Key Takeaways
- The demo keeps semantic caching small enough to inspect. It uses Spring Boot, JDBC, Oracle AI Database 26ai Free, Oracle True Cache, deterministic fixture vectors, and a small Java cache service so the database behavior is visible.
- Vector search proposes one candidate; policy decides whether it can be reused. The demo checks tenant, chat model, embedding model, embedding dimension, prompt template, source fingerprint, policy version, status, TTL, and a cosine-distance threshold before returning a cached answer.
- Oracle True Cache is validated as a read route, not as the semantic engine. Exact and semantic lookup SQL can run through the True Cache service, while cache inserts and event writes go to the primary Oracle AI Database route.
- The benchmark-lite report is wiring evidence, not a performance benchmark. It confirms that the validation workload records decisions, routes, provider calls, distances, thresholds, and latency fields; it does not claim production latency, cost, or scalability results.
Article 1 defined semantic caching as governed answer reuse. This article turns that architecture into a runnable demo.
The point of the demo is not to hide the policy behind a framework abstraction. It is to make the important boundaries visible: what gets stored, what SQL runs, which route handles reads, which route handles writes, when a candidate becomes a hit, and when the provider must still be called.
That means the implementation is deliberately more direct than a production Spring AI application. The sample app is a Spring Boot command-line application. It creates two Oracle JDBC data sources in Java, constructs a SemanticCacheService, and runs eight deterministic ecommerce-returns scenarios. The vectors are fixed fixture vectors supplied by the scenarios, not embeddings generated from prompt text by OpenAI, OCI Generative AI, or a Spring AI embedding model.
That is a useful tradeoff for this article. We can validate Oracle AI Database vector storage, VECTOR_DISTANCE(), policy predicates, Oracle True Cache routing, miss behavior, near-miss rejection, and event reporting without adding provider variability.
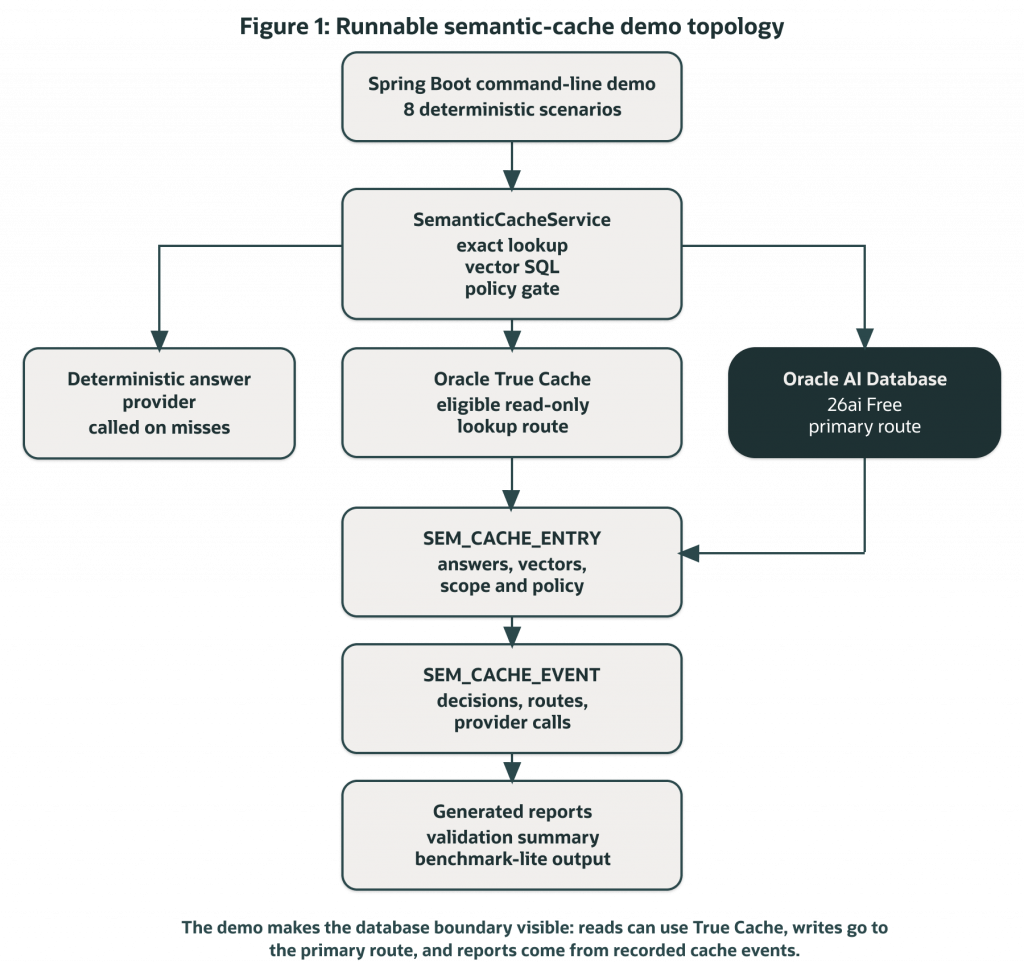
Figure 1. The demo keeps the cache service, Oracle AI Database primary route, Oracle True Cache read route, cache tables, event table, deterministic provider, and generated reports visible.
What the Demo Contains
The public demo code is available at:
https://github.com/markxnelson/semantic-cache-oracle-demo
The important files are:
semantic-cache-oracle-demo/
docker-compose.yml
.env.example
app/
src/main/java/com/example/semcache/app/SemanticCacheDemoApplication.java
oracle-semantic-cache/
src/main/java/com/example/semcache/oracle/AnswerProvider.java
src/main/java/com/example/semcache/oracle/SemanticCacheRequest.java
src/main/java/com/example/semcache/oracle/SemanticCacheResponse.java
src/main/java/com/example/semcache/oracle/SemanticCacheService.java
db/
init/
001-create-app-user.sql
010-semantic-cache-schema.sql
scripts/
start-databases.sh
wait-for-oracle.sh
run-validation.sh
run-benchmark-lite.sh
reports/
generated/
This article keeps the Java application intentionally narrow. The Spring Boot app is a command-line validation harness around the Oracle semantic-cache service, not a full chatbot server. It does not include Spring AI starter dependencies, provider profiles, REST controllers, or a separate RAG schema.
The demo is still useful because it validates the Oracle-backed semantic-cache core that a Spring AI application could call from its own prompt flow.
Understand the Java Application
The Java application has two small layers.
app/ contains SemanticCacheDemoApplication, the Spring Boot entry point. It implements CommandLineRunner, so running the jar executes the demo once and exits. That runner reads environment variables, creates the Oracle JDBC connections, constructs the cache service, runs the fixture scenarios, writes reports, and fails the process if any scenario returns the wrong decision.
oracle-semantic-cache/ contains the reusable cache code. SemanticCacheService owns the lookup and write logic. SemanticCacheRequest carries the prompt, scope fields, fixture embedding, and distance threshold. SemanticCacheResponse carries the decision that ends up in the reports.
The entry point is deliberately easy to follow:
DataSource primary = oracleDataSource(
env("PRIMARY_JDBC_URL", "jdbc:oracle:thin:@//localhost:1521/FREEPDB1"),
user,
password);
DataSource read = oracleDataSource(
env("TRUE_CACHE_JDBC_URL", env("PRIMARY_JDBC_URL", "jdbc:oracle:thin:@//localhost:1521/FREEPDB1")),
user,
password);
SemanticCacheService cache =
new SemanticCacheService(primary, read, readRouteName, deterministicProvider());
The runner then resets the demo tables, seeds one expired entry, and executes eight requests. The first request creates the initial cache entry. The next two prove exact and semantic reuse. The remaining scenarios prove that near misses, tenant differences, model differences, source changes, and expired entries do not reuse the old answer.
Each request is explicit. For example, the semantic-hit request uses the same tenant and policy scope as the seed request, but a slightly different prompt and a nearby fixture vector:
responses.add(cache.answer(request(
"semantic-hit",
"store-a",
"What is the return window for shoes I have not worn?",
vector(0.101, 0.199, 0.302, 0.398),
threshold)));
The demo does not ask a model to create that embedding. The vector is part of the fixture so the result is repeatable. That makes the database behavior easier to inspect: if a scenario fails, the problem is in the cache policy, route setup, SQL, or report generation.
Start with the Database Boundary
The Docker Compose topology starts a primary Oracle AI Database 26ai Free container and an Oracle True Cache container. Bring that stack up before reading the database evidence:
git clone https://github.com/markxnelson/semantic-cache-oracle-demo.git
cd semantic-cache-oracle-demo
cp .env.example .env
# Review .env and update any ports, passwords, or image names needed for your machine.
./scripts/start-databases.sh
./scripts/wait-for-oracle.sh
start-databases.sh starts the primary database first, copies the generated primary password file needed by True Cache, starts the True Cache container, and registers the True Cache services from the primary database. wait-for-oracle.sh then waits until both the primary PDB service and the registered True Cache PDB service can answer a simple SQL query as the application user.
When the services are ready, the script prints output like this:
primary database: ready
true cache: ready
app schema: SEMCACHE_APP
Now run the validation script:
./scripts/run-validation.sh
That command checks that both the primary database and the registered True Cache PDB service can accept the application login, builds the sample application, runs the deterministic validation workload, and writes the evidence files under reports/generated/. If the readiness check cannot see semcache_pdb_tc, rerun ./scripts/start-databases.sh so the script can repair and register the demo True Cache services before validation.
The validation script now prints what it is doing as it goes. The start of a healthy run looks like this:
== Semantic cache validation wrapper ==
This validates Oracle primary plus True Cache readiness, then runs deterministic semantic-cache scenarios.
The Java app prints scenario-level decision, route, provider calls, distance, and threshold details.
Generated reports are written under reports/generated/.
Checking primary database and registered True Cache application login readiness...
Waiting for primary Oracle AI Database 26ai Free service...
primary database: ready
Waiting for Oracle True Cache lookup service...
true cache: ready
app schema: SEMCACHE_APP
Building the Spring Boot validation app...
Running deterministic semantic-cache scenarios...
Then the Java app prints each scenario. Here are three representative entries from the current validation run:
Scenario 1/8: seed-miss
Prompt: How long do I have to return unopened shoes?
Scope: tenant=store-a chat_model=gpt-4o-mini embedding_model=text-embedding-3-small source=returns-policy-2026-01
Result: decision=miss route=primary provider_calls=1 distance=n/a threshold=0.1
Why it matters: First request seeds the cache through the provider because no reusable entry exists.
Scenario 2/8: exact-hit
Prompt: How long do I have to return unopened shoes?
Scope: tenant=store-a chat_model=gpt-4o-mini embedding_model=text-embedding-3-small source=returns-policy-2026-01
Result: decision=exact-hit route=true-cache provider_calls=0 distance=n/a threshold=0.1
Why it matters: Exact reuse returns the cached answer without a provider call.
Scenario 3/8: semantic-hit
Prompt: What is the return window for shoes I have not worn?
Scope: tenant=store-a chat_model=gpt-4o-mini embedding_model=text-embedding-3-small source=returns-policy-2026-01
Result: decision=semantic-hit route=true-cache provider_calls=0 distance=0.000016 threshold=0.1
Why it matters: Safe paraphrase reuse stays within the distance threshold and avoids a provider call.
At the end, the script prints the validation result and the generated report paths:
== Validation summary ==
Status: passed | scenarios=8 | failures=0
Provider calls made: 6
Provider calls avoided by approved exact/semantic reuse: 2
Generated reports:
- reports/generated/validation-events.csv
- reports/generated/validation-summary.json
- reports/generated/validation-summary.md
The database-boundary checks in this section come from reports/generated/validation-evidence.md, which the validation script creates every time it runs:
reports/generated/validation-evidence.md
reports/generated/validation-events.csv
reports/generated/validation-summary.json
reports/generated/validation-summary.md
The evidence file records the service names that the rest of the article uses:
Primary PDB service: FREEPDB1
Registered True Cache PDB service: semcache_pdb_tc
It also records that the primary database is running with archive logging and force logging enabled. That output comes from this query against the primary database service:
select log_mode, force_logging from v$database;
LOG_MODE FORCE_LOGGING
------------ ---------------------------------------
ARCHIVELOG YES
The True Cache check comes from the same query shape against the True Cache container after service registration:
select open_mode, database_role from v$database;
That query returns the expected read-only True Cache role:
OPEN_MODE DATABASE_ROLE
-------------------- ----------------
READ ONLY WITH APPLY TRUE CACHE
That matters because True Cache is only useful in this pattern if the demo proves two separate facts:
- The application schema and cache tables exist through the primary database route.
- Eligible read-only lookup SQL can run through the registered True Cache service.
The validation run includes both. It shows SEM_CACHE_ENTRY and SEM_CACHE_EVENT through the primary database and through the registered True Cache service. It also runs a VECTOR_DISTANCE() expression through the True Cache route and gets a distance of 0 for identical vectors.
Store Cache Entries as Governed Rows
The schema creates a dedicated application user and two semantic-cache tables:
SEM_CACHE_ENTRY
SEM_CACHE_EVENT
SEM_CACHE_ENTRY is the answer store. It contains prompt text, a prompt hash, a native vector column, the generated answer, scope metadata, policy metadata, status, and expiration time. The vector column is fixed for this demo:
prompt_embedding VECTOR(4, FLOAT32) NOT NULL
That fixed dimension is intentional. The scenario code supplies four-dimensional fixture vectors so the validation path is deterministic. A production implementation that uses real embedding models would choose a dimension compatible with the selected embedding model and would need a migration and validation strategy when that model changes.
The table also stores the fields that make reuse safe:
tenant_id
chat_model
embedding_model
embedding_dimension
prompt_template_version
source_fingerprint
policy_version
status
expires_at
SEM_CACHE_EVENT records the outcome for each scenario:
scenario_name
route_name
decision
reason
distance
threshold
provider_calls
latency_ms
That event table is what lets the demo show why a request became an exact hit, semantic hit, near miss, or miss.
Build the Cache Service Around Two Routes
The two data sources passed into SemanticCacheService give the demo its read/write boundary:
SemanticCacheService cache =
new SemanticCacheService(primary, read, readRouteName, deterministicProvider());
The primary data source is used for reset, inserts, and event writes. The read data source is used for exact and semantic lookup. In a normal validation run, TRUE_CACHE_JDBC_URL points at the registered True Cache service. For debugging Java code, you can temporarily point the read URL at the primary service, but that does not validate the True Cache path.
This direct wiring is less abstract than a production Spring configuration, and that is the point. The article can show the route behavior without implying Spring bean definitions that are not in the repository.
Run Exact Lookup Before Vector Lookup
SemanticCacheService.answer() starts by hashing the prompt and running an exact lookup on the read connection:
SELECT answer_text
FROM sem_cache_entry
WHERE tenant_id = ?
AND prompt_hash = ?
AND chat_model = ?
AND embedding_model = ?
AND embedding_dimension = ?
AND prompt_template_version = ?
AND source_fingerprint = ?
AND policy_version = ?
AND status = 'ACTIVE'
AND expires_at > SYSTIMESTAMP
FETCH FIRST 1 ROW ONLY
An exact prompt hash is still not enough. The SQL requires the same tenant, chat model, embedding model, embedding dimension, prompt template, source fingerprint, policy version, active status, and TTL window.
When the exact row exists, the service returns an exact-hit, records a hit event through the primary route, and avoids the provider call.
That is the safest reuse path. In most semantic-cache designs, it comes before embedding or vector lookup.
Use Vector Distance for a Candidate, Not a Decision
If exact lookup misses, the service runs one semantic candidate query:
SELECT answer_text,
VECTOR_DISTANCE(prompt_embedding, TO_VECTOR(?), COSINE) AS distance
FROM sem_cache_entry
WHERE tenant_id = ?
AND chat_model = ?
AND embedding_model = ?
AND embedding_dimension = ?
AND prompt_template_version = ?
AND source_fingerprint = ?
AND policy_version = ?
AND status = 'ACTIVE'
AND expires_at > SYSTIMESTAMP
ORDER BY distance
FETCH FIRST 1 ROW ONLY
This is top-1 retrieval. The current demo does not implement configurable top-k retrieval or reranking. It finds the nearest scoped active candidate, then the Java policy checks whether the distance is under the configured threshold.
The default threshold is:
SEM_CACHE_THRESHOLD=0.10
The semantic-hit scenario uses a prompt with a fixture vector close to the seeded entry:
What is the return window for shoes I have not worn?
The near-miss scenario uses a prompt in the same broad domain but with a different policy meaning:
Can I return worn shoes after 90 days?
The point is to prove both sides of the policy. A useful semantic cache reuses safe paraphrases and rejects unsafe near misses.
Keep the Provider Deterministic
The deterministicProvider() passed into SemanticCacheService is the replacement for a live LLM call in this validation harness. The cache code only needs an AnswerProvider:
public interface AnswerProvider {
String generate(SemanticCacheRequest request);
}
SemanticCacheDemoApplication supplies a deterministic provider:
private static AnswerProvider deterministicProvider() {
return request -> switch (request.scenarioName()) {
case "near-miss" ->
"Worn shoes follow the used-item policy and are not accepted after 90 days.";
default ->
"Unopened shoes can be returned within 30 days when the tenant return policy is returns-v1.";
};
}
Because the fixture vectors are already part of each SemanticCacheRequest, this provider only supplies answer text on misses and near misses. The demo is not trying to prove OpenAI or OCI Generative AI behavior. Those providers are examples of how a production application might generate answers or embeddings, not part of the deterministic validation path.
This keeps the scenario run stable. If a scenario fails, the failure is in the cache policy, SQL, route configuration, or report generation, not in a live model response.
Run the Validation Scenarios
The same ./scripts/run-validation.sh command runs the scenario workload and writes the decision reports. If you skipped the database-boundary check earlier, run it now with the Docker Compose environment running.
The validation workload runs these scenarios in order:
seed-miss
exact-hit
semantic-hit
near-miss
tenant-isolation
model-mismatch
source-fingerprint-mismatch
expired-entry
The generated validation events show the expected decision pattern:
| Scenario | Decision | Route | Provider calls | Distance |
|---|---|---|---|---|
seed-miss | miss | primary | 1 | n/a |
exact-hit | exact-hit | true-cache | 0 | n/a |
semantic-hit | semantic-hit | true-cache | 0 | 0.000016 |
near-miss | near-miss | true-cache | 1 | 0.679840 |
tenant-isolation | miss | primary | 1 | n/a |
model-mismatch | miss | primary | 1 | n/a |
source-fingerprint-mismatch | miss | primary | 1 | n/a |
expired-entry | miss | primary | 1 | n/a |
The exact and semantic hits avoid provider calls. The near miss calls the provider and writes a new answer. Tenant, model, source fingerprint, and expiration differences miss because reuse would be unsafe.
This is the most important output of the demo. It shows that the cache is not returning the nearest answer blindly. It is enforcing scope and freshness.
Treat the Lite Report as Measurement Wiring
run-benchmark-lite.sh reuses the deterministic validation workload and summarizes the events. It records decision counts, provider-call accounting, and latency fields by route.
That is useful, but it is not a production benchmark.
The report has only eight deterministic scenarios. It uses fixture vectors and a deterministic provider. It does not run a statistically meaningful workload, does not isolate every mode as an independent benchmark path, and does not justify claims about production latency, cost, throughput, or scalability.
What it does prove is simpler: the app can generate CSV and Markdown artifacts with the fields a later benchmark would need.
Run it after validation:
./scripts/run-benchmark-lite.sh
The current run prints this summary:
== Benchmark lite summary ==
This lite report reuses the deterministic validation workload to confirm measurement wiring. It is not a production performance benchmark.
Scenarios: 8
Provider mode: deterministic mock
Embedding mode: deterministic fixture vectors
Decision counts:
- exact-hit: 1
- miss: 5
- near-miss: 1
- semantic-hit: 1
Provider calls made: 6
Provider calls avoided by approved reuse: 2
Cache hit rate for approved exact or semantic reuse: 25.00%
Latency by route:
- primary: samples=5 p50_ms=113 p95_ms=203
- true-cache: samples=3 p50_ms=58 p95_ms=64
Generated reports:
- reports/generated/benchmark-lite-events.csv
- reports/generated/benchmark-lite-summary.md
The Markdown report renders the same data in table form:
| Decision | Count |
|---|---|
exact-hit | 1 |
miss | 5 |
near-miss | 1 |
semantic-hit | 1 |
| Route | Samples | p50 latency ms | p95 latency ms |
|---|---|---|---|
primary | 5 | 113 | 203 |
true-cache | 3 | 58 | 64 |
Use those numbers as validation evidence for this fixture workload only. They show that the measurement fields are wired correctly; they are not a general semantic-caching ROI claim.
Production Hardening Checklist
Before adapting the pattern, keep the core policy explicit.
Store enough scope to decide whether reuse is safe: tenant, security scope if applicable, chat model, embedding model, embedding dimension, prompt template, source fingerprint, policy version, status, and expiration. Keep exact lookup ahead of semantic lookup. Treat vector distance as candidate selection, not approval. Record misses and near misses, not only hits.
Route writes, invalidations, and event recording to the primary database. Route only eligible read-only lookup SQL through Oracle True Cache. Decide how your application handles read-after-write visibility before putting cache lookup on a latency-sensitive route.
If you add real embedding providers, make embedding provenance part of the cache key. If you add RAG, keep source documents separate from generated answer reuse. If you add a real benchmark, separate behavior validation from performance claims.
For production work, turn those principles into a short release checklist:
- Define the cache scope fields before writing the first lookup query.
- Version prompt templates, source fingerprints, and policy rules.
- Keep model names and embedding dimensions in the reuse predicate.
- Choose a TTL that matches the business policy behind the answer.
- Route writes and invalidations to the primary database.
- Send only eligible read-only lookups to Oracle True Cache.
- Measure exact hits, semantic hits, near misses, misses, provider calls, and latency by route.
- Review retention, encryption, masking, audit, and deletion requirements before storing prompts or answers.
Conclusion
A semantic cache is safest when it behaves like governed application state, not like an unqualified nearest-neighbor shortcut.
This demo shows that pattern with Oracle AI Database 26ai Free tables, a fixed native vector column, VECTOR_DISTANCE() candidate lookup, exact-hit and semantic-hit reuse, near-miss rejection, scope-based misses, Oracle True Cache read routing, and primary-route writes.
The next step is to preserve those boundaries while adding the production pieces your application needs: real embeddings, stronger route instrumentation, operational invalidation, privacy controls, and a benchmark that is large enough to support performance conclusions.
