A common challenge in government and enterprise environments is the ability to analyze a complex subject area and cross-subject analysis across tables, schemas, and data types. As complexity grows, the need to simplify and streamline analysis and intelligence reporting becomes more urgent.
Now with Oracle Database 23ai and the rapid evolution of running LLMs locally, such as ollama, we can run various models and tune them based on their requirements and computing constraints.
These challenges become increasingly difficult at the edge. This blog will show you a simple example of how you can experiment with Oracle Database 23ai, OLLAMA, and Oracle Cloud Roving Edge Infrastrcture to address these concerns – all inside a private network.
Here is what’s currently open-source:
| Model |
Parameters |
Size |
Download |
| Llama 3 |
8B |
4.7GB |
ollama run llama3 |
| Llama 3 |
70B |
40GB |
ollama run llama3:70b |
| Phi-3 |
3.8B |
2.3GB |
ollama run phi3 |
| Mistral |
7B |
4.1GB |
ollama run mistral |
| Neural Chat |
7B |
4.1GB |
ollama run neural-chat |
| Starling |
7B |
4.1GB |
ollama run starling-lm |
| Code Llama |
7B |
3.8GB |
ollama run codellama |
| Llama 2 Uncensored |
7B |
3.8GB |
ollama run llama2-uncensored |
| LLaVA |
7B |
4.5GB |
ollama run llava |
| Gemma |
2B |
1.4GB |
ollama run gemma:2b |
| Gemma |
7B |
4.8GB |
ollama run gemma:7b |
| Solar |
10.7B |
6.1GB |
ollama run solar |
With the rapid pace of generative artificial intelligence, we’re committed at Oracle Cloud Infrastructure (OCI) to show our customers and partners how to incrementally adopt and innovate their enterprise environments and empower their technical teams.
Enterprise and public sector organizations can now explore these capabilities further at the edge with our roving edge infrastructure tied to your Oracle Cloud Infrastructure tenancy.
Setting up an example environment
All lab code and references can be found on Github.
Infrastructure Deployment
Here is a quick start guide on how to integrate these technologies with Oracle Cloud Infrastructure (OCI) and Oracle Database 23ai on the OCI Base Database service:
- Create an Oracle Database virtual machine
- Provision a Linux VM with GPU drivers
- Transfer all ONNX or LLM models to the object store
- Example CLI Command: oci os object put -ns aigitops -bn mybucket –name example.onnx –file /Users/me/example.onnx –metadata ‘{“lab”:”dataisfun”,”costCenter”:”dataengineering257”}’
- Request a RED node and attach the two created VMs (Oracle Database VM and Linux VM), along with the object bucket containing your LLM/ONNX models.
Operating System and LLM API Setup
- Install a Linux VM with OL8/9 and Podman, or use an OL VM.
-
Follow these steps for the database (DB) installation:
-
Install Podman and pull the Oracle Database Image (Autonomous Database 23ai Free Container Image – atp-free).
-
For the LLM installation:
# Step 1: Check GPU Devices
ubuntu-drivers devices
# Step 2: Install NVIDIA Library Packages
sudo apt update
sudo apt install libnvidia-common-535 libnvidia-gl-535 -y
# Step 3: Install NVIDIA Driver
sudo apt install nvidia-driver-535-server -y
# Step 4: Reboot System
sudo reboot
# Step 5: Validate Driver Installation
nvidia-smi
# Step 6: Install Ollama AI Platform
curl -fsSL https://ollama.com/install.sh | sh
# Step 7: Configure Ollama Service
sudo tee -a /etc/systemd/system/ollama.service > /dev/null << EOF
[Service]
Environment=OLLAMA_HOST=0.0.0.0
Environment=OLLAMA_KEEP_ALIVE=-1
EOF
# Step 8: Open Firewall Port
sudo iptables -A INPUT -p tcp --dport 11434 -j ACCEPT
sudo -s iptables-save -c
# Step 9: Reload and Restart Services
sudo systemctl daemon-reload
sudo systemctl restart ollama.service
# Step 10: Check Service Status
netstat -tulpn
# Step 11: Pull and Use a Model (Manual Step)
ollama pull
:
"
curl http://IP:11434/api/generate -d '{\"model\": \"
\", \"keep_alive\": -1}'"
Test out /generate endpoint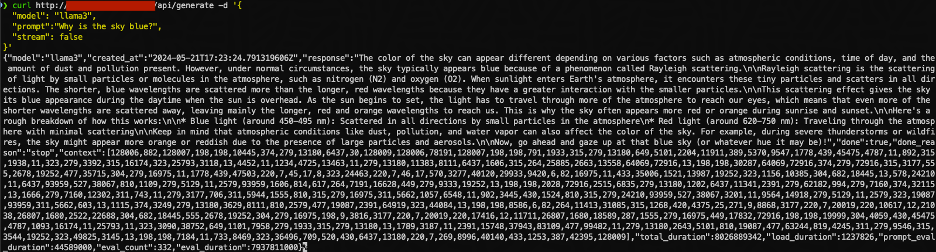
-
Test out the /embeddings endpoint
-
Test out the /chat endpoint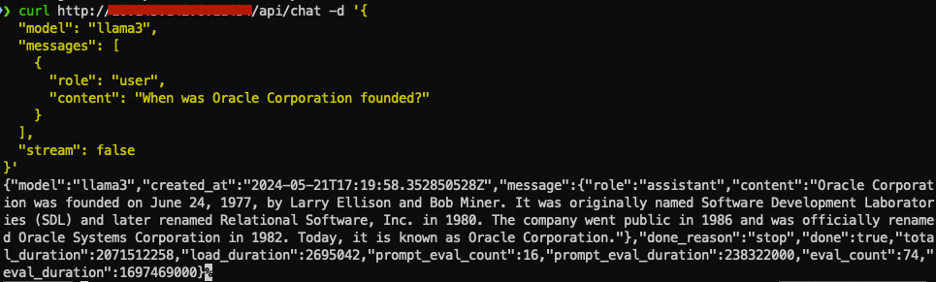
For an example bash script, click here.
Database User & Table Setup for Pre-Trained In-DB Model from HuggingFace
Database User & Table Setup for Pre-Trained In-DB Model from HuggingFace Starting with OML4Py 2.0, the client converts pre-trained transformer models from Hugging Face to the Open Neural Network Exchange (ONNX) format for Oracle Database 23ai AI Vector Search. Hugging Face is an open-source Python library for deep learning, offering thousands of pre-trained models for natural language processing (NLP), computer vision, audio, and more. ONNX is an open format for representing various machine learning models, including transformers, classification, regression, and other types.
The OML4Py client streamlines the path to embedding generation in the database by downloading pre-trained models from the Hugging Face repository, augmenting them with pre- and post-processing steps, converting the augmented model to ONNX format, and loading it into an in-database model or exporting it to a file. Once loaded in ONNX format, you can seamlessly use the in-database ONNX Runtime to generate vector embeddings for Oracle Database 23ai AI Vector Search. The proceeding steps below assume you have acquired and created the ONNX models and placed on the DB Operating System or Roving Edge Object Store.
As the SYS user, or a user with the necessary privileges, connect to the database and create a new user, in this case, named “Analyst”. This user will serve as the database user with access to the local in-database models in ONNX format. By defining this user, you enable the database to locally call the LLM server.
Once the "Analyst" user is set up, you can utilize local in-database models in ONNX format to create vectors and perform further analysis or model training. Ensure that the necessary permissions and access controls are in place for the "Analyst" user to interact with the ONNX models and any relevant data within the database.
Create database directory or pull from object storage onto the DB VM. Here I’m using a directory /u01/models and gave it a name of DM_DUMP.Grant read, write on directory to analyst;Grant DB privs to allow for database data mining api calls to analyst.Load Model as analyst user with :exec dbms_vector.load_onnx_model('DM_DUMP', 'all-MiniLM-L6-v2.onnx', 'doc_model', JSON('{"function" : "embedding", "embeddingOutput" : "embedding", "input" : {"input": ["DATA"]}}'));
Load various documents or word files into database table (only doing one file as example).
drop table demo_tab;
create table demo_tab (id number, data blob);
insert into demo_tab values(2, to_blob(bfilename('DM_DUMP', 'oracle-ai-vector-search-users-guide.pdf')));
commit;
--generate chunks and vectors using in-database model
var chunk_params clob;
exec :chunk_params := '{"by":"words", "max": "50", "split":"sentence", "normalize":"all"}';
var embed_params clob;
exec :embed_params := '{"provider":"database", "model":"doc_model"}';
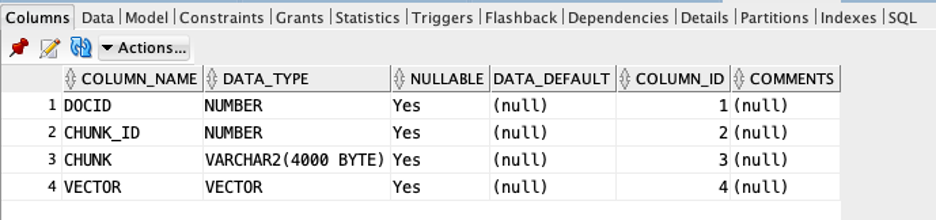
create table vectab as (
select dt.id docid,
et.embed_id chunk_id,
et.embed_data chunk,
to_vector(et.embed_vector) vector
from demo_tab dt,
dbms_vector_chain.utl_to_embeddings(dbms_vector_chain.utl_to_chunks(dbms_vector_chain.utl_to_text(dt.data), json('{"normalize":"all"}')),
json('{"provider":"database", "model":"doc_model"}')) t,
json_table(t.column_value, '$[*]' columns (
embed_id number path '$.embed_id',
embed_data varchar2(4000) path '$.embed_data',
embed_vector clob path '$.embed_vector')) et
);
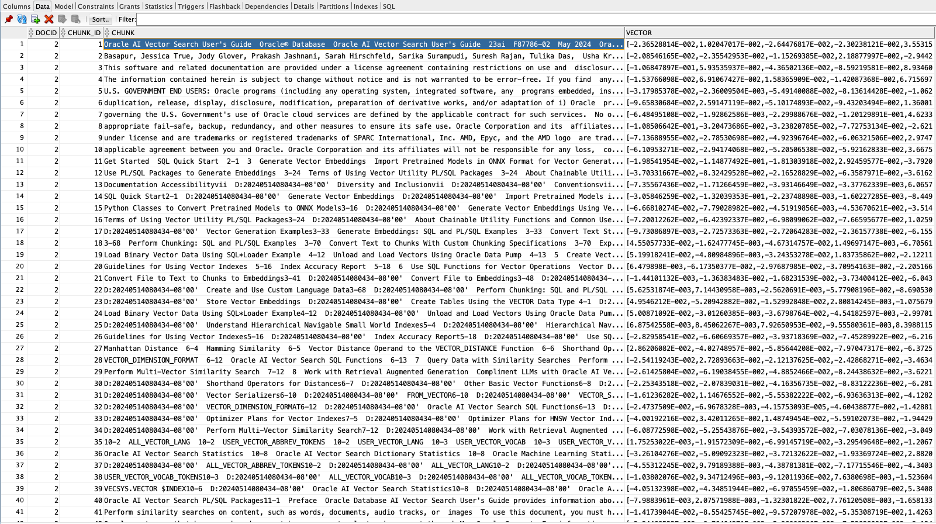
Create Index for Vectors
Create Index for VectorsCREATE VECTOR INDEX vectab_vidx ON vectab (vector) ORGANIZATION NEIGHBOR PARTITIONS;
Simple PL/SQL search but can be REST, APEX, etc. as exposed.
declare
vec vector;
query varchar2(128) := 'embedding';
ans varchar2(256);
cursor c_t2 is
select chunk
from vectab
order by vector_distance(vector, vec, cosine)
fetch first 5 rows only;
begin
dbms_output.put_line('Similiarity Search using PL/SQL and vector_embedding');
dbms_output.put_line('====================================================');
dbms_output.put_line('');
select vector_embedding(doc_model using query as data) into vec;
dbms_output.put_line(to_char(vec));
for item in c_t2
loop
dbms_output.put_line('======item======');
dbms_output.put_line(item.chunk);
end loop;
end;
External Database LLM service call to another VM with GPU exposing the model endpoint
External Database LLM service call to another VM with GPU exposing the model endpoint
declare
vec vector;
query varchar2(128) := 'embedding';
ans varchar2(256);
cursor c_t2 is
select chunk
from vectab
order by vector_distance(vector, vec, cosine)
fetch first 5 rows only;
begin
dbms_output.put_line('Similiarity Search using PL/SQL and vector_embedding');
dbms_output.put_line('====================================================');
dbms_output.put_line('');
select vector_embedding(doc_model using query as data) into vec;
dbms_output.put_line(to_char(vec));
for item in c_t2
loop
dbms_output.put_line('======item======');
dbms_output.put_line(item.chunk);
end loop;
end;
Now we’re calling the private IP on the RED Device the VM of the LLM service private ip RESTful endpoint.
SELECT
dbms_vector.utl_to_embedding(
'hello world',
json('{
"provider": "ollama",
"host": "local",
"url": "http://10.x.x.x:11434/api/embeddings",
"model": "llama3"
}')
)
FROM dual;

Now we test with embedding call for vectors
SELECT
--How to create vectors, vector indexes using local LLM calls
SELECT /*+ parallel 2 */
JSON_VALUE(ch.COLUMN_VALUE, '$.chunk_id') embed_id,
JSON_VALUE(ch.COLUMN_VALUE, '$.chunk_data') embed_data,
dbms_vector_chain.utl_to_embedding(
JSON_VALUE(ch.COLUMN_VALUE, '$.chunk_data'),
json('{
"provider": "ollama",
"host": "local",
"url": "http://10.x.x.x:11434/api/embeddings",
"model": "llama3",
"num_ctx":"4096"
}')
) embed_vector
FROM
dbms_vector_chain.utl_to_chunks(
dbms_vector_chain.utl_to_text(
(select data from demo_tab)
),
json('{"normalize":"all"}')
) ch;

Same document test previously, let’s chunk, create vectors and store in database but use the LLM Service endpoint vs in-database.
SELECT /*+ parallel 2 */
JSON_VALUE(ch.COLUMN_VALUE, '$.chunk_id') embed_id,
JSON_VALUE(ch.COLUMN_VALUE, '$.chunk_data') embed_data,
dbms_vector_chain.utl_to_embedding(
JSON_VALUE(ch.COLUMN_VALUE, '$.chunk_data'),
json('{
"provider": "ollama",
"host": "local",
"url": "http://10.x.x.x:11434/api/embeddings",
"model": "llama3",
"num_ctx":"4096"
}')
) embed_vector
FROM
dbms_vector_chain.utl_to_chunks(
dbms_vector_chain.utl_to_text(
(select data from demo_tab)
),
json('{"normalize":"all"}')
) ch;
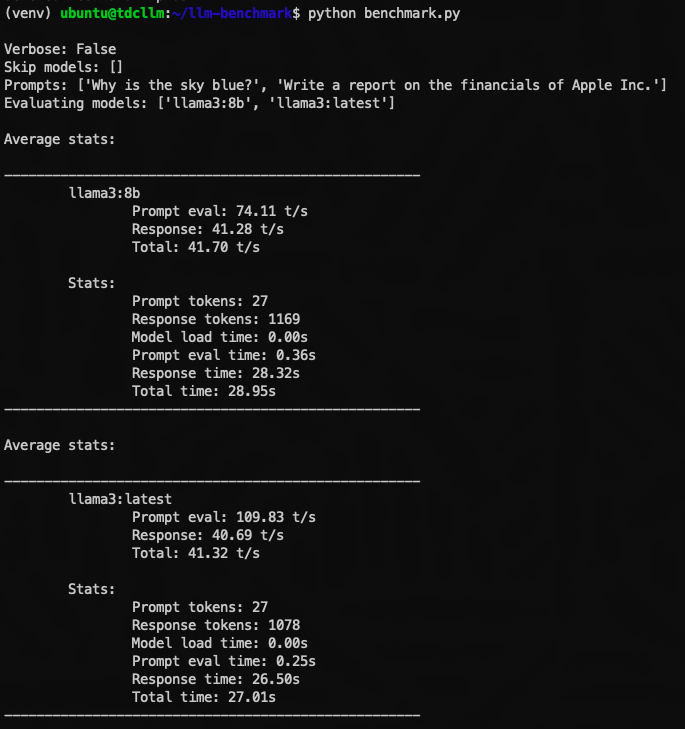
Benchmarks
BenchmarksFor this benchmark, we utilized a powerful RED system with 40 cores (80 virtual CPUs), 512 GB of RAM, and 61 TB of storage. Enhanced with high-speed networking and an embedded GPU, the system excels in AI processing capabilities. We configured a 2-core DB Node VM and a 2-core GPU VM to demonstrate the full potential of GPU passthrough technology. With this setup, our virtual machine gained exclusive access to the entire GPU, showcasing the RED system’s power and flexibility in providing resources for computational tasks, especially those leveraging GPU acceleration.
This setup also highlights the converged database approach (i.e., support for multi-model and multi-workload types) of Oracle Database 23ai to efficiently utilize in-database ONNX models or externally call upon GPU-optimized large language models, all at the tactical edge. Furthermore, with tools like Data Sync and Golden Gate, customers are empowered with flexible options for data movement, even in scenarios with intermittent communications.
Conclusion
ConclusionUnlock the potential of your enterprise data with the next generation of analysis and intelligence powered by Oracle Cloud Infrastructure and a Roving Edge Device. By leveraging the capabilities of Oracle Cloud and extending it to the edge, you can bring the transformative power of Large Language Models (LLMs) directly to your edge devices.
Imagine the possibilities of having advanced language understanding, generation, and decision-making capabilities right where your data is stored and modified. With Oracle Cloud Infrastructure, Oracle Database 23ai and a Roving Edge Device, you can harness the full potential of LLMs to drive innovation, gain insights, and make autonomous decisions at the edge. Speak with your Oracle representative today to learn more about how you can revolutionize your data analysis and unlock new intelligence with this combination of technologies, bringing the power of LLMs directly to your edge operations.
