rules and procedures.
A practical taxonomy for agent memory commonly used in agent design covers four types:
- Working memory is the active state the agent is reasoning over right now, the running conversation and the scratchpad the model sees at inference time.
- Semantic memory is the durable facts and knowledge the agent accumulates about users, entities, and the world: preferences, canonical definitions, structured reference data.
- Episodic memory is specific past experiences the agent can recall, what happened on a prior session, what the user asked three weeks ago, how a similar task resolved last time.
- Procedural memory is the behavioral rules, guidelines, and learned procedures that shape how the agent acts, how to handle customers, which tools to prefer, what not to do.
These are not four different systems. They are four access patterns over the same underlying state, which is what makes a unified memory core the right architectural answer rather than four bolted-together services.
Oracle AI Database as the Memory Core
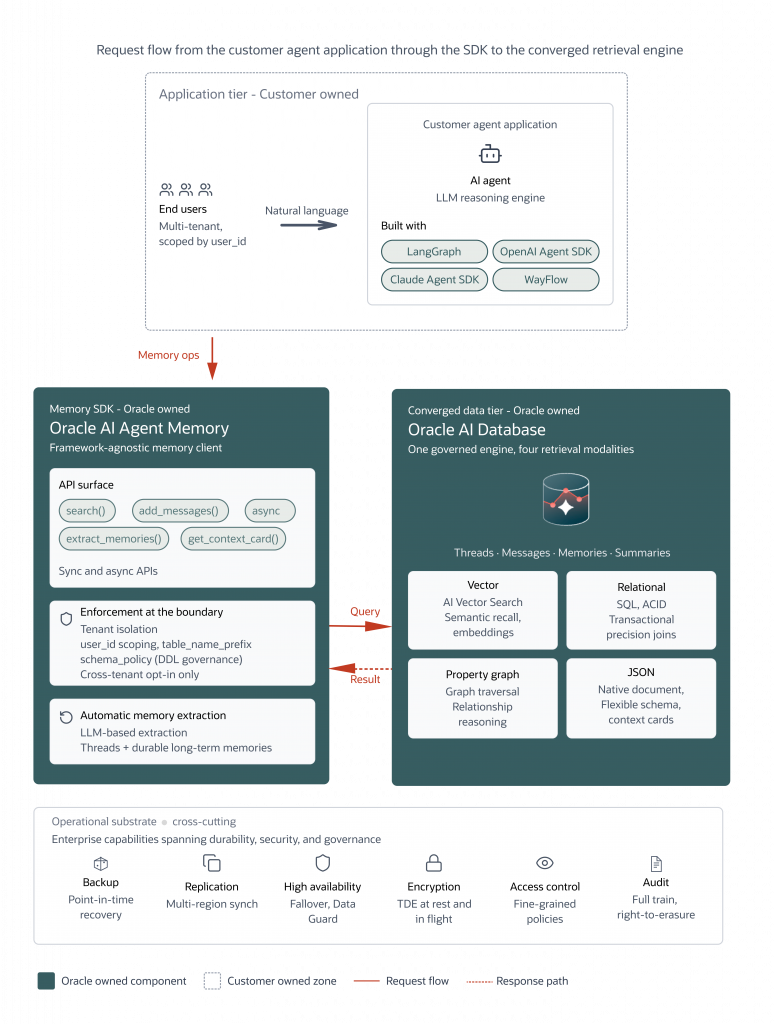
Oracle AI Database combines vector similarity search, relational querying, and graph-aware data access in one governed engine, enabling semantic recall alongside precise transactional and relationship-centric retrieval. Combined with Oracle’s operational story, backups, replication, high availability, encryption, fine-grained access control, and audit, teams get a path from notebook to regulated production without swapping storage layers, rewriting compliance reviews, or stitching together bespoke isolation logic along the way.
Memory engineering, as a discipline, demands substrate choices that hold up under the access patterns a real enterprise agent actually has concurrent writes, per-user and per-tenant scoping, full audit, and semantic retrieval at scale.
“Enterprise agents need an agent memory solution with robust security guarantees, strong governance controls, sophisticated workload isolation, as well as deep integration within the enterprise data platform. Oracle AI Agent Memory greatly simplifies building agent memory solutions by consolidating what are usually multiple separate and fragmented services, within the converged database architecture that customers already trust for their most critical data.”
— Tirthankar Lahiri SVP, Mission-Critical Data and AI Engines, Oracle Database
Production agent memory carries two loads. Developers wire the stack together: vector store, chat log, extraction scripts, isolation logic, governance per piece. Agents reason over the fragments, deciding what to retrieve from where and fitting the relevant world into a finite context window each turn.
Oracle AI Agent Memory lifts both. One governed client replaces the four-service stack, with one set of credentials, one compliance review, and one backup story. Working, semantic, episodic, and procedural memory share one substrate and one retrieval surface, so the model reasons over a coherent view of its state. Summarisation and scoped retrieval put the right subset into context at the right moment, freeing the model to spend its reasoning budget on the task rather than memory bookkeeping.
Automatic LLM-based extraction turns conversation into durable memories without hand-rolled prompt chains. Multi-tenant isolation is enforced at the store layer, so a single schema can host multiple deployments without cross-tenant leakage. And because the SDK is framework-agnostic, integrating with LangGraph, Claude Agent SDK, OpenAI Agent SDK, WayFlow, and custom harnesses, teams aren’t locked into a single runtime to get the substrate.
Key Benefits For AI Workloads
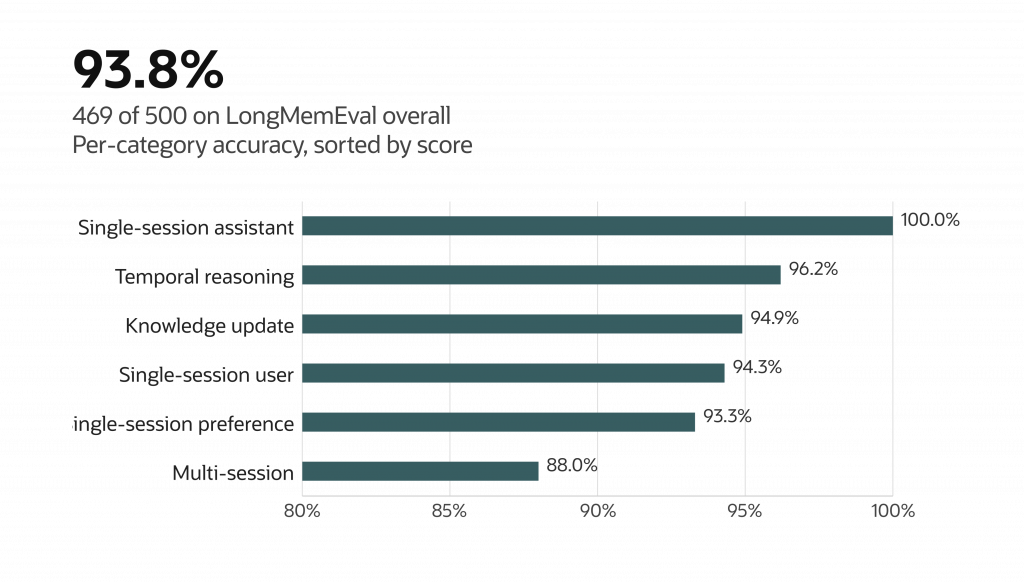
Configuration · gpt-5.5 (reasoning effort xhigh) · nomic-embed-v1.5 embeddings
Local HNSW index · top-K = 200
X-axis truncated; all categories scored above 88%.
Oracle AI Agent Memory is built for the operational realities of running AI agents in production.
Production-grade recall on long-horizon memory benchmarks. On LongMemEval, the standard academic benchmark for long-context agent memory, Oracle AI Agent Memory scores 93.8% (469 of 500), with the strongest results on the categories that matter most for production agents: 100% on single-session assistant recall, 96% on temporal reasoning, and 95% on knowledge-update tasks. Multi-session recall, the hardest category in the benchmark, lands at 88%. Configuration: OpenAI gpt-5.5 (reasoning effort xhigh), nomic-embed-text-v1.5 embeddings, local HNSW index, top-K = 200.
Bounded per-turn cost as sessions extend. Periodic thread summarization, durable memory extraction, and prompt-time message compaction keep the working context bounded as conversations grow. In an 80-turn scripted conversation, Oracle AI Agent Memory held per-request input around 1,300 tokens for the full run while a flat-history baseline grew linearly past 13,900 — roughly 9.5× more tokens per request by the final turn, and a much steeper bill across the full conversation. Teams shipping long-running agents trade a linear-in-history cost curve for a flat one.
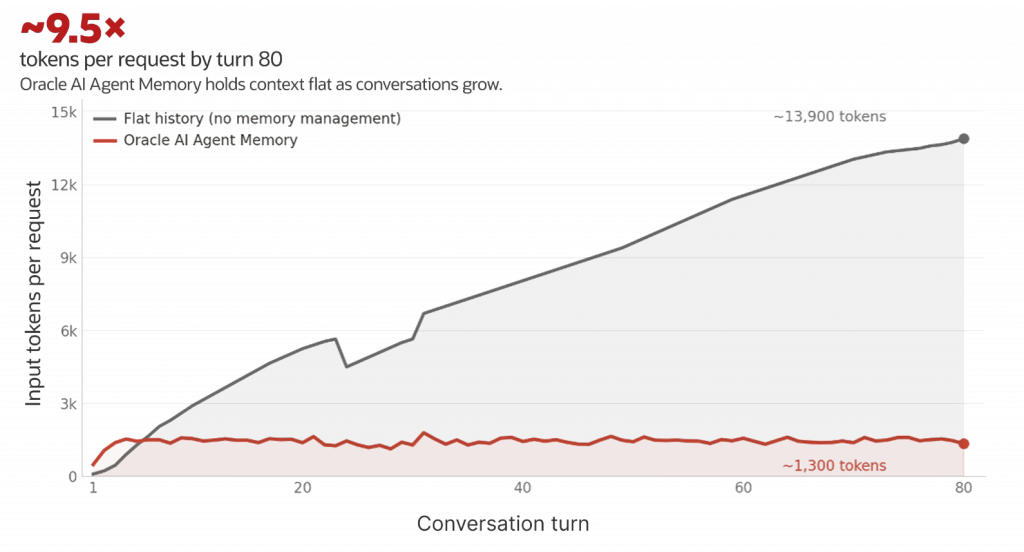
80-turn ChromAtlas-ND scripted conversation · gpt-5.4 (raw OpenAI client, no framework).
Token estimate: chars / 4 (notebook convention)
Better answers than a flat-history baseline. A flat-history agent has the entire verbatim conversation in its prompt — every fact ever mentioned, in order. By rights it should be hard to beat on recall. Across the same 80-turn conversation, evaluated by an impartial gpt-5.4 judge on accuracy, completeness, relevance, and coherence, Oracle AI Agent Memory won 48 turns to flat history’s 13, with 19 ties: 3.7× more wins despite the baseline’s information advantage. A retrieved context card focuses the model on what matters; a sprawling transcript dilutes attention across noise.
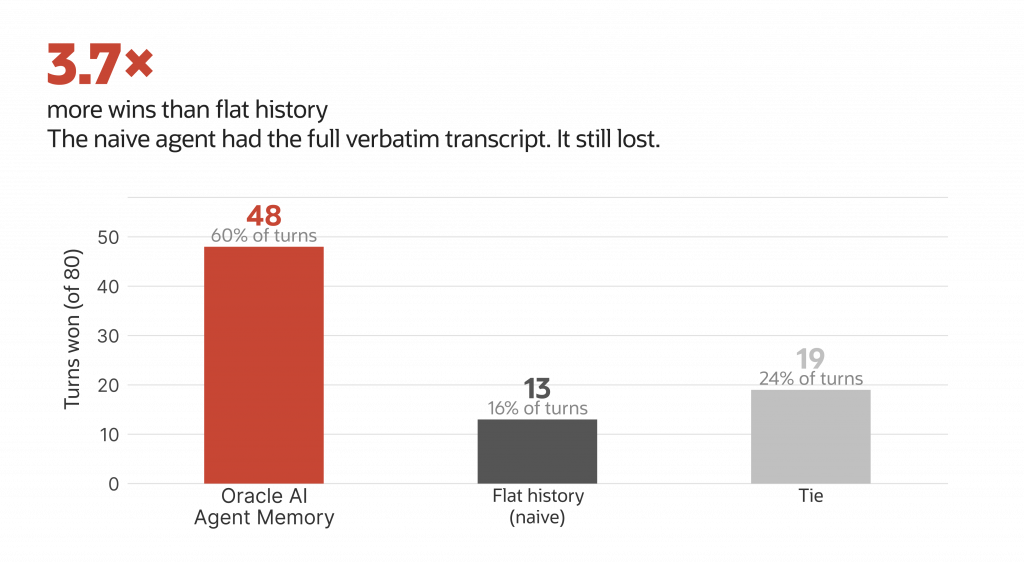
80-turn ChromAtlas-ND scripted conversation · judge: gpt-5.4
scored on accuracy, completeness, relevance, coherence
Cost is a tunable knob, not a fixed value. The summarization trigger controls how aggressively the package compacts thread context, and it moves the cost-fidelity trade-off directly. In an 8-query demo conversation (five runs per threshold), a 10,000-token trigger landed at a mean of 121,268 total tokens, about 60% under the 306,823-token flat-history baseline. As the trigger rises, the package compacts less often and preserves more raw context per turn; by a 50–70k trigger, mean total tokens approach or exceed the baseline, and run-to-run variance widens. Teams pick the threshold that matches their answer-quality requirements and lock in the cost envelope they want, rather than accepting whatever curve a fragmented stack produces.
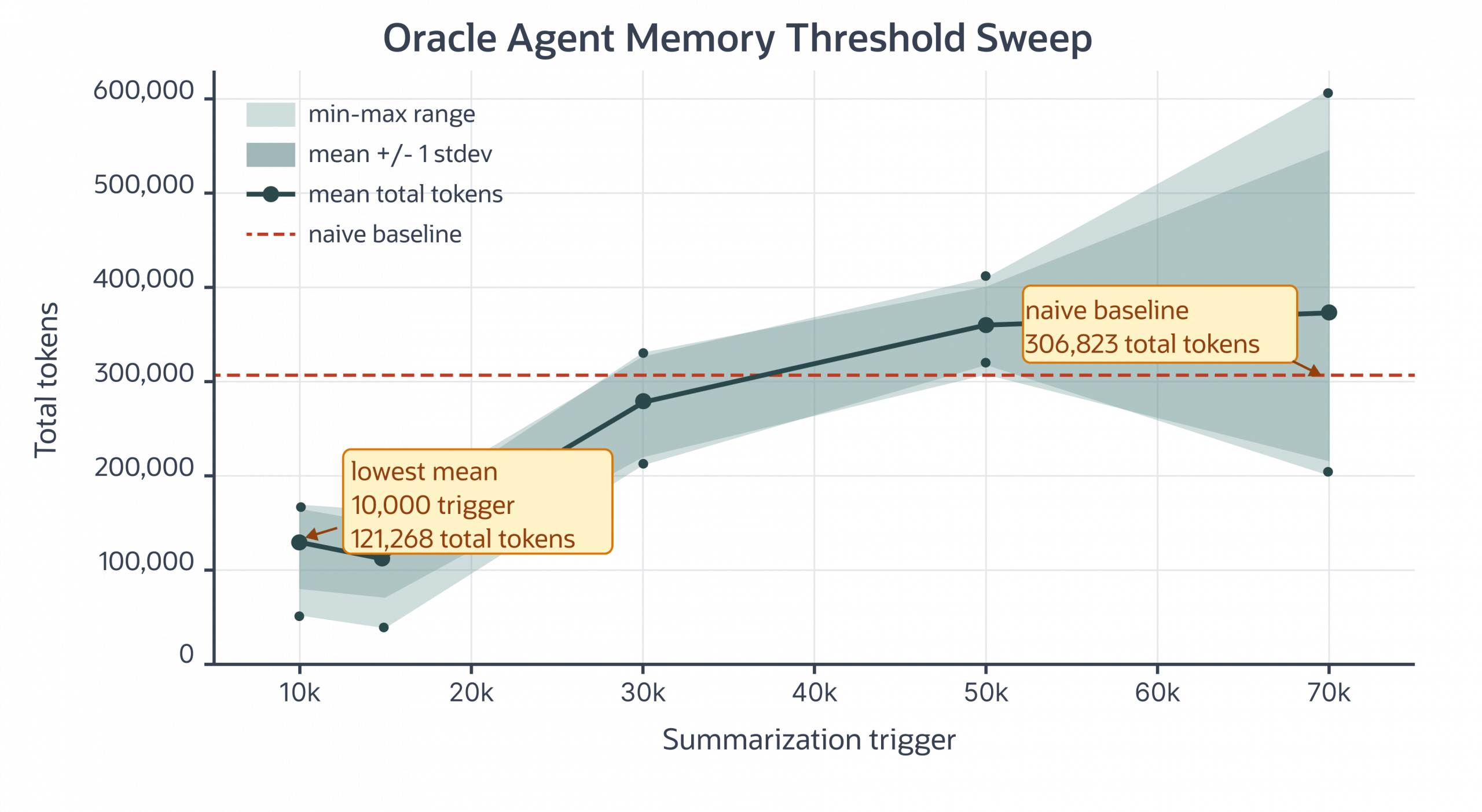
Memory Agent Efficiency vs Summarization Threshold on Demo Conversation
(Num Queries = 8, Num Runs Per Threshold = 5)
One backend, every Python runtime. LangGraph, the Claude Agent SDK, the OpenAI Agents SDK, WayFlow, and custom Python harnesses all instantiate the same OracleAgentMemory client and read and write the same Oracle Database store. Teams running more than one framework no longer rebuild memory per runtime, and migrations between frameworks no longer mean migrating memory.
Primitives for audit and erasure on a single substrate. Every record carries user, agent, thread, and timestamp scoping fields, and the SDK exposes search, list, and per-record delete operations across memories, threads, and messages, so callers can locate records for a subject and remove them on request. Oracle Database’s native auditing covers the storage layer underneath. Compliance reviews land on a single substrate (one database with audit, retention, and access controls already in the data plane) rather than four services with four reviews.
One vendor relationship for production agent memory. A single Oracle AI Database instance carries vector search, structured state, JSON document retrieval, transactional consistency, and database-native audit. No second vector database to license, no third service to monitor and scale, no fourth backup pipeline to maintain.
Who Oracle AI Agent Memory Is For
Oracle AI Agent Memory is designed for:
- AI Developers and engineers building production agents who need durable short-term and long-term memory in one place, with enterprise security and isolation.
- Teams already running Oracle AI Database who want their agents to write to the same governed backend as the rest of the business
- Technical leaders evaluating Oracle AI Database for agent memory infrastructure at scale, with compliance and audit requirements
Getting Started
Install the Oracle AI Agent Memory package:
pip install oracleagentmemory A minimal end-to-end loop in Python looks like this:
from oracleagentmemory import AgentMemory
memory = AgentMemory.from_connection(
connection_string="...",
user_id="user_123",
)
# Add conversation turns to a short-term thread
thread_id = memory.create_thread(user_id="user_123")
memory.add_messages(thread_id, messages=[
{"role": "user", "content": "I prefer vegan meals."},
{"role": "assistant", "content": "Noted."},
])
# Extract durable long-term memories from the thread
memory.extract_memories(thread_id)
# Scoped search over long-term memory, enforced per-user
results = memory.search(
user_id="user_123",
query="dietary preferences",
limit=5,
) Code samples are illustrative; the final API surface is documented in the Oracle Help Center.
Documentation, the quickstart notebook, how-to guides for each framework integration, and the full API reference are all available in the Oracle Help Center.
Oracle AI Agent Memory is the first release of a broader commitment to a governed memory substrate enterprise agents. Memory engineering is still an emerging discipline. The infrastructure behind it should not be.