
“Can you provision a database for my feature branch?”
This simple request used to trigger a 2–3 day process: create a ticket, wait for the DBA team to pick it up, manual database creation, configuration, connection details sent back, inevitably something is misconfigured, back to the DBA team…
By the time the database was ready, the developer had moved on to something else, context was lost, and momentum was dead.
We decided to fix this. What started as a simple automation project became a deep dive into Kubernetes internals, authentication patterns, and the challenges of managing stateful applications in cloud-native environments.
This is the story of that implementation — the problems we faced, the solutions we found, and the lessons we learned.
I presented this with a live workflow at the recent Oracle AI World in Las Vegas. See my slides.
The Problem: Development Database Bottleneck
Our development workflow was broken. We had three teams working on different features of our application, all needing their own database environments for testing. But our infrastructure couldn’t keep up:
For Developers:
- Shared development database meant constant conflicts — your schema change broke someone else’s work
- Manual provisioning took days, killing momentum
- No two development environments were configured the same way
- “Works on my machine” problems were constant
For DBAs:
- Managing 15+ manual database requests per week
- Tracking which database belongs to which feature in spreadsheets
- Forgotten test databases are consuming cloud resources and budget
- No standardization — every database was a snowflake
For the Business:
- Features are taking 20–30% longer due to infrastructure delays
- Monthly cloud bills included $5,000 in orphaned test databases
- Production issues from schema changes that weren’t properly tested
- Developer frustration leading to retention concerns
We needed a better way.
The Vision: Database-as-Code
The initial implementation was performed by Norman Aberin’s work; we envisioned a simple workflow:
- The developer creates a feature branch:
feature/user-authentication - Developer pushes code
- Magic happens
- 15 minutes later, they have a fully configured Oracle database with schemas deployed
- A developer works on their feature with an isolated database
- The developer deletes the branch
- The database automatically cleans up
No tickets. No waiting. No manual intervention.
Infrastructure-as-Code, but for databases.
The Architecture
Here’s what you can achieve (I’ve only implemented a test-db feature branch)

Key Components:
- Oracle Kubernetes Engine (OKE): Our container orchestration platform
- Oracle Database Operator: Manages the database lifecycle as a Kubernetes resource
- GitHub Actions: Orchestrates the entire workflow
- Kustomize: Handles configuration management
- Liquibase: Manages schema versioning and deployment
Each feature branch gets its own namespace in the Kubernetes cluster, complete with an isolated Oracle database instance.
The flow looks like this:
GitHub Repository (feature branches)
↓
GitHub Actions (triggered on push)
↓
OKE Cluster
├─ Namespace: feature-user-auth
│ ├─ Oracle Database Pod
│ ├─ LoadBalancer Service
│ └─ Persistent Volume
└─ Namespace: feature-payment-system
├─ Oracle Database Pod
├─ LoadBalancer Service
└─ Persistent Volume
The Journey: Four Major Challenges
What seemed straightforward in theory hit reality hard. Here are the four major technical challenges we faced and how we solved them.
Challenge 1: Authentication Hell
The Problem
We needed GitHub Actions to authenticate with our OKE cluster. Oracle provides a GitHub Action (oracle-actions/configure-kubectl-oke) that’s supposed to handle this. We followed the documentation, configured our secrets, ran the workflow, and…
Error: Authentication failed
The required information to complete authentication
was not provided or was incorrect.
We spent three days trying different combinations of credentials, regions, and configuration options. The error messages were generic and unhelpful.
The Investigation
OCI authentication uses a private key and a fingerprint of that key’s public component. The Oracle action expected us to provide the fingerprint as a GitHub secret. But we kept getting mismatches — the fingerprint we stored didn’t match what the actual key generated.
Then the breakthrough: What if we don’t store the fingerprint at all? What if we generate it from the private key at runtime?
The Solution
- name: Setup OCI CLI and Configure kubectl
run: |
# Install OCI CLI
bash -c "$(curl -L https://raw.githubusercontent.com/oracle/oci-cli/master/scripts/install/install.sh)" -- --accept-all-defaults
export PATH="$HOME/bin:$PATH"
# Create private key from GitHub secret
mkdir -p ~/.oci
echo "${{ secrets.OCI_KEY_FILE }}" > ~/.oci/key.pem
chmod 600 ~/.oci/key.pem
# Generate fingerprint from actual key (not from secret!)
FINGERPRINT=$(openssl rsa -pubout -outform DER \
-in ~/.oci/key.pem 2>/dev/null | \
openssl md5 -c | awk -F'= ' '{print $2}')
# Create OCI config with generated fingerprint
cat > ~/.oci/config << EOF
[DEFAULT]
user=${{ secrets.OCI_USER_OCID }}
fingerprint=${FINGERPRINT}
tenancy=${{ secrets.OCI_TENANCY_OCID }}
region=${{ secrets.OCI_REGION }}
key_file=$HOME/.oci/key.pem
EOF
# Configure kubectl
$HOME/bin/oci ce cluster create-kubeconfig \
--cluster-id ${{ secrets.OKE_CLUSTER_OCID }} \
--file ~/.kube/config \
--region '${{ secrets.OCI_REGION }}' \
--token-version 2.0.0
Key Insight
Store only what you must. Generate what you can.
The fingerprint is derived from the key, so derive it at runtime. This guarantees they match because they come from the same source.
Impact: Authentication went from 0% success rate to 100%.
Challenge 2: The Kustomize Naming Nightmare
The Problem
We had a base database configuration named freedb-lite-sample. We wanted to add the branch name as a suffix, so for the branchtest-db, we’d get db-test-db. Simple, right?
We used Kustomize’s namesuffix feature:
kustomize edit set namesuffix test-db
The result? freedb-lite-sampletest-db
Kustomize appended the suffix directly to the existing name. Our monitoring scripts were looking for db-test-db, but the database was actually named freedb-lite-sampletest-db.
We spent hours debugging “database not found” errors when the database was right there — just with the wrong name.
The Solution
We switched namesuffix to JSON patches, which give complete control:
cat > kustomization.yaml << EOF
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
namespace: feature-test-dbresources:
- base/sidb-free-litepatches:
- patch: |-
- op: replace
path: /metadata/name
value: db-test-db
target:
kind: SingleInstanceDatabase
EOF
The patch says: “Find the SingleInstanceDatabase resource and replace its metadata name with exactly this value.” No ambiguity, full control.
Lesson Learned
Kustomize’s convenience features are great for simple cases, but for precise control, JSON patches are worth the extra verbosity.
Challenge 3: Namespaces That Won’t Die
The Problem
This was perhaps the most frustrating issue. We’d run our delete workflow to clean up an old database. The workflow completed successfully. But when we tried to create a new database with the same name:
Error from server (AlreadyExists): object is being deleted:
namespaces "feature-test-db" already exists
The namespace was stuck in the “Terminating” state. For hours. In one case, over 6 hours.
Kubernetes was trying to delete the namespace, but couldn’t because resources inside it had “finalizers” — cleanup handlers that must complete before deletion. The SingleInstanceDatabase custom resource had a finalizer for proper database shutdown. Something was preventing that finalizer from completing, so the namespace was stuck in limbo forever.
Developers couldn’t create new databases because the namespace name was technically “taken” even though nothing was actually running.
The Investigation
When I examined the namespace status, I found:
"message": "Some content in the namespace has finalizers remaining:
database.oracle.com/singleinstancedatabasefinalizer in 1 resource instances"
The database resource was blocking namespace deletion. But the database pod was long gone. The finalizer was waiting for something that would never happen.
The Solution
We had to force the issue by removing finalizers:
- name: Force delete stuck namespace and resources
run: |
NAMESPACE="feature-${{ steps.getname.outputs.idname }}"
if kubectl get namespace $NAMESPACE 2>/dev/null | grep -q Terminating; then
echo "Namespace stuck, removing resources..."
# Remove finalizers from database resources first
for db in $(kubectl get singleinstancedatabase -n $NAMESPACE -o name); do
kubectl patch $db -n $NAMESPACE \
-p '{"metadata":{"finalizers":[]}}' --type=merge
done
# Remove finalizers from namespace
kubectl patch namespace $NAMESPACE \
-p '{"metadata":{"finalizers":[]}}' --type=merge
# Force delete if still exists
sleep 15
kubectl delete namespace $NAMESPACE --force --grace-period=0
fi
We run this check before creating a new namespace. If an old one is stuck, we forcibly remove the finalizers and delete it.
Lessons Learned
Kubernetes finalizers are powerful for ensuring proper cleanup, but they can create deadlocks.
Always have a force-cleanup mechanism for production workflows. Custom Resource Definitions are especially prone to this issue.
Impact: Workflow success rate went from ~60% (blocked by stuck namespaces) to 95%+.
Challenge 4: The Connectivity Conundrum
The Problem
Database created successfully. Pod running. Everything looked perfect in the Kubernetes dashboard. But when Liquibase tried to connect from GitHub Actions:
ORA-12541: Cannot connect. No listener at host 10.0.10.10 port 30328
nc: connect to 10.0.10.10 port 30328 (tcp) failed: Connection timed out
We verified credentials. Checked firewall rules. Tested from different networks. Nothing worked.
Then I realized: 10.0.10.10 is an internal Kubernetes IP (ClusterIP). It’s only accessible from inside the cluster. GitHub Actions runs on GitHub’s infrastructure, completely outside our cluster. They’re in different networks with no connectivity.
The Root Cause
The Oracle Database Operator created a ClusterIP service by default:
apiVersion: v1
kind: Service
metadata:
name: db-service
spec:
type: ClusterIP # Internal only!
clusterIP: 10.0.10.10
ports:
- port: 1521
ClusterIP is perfect for pod-to-pod communication within the cluster. But it’s invisible to the outside world.
The Solution
We needed to expose the database externally via a LoadBalancer:
- name: Expose database externally
run: |
kubectl apply -f - <<EOF
apiVersion: v1
kind: Service
metadata:
name: db-external
namespace: feature-test-db
spec:
type: LoadBalancer
selector:
app: db-test-db
ports:
- port: 1521
targetPort: 1521
EOF
# Wait for external IP
kubectl wait --for=jsonpath='{.status.loadBalancer.ingress[0].ip}' \
service/db-external --timeout=300s
In Oracle Cloud, the LoadBalancer service automatically provisions an OCI Load Balancer with a public IP address. The flow becomes:
Liquibase (GitHub Actions)
→ External IP (OCI Load Balancer)
→ ClusterIP (Kubernetes Service)
→ Database Pod
We wait for the external IP assignment (takes 2–3 minutes) before proceeding with Liquibase.
Lessons Learned
Kubernetes networking has layers. ClusterIP is internal-only, NodePort exposes on node IPs, and LoadBalancer gets a cloud provider’s load balancer. Choose based on your access patterns.
Security Note: For production, you’d restrict access to this LoadBalancer (IP allowlists, VPN, etc.). For temporary development databases with non-sensitive data, external access is acceptable.
Alternative Approach: We’re considering running Liquibase as a Kubernetes Job inside the cluster for future iterations. This would keep the database internal-only and eliminate the need for external exposure.
Real World Performance
Here’s what a typical execution looks like:
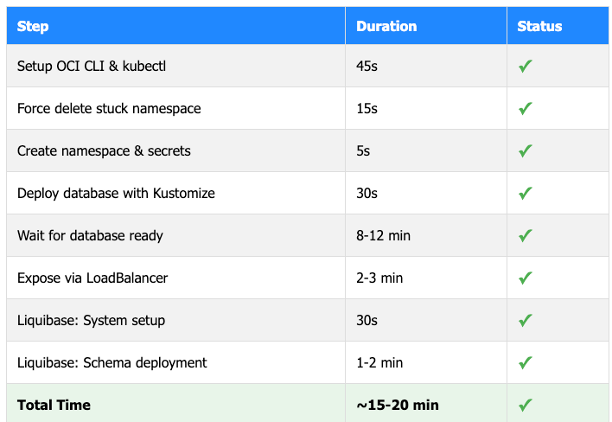
What you get:
- 1 Oracle Database instance (19c or 21c)
- 1 Kubernetes namespace (isolated)
- 3+ application schemas (fully deployed)
- 1 external IP for connectivity
- Automatic cleanup on branch deletion
Compare this to our previous process: a minimum of 2–3 days.
The Impact
Quantitative Results
Before:
- Average database provisioning time: 2–3 days
- Monthly orphaned database costs: ~$5,000
- Developer satisfaction score (infrastructure): 4.2/10
- Features delayed by database availability: 20–30%
After:
- Average database provisioning time: 15–20 minutes (99.5% reduction)
- Monthly orphaned database costs: ~$200 (96% reduction)
- Developer satisfaction score (infrastructure): 8.7/10
- Features delayed by database availability: <2%
Qualitative Benefits
Developers:
“I can experiment freely without worrying about breaking someone else’s work”
“Testing schema changes is so much easier now”
“I love that I can just push code and come back to a ready database”
DBAs:
“I’ve gone from managing 15+ manual requests per week to zero”
“Everything is standardized now — I know exactly how every database is configured”
“The automatic cleanup is amazing for cost control”
Project Managers:
“Features are shipping faster”
“Our cloud bill dropped significantly”
“Developers are happier, which helps with retention”
Lessons Learned
1. Authentication: Store Less, Generate More
Don’t store credentials you can derive. We went from storing five pieces of authentication data to storing two (private key and region), generating everything else at runtime. This reduced secret management complexity and eliminated mismatch errors.
2. Kubernetes: Plan for Finalizers
Custom Resource Definitions often have finalizers. In a perfect world, they clean up gracefully. In reality, they can deadlock. Always have force-cleanup mechanisms for production workflows.
3. Networking: Internal vs External Matters
ClusterIP vs LoadBalancer isn’t just about exposure — it fundamentally changes who can access your services. Understand your access patterns before choosing service types.
4. Debugging: Add Observability Early
Every step in our workflow now echoes what it’s doing and the results. When something fails at 2 AM, these logs are invaluable. Don’t wait for production failures to add debugging.
5. Automation: Perfect is the Enemy of Done
Our first version worked for 60% of cases. We shipped it, learned from failures, and iterated. Waiting for perfection would have meant developers still waiting days for databases.
Future Improvements
We’re not done. Here’s what we’re planning:
Security:
- Run Liquibase as a Kubernetes Job (keep databases internal)
- Add network policies (restrict database access to specific pods)
- Migrate from GitHub Secrets to OCI Vault (better secret management)
- Implement TLS/SSL for database connections
Operations:
- Automated backups before schema changes
- Prometheus metrics for database health
- Cost tracking by feature branch
- Slack notifications for deployment status
Developer Experience:
- Database seeding with realistic test data
- Schema diff tool (compare feature branch to main)
- Direct kubectl access for troubleshooting
- Rollback capability for schema changes
Tools and Resources
This implementation wouldn’t have been possible without standing on the shoulders of others:
Core Technologies:
- Oracle Database Operator for Kubernetes
- Oracle Kubernetes Engine (OKE)
- GitHub Actions
- Liquibase
- Kustomize
Inspiration:
- Norman Aberin’s blog post provided the initial architecture and approach
Documentation & Community:
- Oracle Cloud Infrastructure documentation
- Kubernetes documentation (especially on finalizers and service types)
- Stack Overflow for specific troubleshooting
- Claude AI for debugging strategies and troubleshooting guidance
Try It Yourself
Want to implement this in your environment? Here’s where to start:
GitHub – Kuassim/AiWorld: Oracle AI World demo
- Set up an OKE cluster with the Oracle Database Operator installed
- Configure GitHub secrets for OCI authentication
- Create base database configuration using Oracle DB Operator manifests
- Implement the create workflow, starting with authentication
- Add Kustomize for configuration management
- Integrate Liquibase for schema deployment
- Build the delete workflow for cleanup
Start simple. Get authentication working first. Then add one piece at a time. Each challenge we faced taught us something valuable about the technology stack.
Conclusion
From 2–3 days to 15–20 minutes. From manual spreadsheet tracking to automated GitOps. From $5,000 in wasted resources to $200. From frustrated developers to delighted ones.
But more than the metrics, what we built is a culture shift. Databases are no longer special snowflakes that require manual care. They’re infrastructure-as-code, just like everything else in our cloud-native stack.
Every developer on our team can now provision a database with a git push. They can experiment freely, test thoroughly, and ship confidently. The database is no longer a bottleneck — it’s an enabler.
That’s the real value of automation: not just time saved, but possibilities created.
Have you implemented similar database automation in your environment? What challenges did you face? I’d love to hear your experiences in the comments.
Tags: #Kubernetes #DevOps #Oracle #GitHubActions #DatabaseAutomation #CloudNative #InfrastructureAsCode #OCI #Liquibase #Kustomize
Kubernetes Github Actions Oracle Database DevOps Oracle Cloud
