In this blog, we will see how caching plays a vital role in building efficient Generative AI applications. Understand about caching strategies that speed up response times, reduce computational costs and improve scalability.
Every repeated prompt sent to a Generative AI model is an opportunity to save time and resources. With smart caching, you can reduce latency, lower operating costs and deliver a better user experience with minimal overhead.
Why Caching Makes a Difference
- Cuts down on redundant compute
- Reduces latency
- Scales with ease
- Improves reliability
Essential Generative AI Caching Techniques
- Exact Cache: Store complete prompt-response pairs. Returns cached results if the prompt matches.
- Prompt Cache: Cache common segments in prompts, like context or system messages, so only new information needs processing.
- Semantic Cache: Use embeddings to match similar queries and reuse answers for questions with the same meaning.
Simple Exact Cache Example (Python)
import hashlib
import json
import os
CACHE_FILE = “prompt_cache.json”
def hash_prompt(prompt):
return hashlib.sha256(prompt.encode()).hexdigest()
def load_cache():
if os.path.exists(CACHE_FILE):
with open(CACHE_FILE) as f:
return json.load(f)
return {}
def save_cache(cache):
with open(CACHE_FILE, “w”) as f:
json.dump(cache, f)
def get_from_cache_or_generate(prompt):
cache = load_cache()
key = hash_prompt(prompt)
if key in cache:
return cache[key], True
# Placeholder for GenAI API call
response = “<generated response>”
cache[key] = response
save_cache(cache)
return response, False
Demo: Measuring Caching Performance
A toy Streamlit app can make caching effects clear and visible. Here’s how:
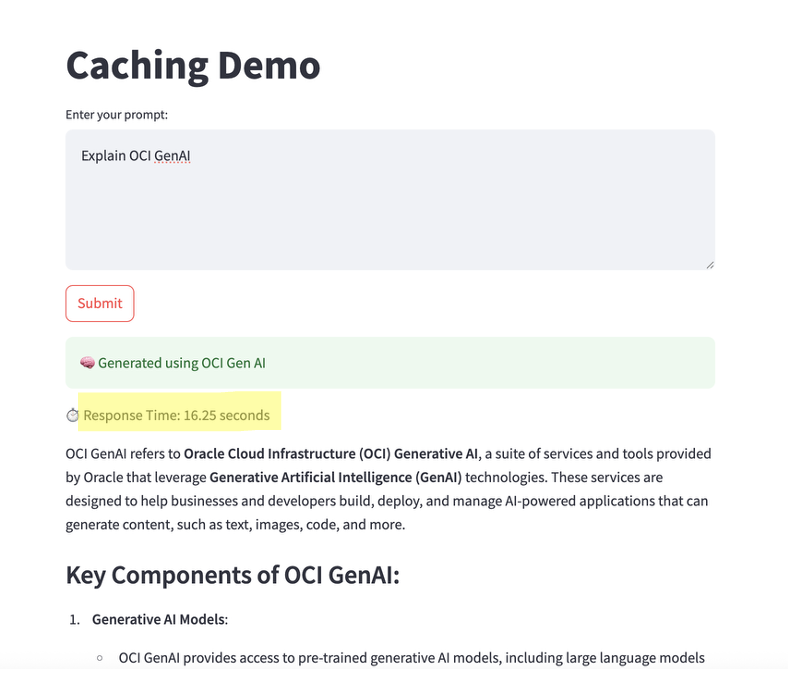
Cache Miss (first request):
- App triggers GenAI API call
- Response time: a few seconds
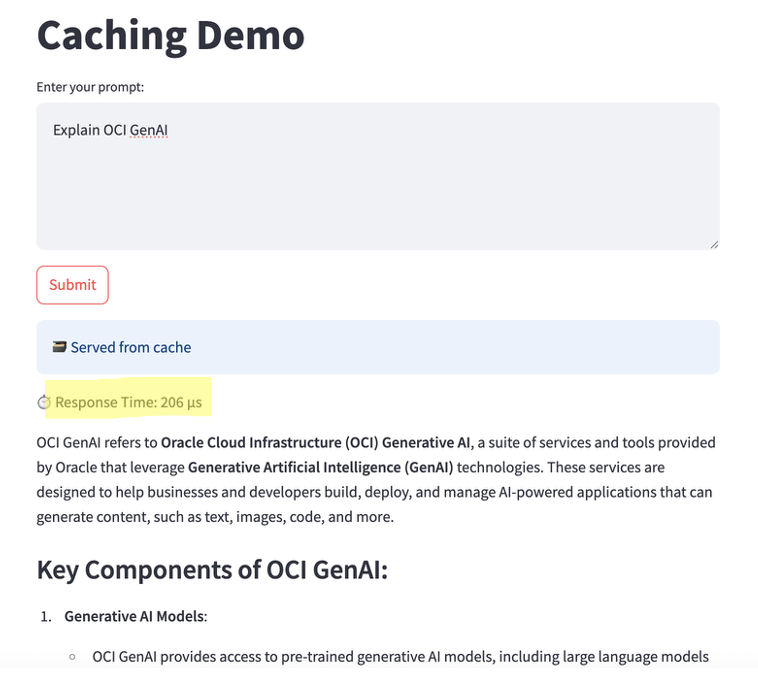
Cache Hit (repeat request):
- Response delivered from cache
- Response time: microseconds
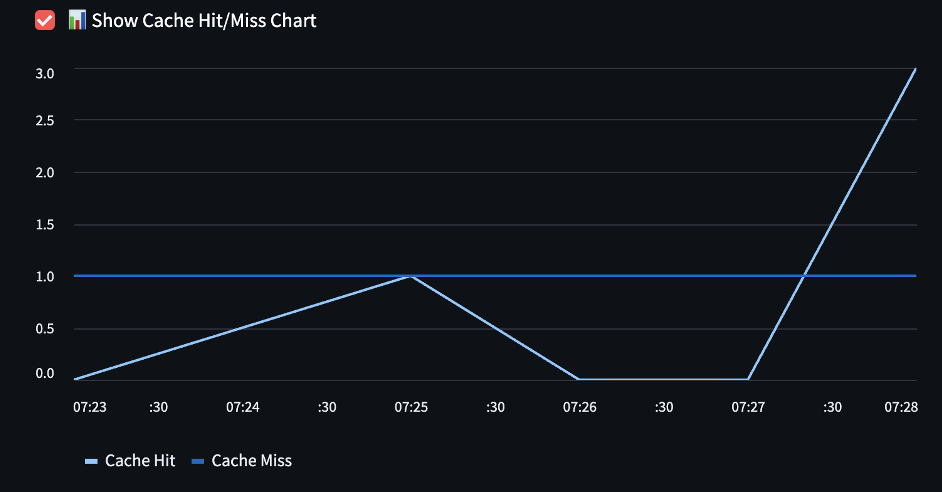
Cache Usage Chart:
Track cache hits and misses over time with charts and watch hits increase as cache fills
Best Practices
- Move to distributed or in-memory caching for larger scales.
- Use semantic caching for apps with varied user phrasing.
- Choose what to cache- avoid personalized or time-sensitive data
Closing Thoughts
Caching accelerates GenAI development by reducing compute load and speeding iterations, while helping businesses deliver faster, seamless user experiences. It is a key enabler of scalable, efficient and competitive AI solution.
