As large language models (LLMs) grow increasingly integral to enterprise applications, it becomes paramount to deploy them securely. Common threats, such as prompt injections, can lead to unintended behaviors, data breaches or unauthorized access to internal systems. Traditional application-level security measures, while valuable, are often insufficient to protect LLM endpoints.
Containerization can help address these challenges. By wrapping LLMs and their supporting components in containers, organizations can enforce strict security boundaries at the infrastructure level. This multilayered approach, combined with robust guardrail mechanisms (e.g., those from NVIDIA NeMo Guardrails), helps prevent suspicious or malicious prompts from reaching the core model logic.
This article outlines the design and considerations needed to implement an enterprise-grade secure LLM deployment. As an illustration, we are using the Kubernetes platform on Oracle Cloud Infrastructure (OCI) with OCI Kubernetes Engine (OKE), which is highly conformant with the Cloud Native Computing Foundation’s (CNCF) open source Kubernetes. This implementation should also work with open source Kubernetes. Our example features:
- Container-based guardrails to counter prompt injection attacks.
- Multilayered network, resource and access policies in OKE.
- Integration with Kubeflow for continuous training, validation and deployment (machine learning operations or MLOps).
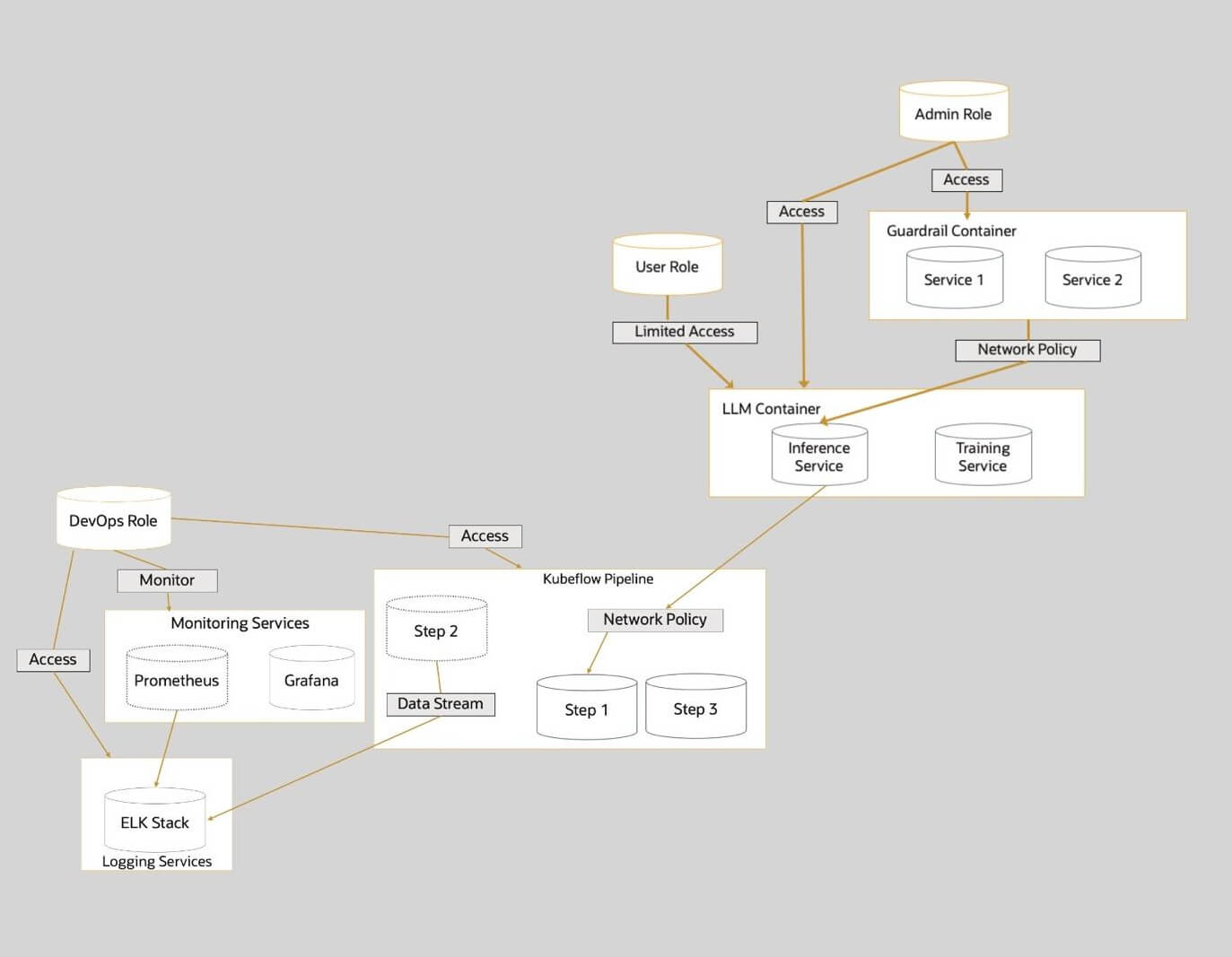
End-to-End Workflow Diagram
This diagram shows the architecture of the solution we’ll present in this article.

Understanding Prompt Injection Vulnerabilities
Prompt injection is a type of attack specific to LLMs where an adversary crafts inputs (prompts) that manipulate the model’s behavior. For example, an attacker might craft text that bypasses content filters or reveals system instructions that should remain confidential. This exploitation can lead to:
- Unauthorized data access: Gaining insights into hidden prompts, confidential user data or system APIs.
- Unexpected LLM behavior: Producing harmful, biased or disallowed outputs.
Prompt injection attacks pose unique challenges, making them particularly dangerous in enterprise environments. Unlike traditional injection attacks such as SQL injection or cross-site scripting (XSS) that can be detected through signature matching, prompt injections involve subtle text manipulations that easily evade standard detection methods.
The dynamic, context-dependent nature of LLMs further complicates this issue, as malicious actors can exploit the model’s own reasoning capabilities to circumvent protective measures. Moreover, in complex enterprise systems, a successful prompt injection attack that reveals sensitive data can serve as a stepping stone for attackers to mount broader network-based threats.
Guardrails and Container-Based Security
What we need are safety filters, and there are options for creating such filters capable of scanning and sanitizing prompts. Let’s look at one such solution:
NVIDIA Guardrails
NVIDIA Guardrails is an open source framework for integrating safety filters that can scan and sanitize prompts before they reach the LLM inference engine. Key features include:
- Text filtering: Identifying malicious or suspicious patterns in prompts.
- Context enforcement: Restricting the operational context (e.g., ensuring the LLM only discusses certain topics).
- Adaptive learning: Continuously improving rule sets and response strategies as new threats emerge.
When paired with Kubernetes’ container orchestration, NVIDIA Guardrails can run as a pre-inference container that enforces security policies on incoming requests.
Multilayered Container Security Controls
The integration of guardrail logic within containers provides multiple layers of security benefits that enhance the overall protection of LLM deployments. These containerized security controls work in concert with the guardrails to create a comprehensive defense strategy. The benefits include:
- Network isolation: Kubernetes network policies limit traffic between pods. The LLM container communicates only with the guardrail container and authorized services.
- Resource constraints: CPU and memory limits in Kubernetes help prevent any single container from monopolizing cluster resources or triggering a denial-of-service scenario.
- Runtime security policies: Tools like Seccomp, AppArmor or SELinux reduce the attack surface by limiting system calls that containers can execute.
Container-Level Access Controls
Organizations deploying LLM endpoints in containers can implement several crucial access controls to enhance security:
- Least privilege access: Granular role-based access control (RBAC) limits who can deploy, modify or access logs from specific containers.
- Secrets management: This method securely stores API keys, encryption keys or credentials in services like OCI Vault or in Kubernetes secrets.
Deployment Model
On a high level, the deployment model implements a structured approach to processing user requests, incorporating multiple specialized containers that each serve specific security and operational functions. This architecture helps ensure that every request undergoes appropriate validation and processing before reaching the LLM and returning to the user. Some of the components include:
- User prompt: The user’s request enters the system via a frontend application or an API gateway.
- Guardrail container: The request is forwarded to a specialized container (e.g., NVIDIA Guardrails) that inspects the prompt for malicious or disallowed content.
- LLM inference container: If the prompt passes the guardrail checks, it is forwarded to the container hosting the LLM. All inference operations and stateful data remain contained here.
- Output processing container: Optionally, another container can recheck the LLM’s response or sanitize it before returning it to the user.
- Continuous monitoring: Logs and metrics feed into a centralized monitoring stack, alerting operators if suspicious activity occurs.
OKE Environment
Incorporating Kubeflow for MLOps
Kubeflow serves as an essential open source MLOps platform that runs natively on Kubernetes, providing crucial capabilities for managing LLM deployments. It enables comprehensive experiment tracking, allowing teams to monitor and compare various fine-tuning experiments for LLM models.
Through pipeline automation features, Kubeflow streamlines the workflow from data ingestion through model training, validation and deployment. Leveraging Kubernetes-native scaling capabilities, it efficiently handles large training data sets and supports multiple concurrent experiments, making it ideal for enterprise-scale LLM operations.
Workflow Integration
Kubeflow’s workflow integration capabilities enhance the security and reliability of LLM deployments by automating critical processes and ensuring consistent application of security controls. The platform supports several key security-focused workflows:
- Training and validation: Use Kubeflow pipelines to schedule and automate data preparation, LLM fine-tuning and validation steps.
- Guardrail rule updates: As you discover new potential prompt injection patterns during training or from production logs, you can update the guardrail rules or filters. This update can be automatically applied to the guardrail container via Kubernetes rolling updates.
- Deployment: Kubeflow triggers container builds and deployments in Kubernetes when a model or guardrail rule set is validated, ensuring continuous delivery with minimal downtime.
Operational Best Practices
- Continuous monitoring and logging: Collect logs from both guardrail and LLM containers. Tools like Prometheus and Grafana track response times, errors and usage patterns.
- Audit logging: For compliance purposes, maintain logs of who accessed the LLM, prompts entered and if any were flagged by the guardrail container.
- Regular security assessments: Periodically run penetration tests focusing on prompt injections and attempts to bypass guardrail logic.
- Multicluster or hybrid deployments: For disaster recovery or specialized use cases, consider deploying across multiple clusters or hybrid setups (on-premises + cloud).
Conclusion
Prompt injections represent a serious and evolving threat to LLM deployments. By combining application-level guardrails (e.g., NVIDIA Guardrails) with container-level security measures, organizations can implement a robust, multilayered defense. This approach helps to prevent malicious or manipulative inputs from compromising the LLM’s functionality or the broader infrastructure.
Using Kubeflow for MLOps adds further resilience and agility, enabling continuous improvement of both the LLM model and its associated guardrail rules. This containerized, highly orchestrated architecture provides the necessary scalability, security and manageability for enterprise-grade LLM deployments.
This article was originally published on The New Stack: https://thenewstack.io/how-to-put-guardrails-around-containerized-llms-on-kubernetes/

