Three Levels Every Agent Engineer Must Know
Chances are you have already run an agent loop today without naming it.
Every session with a coding companion such as Claude Code, Codex, or Cursor is one: the model reads a request, inspects the repository, edits a file, runs the tests, observes the failures, and edits again until the build passes.
That cycle of reasoning, acting, and observing the result is the agent loop at work, and it now sits at the centre of nearly every production agent system. The agent loop is the repeating cycle a harness runs within a single agent turn: assemble context, invoke the model to reason, act on its decision, and go again until a stop condition ends the run.
This piece unpacks that loop across three levels of understanding.
- Level 1 is the minimal loop most developers meet first: an LLM, a handful of tools, and a response.
- Level 2 introduces a lifecycle inside the loop, where memory operations turn a stateless process into a reasoning engine with state.
- Level 3 pushes operations both inside and outside the loop, where the agent harness becomes a system in its own right.
By the end, you will know which level your system sits at, what breaks when the level and the task are mismatched, and what engineering work moves you up. Every pattern discussed is implemented in the companion notebook, built on Oracle AI Database, so you can run the loop rather than just read about it.
What is an Agent
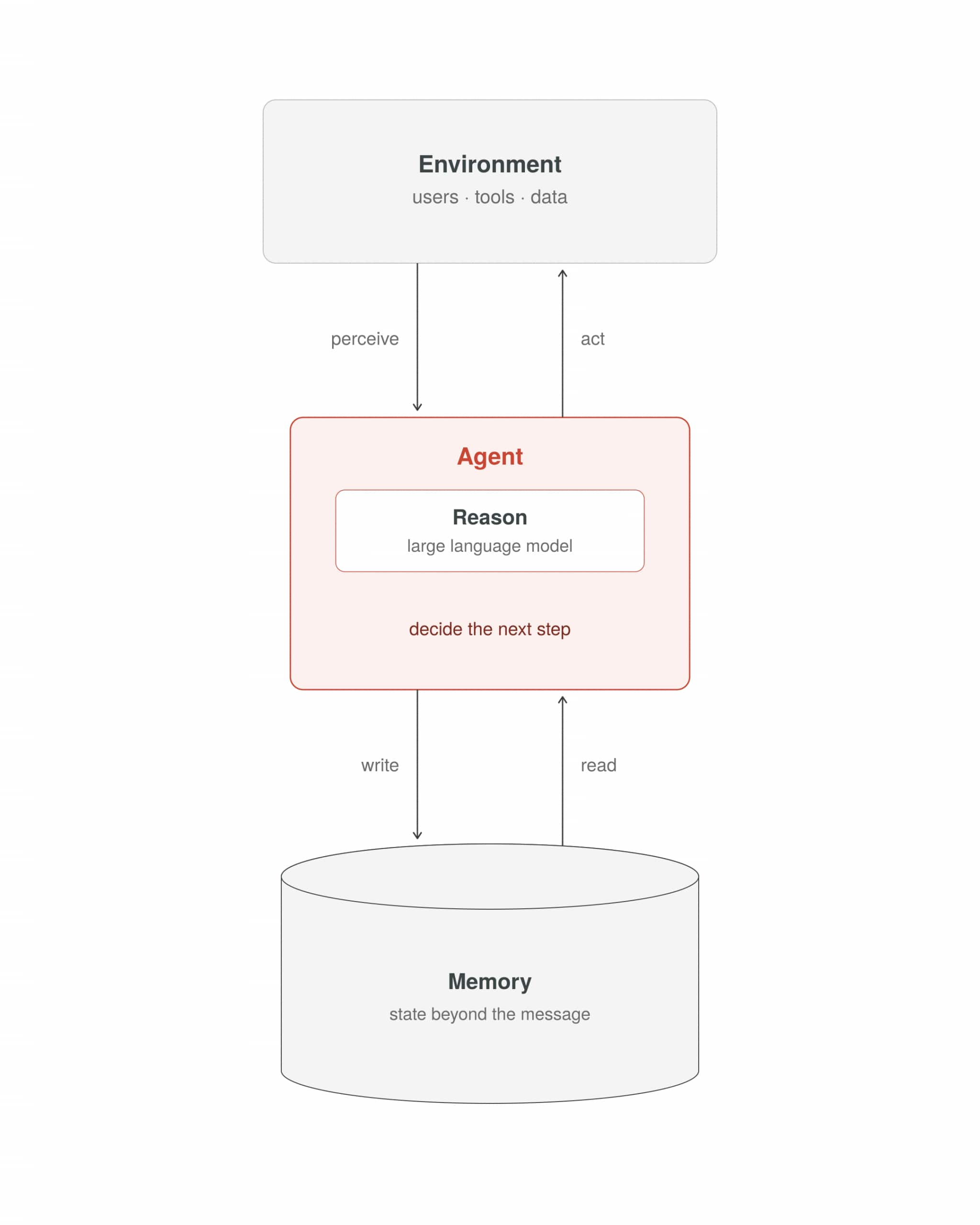
An agent is a computational system that perceives its environment, reasons about what it perceives, takes actions to achieve a goal, and has some form of memory. That description applies to many things: a thermostat, a chess engine, a human professional. What makes an AI agent distinct is that the reasoning step is handled by a large language model, and the range of possible actions extends well beyond a binary output.
An agent’s architecture consists of two separable layers. The first is the model: the inference engine that does the reasoning. The second is the harness: the code that prepares context, executes tool calls, enforces operational constraints, and persists state. Most agent engineering work happens in the harness, not the model. Understanding that boundary clarifies where failures originate and where interventions are effective.

An agent needs at minimum four things to be useful:
- Instructions: a system prompt or goal that tells it what it is trying to accomplish.
- Memory: access to information beyond the current message, including prior context, retrieved knowledge, and learned patterns.
- The ability to take actions: tool calls, API requests, database writes, or any operation with an external effect.
- A reasoning engine: an LLM that looks at context and decides what to do next.
What Is a Loop?
A loop is a control structure that repeats a block of execution until a condition is met. In programming you encounter this everywhere: iterating over a collection, running until a flag is set, calling recursively until a base case is reached.
The agent loop applies that same structure to an LLM-powered system. Rather than processing a user message once and returning a static response, the agent feeds its output back into itself, reasoning, acting, observing the result, and reasoning again, until it determines the task is complete.
The necessity for loops in agent execution can be derived from the nature of the use cases and tasks agents are applied to. These common use cases can be referred to as application modes: the expected interaction patterns between a user and an agent. There are three:
- Assistant
- Deep Research
- Coding
Take the deep research mode. An agent tasked with finding relevant sources, identifying contradictions across them, and producing a structured summary is not running a single-shot task. It requires the agent to:
- Search for relevant sources.
- Read and evaluate what it finds.
- Identify gaps and contradictions.
- Search again to fill in those gaps.
- Synthesise everything into a coherent output.
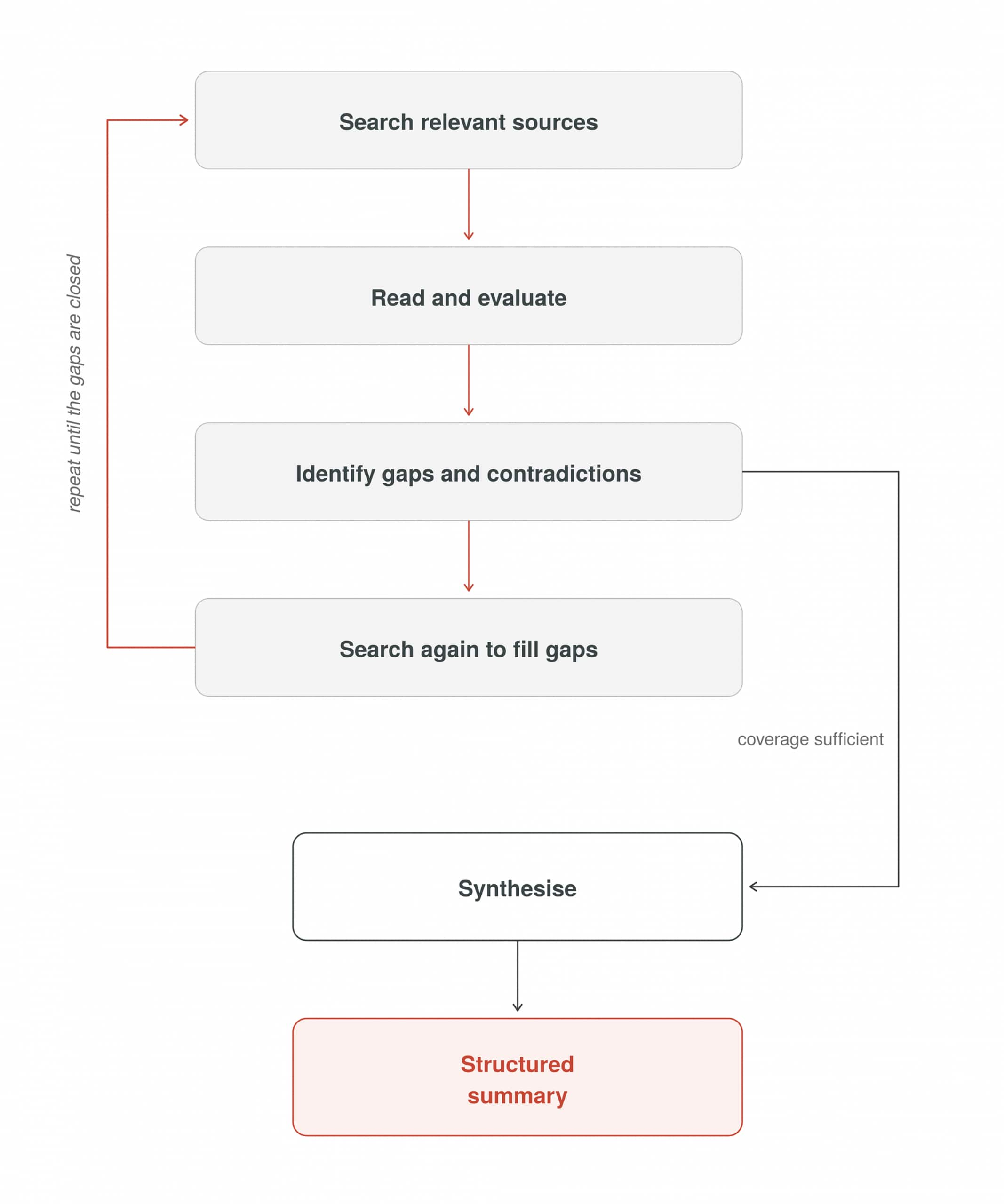
No single LLM call can do all of that. What is required is the mechanism and scaffolding that allows the model to reason, act, observe the result, reason again, and continue until the task is complete. That mechanism is the agent loop.
Notably, implementations of agent frameworks and harnesses, however opinionated, have shared one thing in common: convergence on a minimal agent loop design. That convergence is arguably not much of a design choice, so much as a logical consequence of the task itself.
The agent loop exists because long-horizon tasks cannot be completed in a single forward pass.
The loop emerging as a design pattern draws a parallel to how humans operate in most organisations: structured cycles of work, review, and feedback that repeat until the objective is met.
Stop Conditions
Loops have to be exited eventually. The programmatic loops taught in computer science classes usually exit in one of two ways: the iteration count for the loop is reached, or a break statement inside the loop triggers an exit.
A well-designed agent loop defines explicit exit criteria. Common examples:
- The model produces a final response with no pending tool calls.
- A goal-completion check returns true: an objective-specific predicate, not merely the absence of tool calls.
- A maximum number of iterations is reached.
- A wall-clock timeout expires.
- An error occurs that the agent cannot recover from.
- The harness identifies a failure mode, such as the agent repeating the same action without progress.
- The agent explicitly invokes an exit action or sets a completion flag.
In the notebook accompanying this article, the stop conditions are implemented directly inside the harness:
def call_agent(query, thread_id='1', max_iterations=10,
max_execution_time_s=60.0):
start_time = time.time()
iteration = 0
while iteration < max_iterations:
if time.time() - start_time > max_execution_time_s:
break # Wall-clock timeout
response = call_openai_chat(messages, tools)
if not response.tool_calls:
break # Model produced a terminal message; exit the loop
# Execute tools, append outputs, continue
iteration += 1
# Fallback if max iterations reached
return 'Max iterations reached; please refine the request.'The max iterations of the loop is set to 10 by default. This is a guard against the loop running indefinitely, which can incur high operational cost through the increase in token consumption across inference calls. There is also a max_execution_time_s parameter, which adds a temporal guard to the agent loop’s execution.
It is worth noting that a terminal message from the model, one with no further tool calls, ends the agent’s turn. It does not mean the user’s goal has been satisfied. The model may return a clarifying question, a partial result, or a response that requires follow-up. The agent harness is responsible for checking whether the goal is actually complete, not simply whether the model has stopped emitting tool calls. This distinction becomes more consequential as tasks grow in length and complexity, and it is where domain expertise becomes paramount in agent harness engineering.
Failure mode identification deserves its own mention as an exit path. A loop should break not only when work completes but when work stops progressing.
The clearest example is tool call repetition: the agent invokes the same tool with identical arguments for a third consecutive iteration, a strong signal that it is stuck rather than working. A well-instrumented harness keeps a window of recent tool calls, detects the repetition, and exits with a diagnostic instead of spending the remaining iterations on a stalled run. Oscillation between two states belongs to the same family of detectable failures.
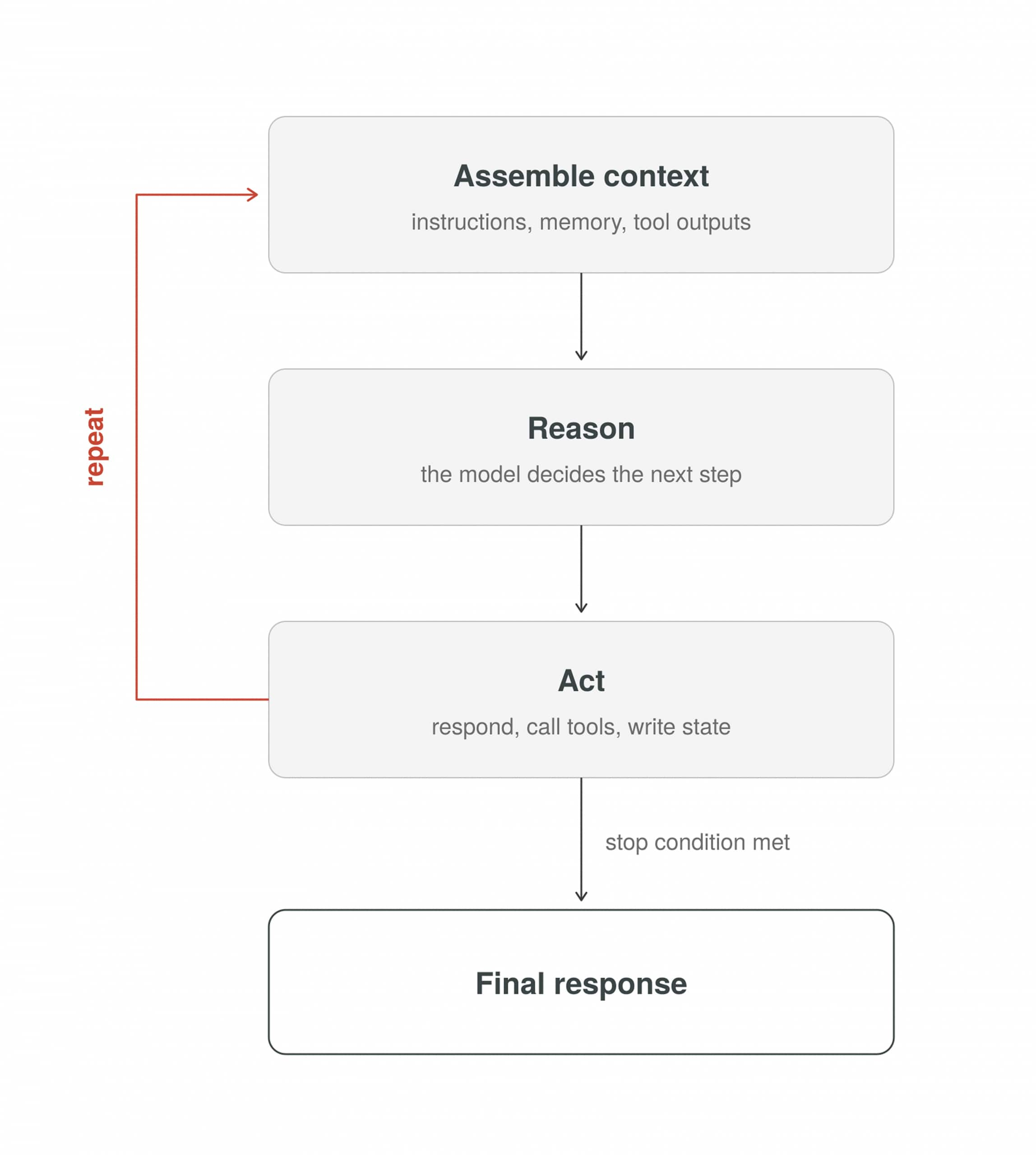
Defining the Agent Loop
With the components and the exit criteria established, the definition can now be stated with precision:
The Agent Loop
A cyclical, iterative execution pattern inside a single agent run where the harness repeatedly:
- Assembles execution context: system instructions, conversation state, retrieved memory, tool outputs, and any relevant external data.
- Invokes a reasoning model to decide what to do next.
- Acts: responds to the user, calls tools, writes memory or state, or updates its plan.
Each cycle appends its trace (assistant messages, tool outputs, state updates) to the context and repeats until a termination check ends the run. Context-window pressure and operational safety (timeouts, iteration caps, budget guards) are first-class concerns, not afterthoughts.
Three Levels of the Agent Loop
The agent loop is not a fixed pattern. The simple design presented above evolves as memory, tooling, and opinionated scaffolding are added. The three levels below provide a framework for where a system currently sits and what engineering work lies ahead. Most production failures (agents that repeat themselves, lose context, or produce inconsistent results across sessions) trace back to a mismatch between task complexity and agent level.
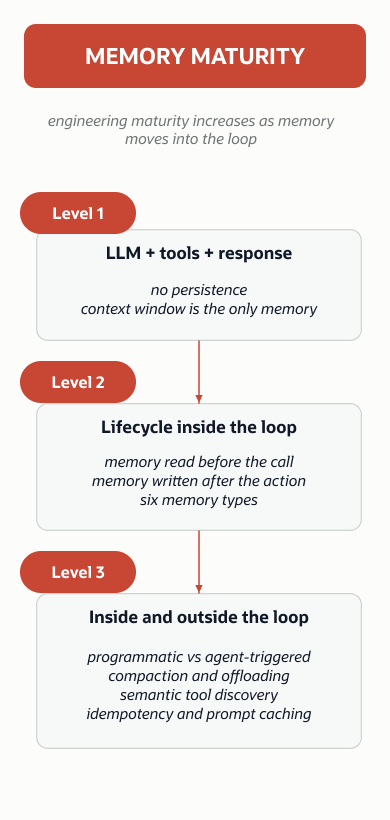
Level 1: LLM + Tools + Response
At its simplest, the agent loop is an LLM that can call tools and return a response. There is no persistent memory, no external state, and no scaffolding beyond the loop itself. The loop iterates because tool results must be fed back to the model before it can produce a final answer.
The code below demonstrates the pattern most developers encounter when building simple tool-calling agents:
messages = [system_prompt, user_message]
while True:
response = llm.chat(messages, tools=available_tools)
if response.tool_calls:
for call in response.tool_calls:
result = execute_tool(call.name, call.args)
messages.append(tool_result(result))
else:
return response.content # Terminal message; exit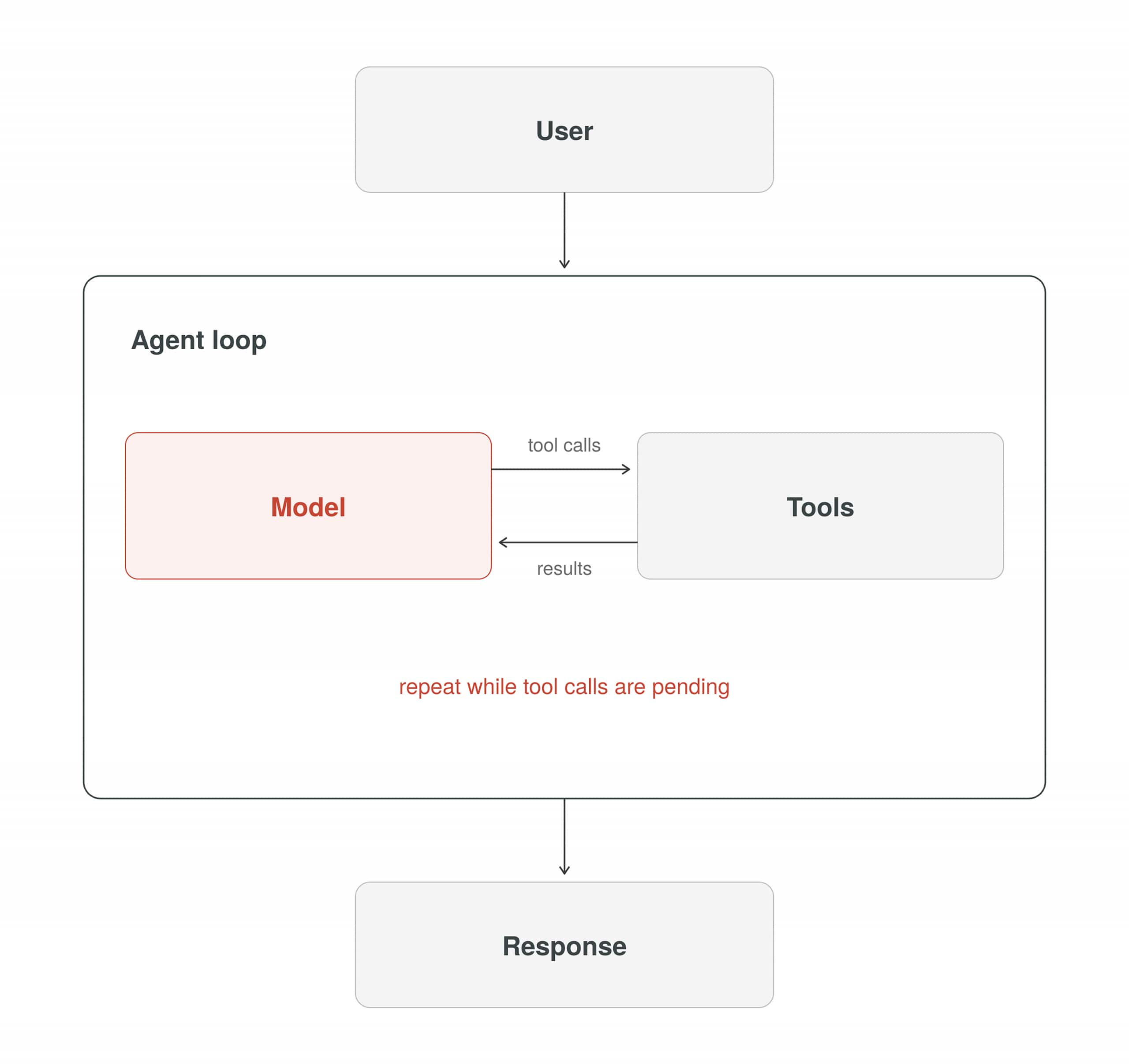
LangChain’s ReAct agent provides this pattern out of the box. The agent receives an input query, selects a tool, calls it, observes the output, and reasons again, all within a single run:
from langchain.agents import AgentExecutor, create_react_agent from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model='gpt-4o')
agent = create_react_agent(llm, tools=[search_tool], prompt=prompt) executor = AgentExecutor(agent=agent, tools=[search_tool],
max_iterations=10)
executor.invoke({'input': 'What are the latest AI papers on agent memory?'})Level 1 is where most developers start, and it is genuinely useful for self-contained tasks. Its limitation is structural: the agent has no recollection of previous conversations. Every run starts cold, the context window is the only memory it has, and it resets completely when the run ends. On any multi-turn or long-horizon task, it will repeat work it already did, lose track of decisions made earlier in the session, and produce output that contradicts its own prior responses.
Level 2: Lifecycle Inside the Loop
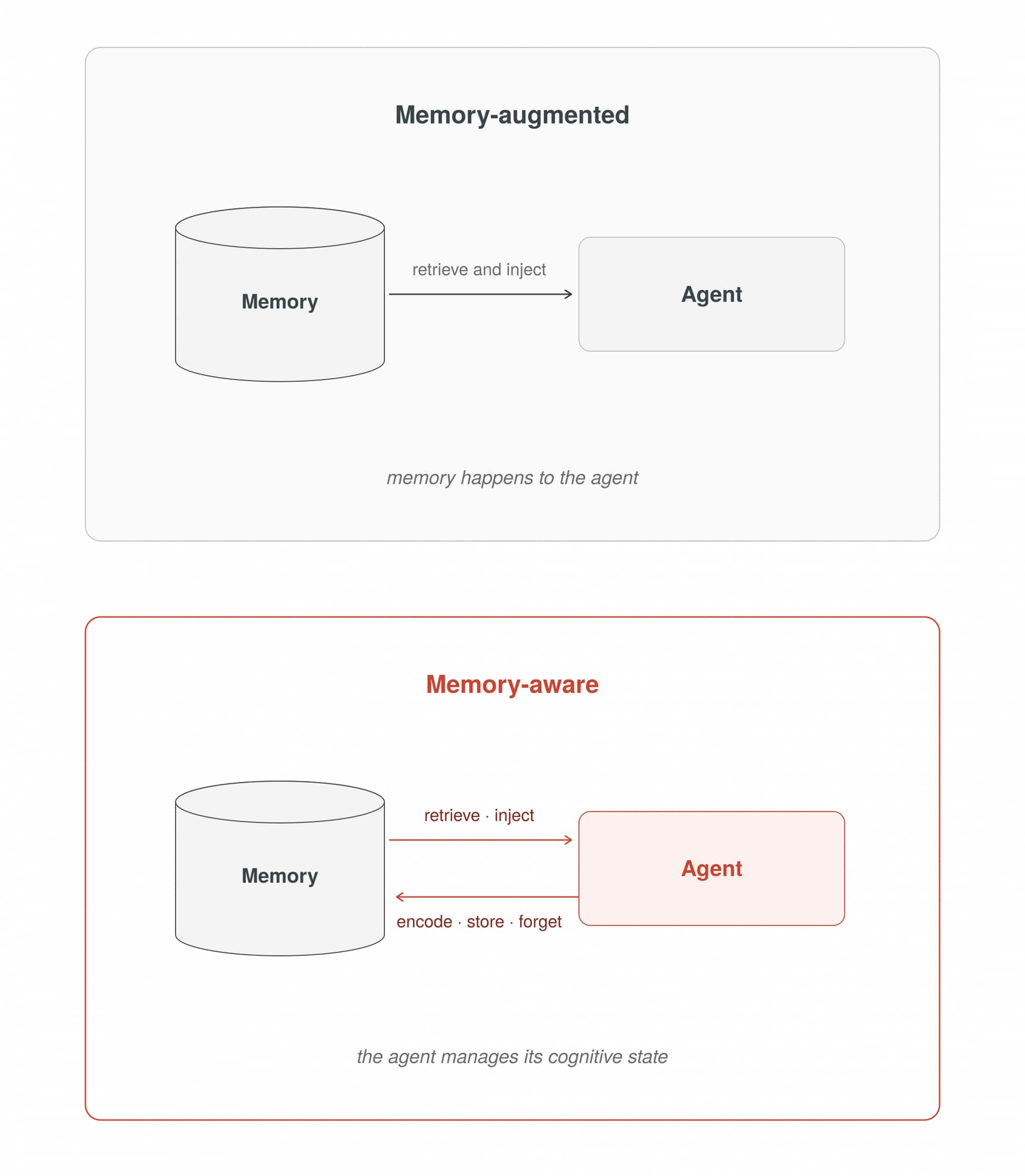
At Level 2, operations begin to appear inside the agent loop. Memory is read before the LLM is called, and memory is written after the agent acts. The loop now has a lifecycle. At Level 1, the loop can be seen as a transport mechanism for tool calls. At Level 2, the loop becomes a reasoning engine with state. This is also where the distinction between a memory-augmented agent and a memory-aware agent becomes consequential.
- Memory-augmented agents retrieve and inject information into context. They read from memory, but they do not actively manage it. Memory is something that happens to them.
- Memory-aware agents treat memory as a first-class engineering concern. They encode, store, retrieve, inject, and forget, actively managing their cognitive state within each run and across sessions. Level 2 is where you begin building memory-aware agents.
This distinction, and the engineering it implies, is the subject of the DeepLearning.AI short course Agent Memory: Building Memory-Aware Agents, built with Oracle, if you want the full overview.
Level 2 makes context assembly trade-offs immediately visible. Adding more memory types (conversation history, retrieved documents, entity records, workflow patterns) improves grounding and action selection. On the other hand, it also introduces cost: more tokens, higher latency, and a greater risk of injecting irrelevant or stale content that misleads the model rather than informing it.
There are a few failure modes worth mentioning:
- Noisy retrieval: semantically similar documents that are not actually relevant to the current query. Mitigation approaches are implemented via relevance thresholds and precision-oriented retrieval strategies such as hybrid search and pre-, post-, and in-filtering methods in retrieval pipelines.
- Stale memory: data can quickly become irrelevant in a fast-paced problem domain: cached facts, entity records, or summaries that are no longer accurate. Mitigate with TTL policies and update-on-write patterns.
- Tool schema overload: context bloat is a common problem, and it is most prevalent in tool-calling agents with too many tool definitions passed to the model at once, degrading tool selection accuracy. Mitigate with semantic tool retrieval rather than exhaustive enumeration; this is shown in the companion notebook for this piece.
There are more failure modes, and in production these are not edge cases. They are predictable failures that any Level 2 agent will encounter as memory stores grow. Designing mitigation strategies at the start is cheaper than retrofitting fixes later.
Memory operations are common in Level 2 agent loops, mainly because agents at this level are designed for continuity and adaptation. Memory operations are programmatic methods designed to modify data and information within the agent’s system boundary and across other system components such as databases and external stores.
| Operation | When It Runs | Purpose |
|---|---|---|
| Read conversational memory | Before LLM call | Load prior chat history into context |
| Read knowledge base | Before LLM call | Inject relevant documents and facts |
| Read workflow memory | Before LLM call | Surface known action patterns |
| Read entity memory | Before LLM call | Resolve named references in the query |
| Write conversational memory | After user message received | Persist the user turn |
| Write knowledge base | After tool search | Store retrieved results for future runs |
| Write entity memory | After LLM response | Extract and persist people, places, systems |
| Write conversational memory | After final response | Persist the assistant turn |
In the accompanying notebook, these operations are centralised in a MemoryManager class backed by Oracle AI Database. Before each run, the harness calls all read operations to assemble context. After each run, write operations persist the new information:
# -- Reads: all run BEFORE the tool-call loop ------------------------ conv_mem = memory_manager.read_conversational_memory(thread_id) knowledge = memory_manager.read_knowledge_base(query)
workflows = memory_manager.read_workflow(query)
entities = memory_manager.read_entity(query)
summaries = memory_manager.read_summary_context(thread_id)
context = build_context(conv_mem, knowledge, workflows, entities, summaries)
# -- Inner tool-call loop -------------------------------------------- response = run_tool_call_loop(context, tools)
# -- Writes: all run AFTER the loop exits ---------------------------- memory_manager.write_conversational_memory(thread_id, 'assistant', response)
memory_manager.write_entity(extract_entities(query, response))
The notebook uses six distinct memory types, each stored in Oracle AI Database and each serving a specific cognitive function:
- Conversational memory: episodic chat history retrieved by thread ID via a standard SQL table. Exact lookup, no similarity search required.
- Knowledge base memory: semantic memory backed by a vector-enabled SQL table with HNSW indexing for similarity search.
- Workflow memory: procedural memory storing learned action patterns and tool sequences.
- Toolbox memory: a vector-indexed registry of tool definitions enabling semantic discovery rather than exhaustive schema enumeration.
- Entity memory: LLM-extracted people, places, and systems, persisted across sessions.
- Summary memory: compressed context for long conversations, with just-in-time expansion when the agent needs the full content.
At Level 2, the loop is no longer just executing tools. It is actively managing its own cognitive state.
Level 3: Operations Inside and Outside the Loop
At this point, developers understand not only which operations they require inside the loop; more opinionated scaffolding and harness begin to form around the agent loop itself.
Operations now exist both within the loop and outside it, and there are deliberate architectural choices about which side of the boundary each operation belongs on. This is where agent engineering becomes opinionated, and where context engineering and memory engineering become distinct disciplines with separate concerns.
In a Level 3 agent loop, some operations should be automatic. The agent should never have to decide whether to load its own conversation history. Others should be agent-triggered: the agent decides when to search the web, not the harness.
Getting this boundary wrong produces either context bloat, when too much is loaded automatically, or missed context, when content that should always be present is left to the model’s discretion.
| Operation | Programmatic | Agent Triggered | Why |
|---|---|---|---|
| Read conversational memory | Yes | No | The agent always needs its history |
| Read knowledge base | Yes | No | Relevant documents always loaded at run start |
| Read workflow base | Yes | No | Known patterns always surfaced before reasoning |
| Read entity memory | Yes | No | Named references always resolved upfront |
| Read summary context | Yes | No | Summary IDs always loaded; full content expanded on demand |
| Expand a summary | No | Yes | Agent decides when it needs the full content |
| Search the web (Tavily) | No | Yes | Agent decides when stored knowledge is insufficient |
| Summarise conversation | No | Yes | Agent decides when context needs compaction |
| Write tool log (offload) | Yes | No | Automatic after every tool call; keeps context lean |
Context engineering at Level 3
Three techniques only become necessary at Level 3. Below Level 3, your context is manageable by construction. At Level 3, with memory reads, multiple tool calls, and iterated reasoning, it is not.
- Context window monitoring: tracking token usage across iterations to detect when compaction is needed before the window fills and performance degrades.
- Conversation compaction: replacing verbose chat history with compressed summaries while preserving originals in the database. The notebook marks messages with a summary_id rather than deleting them, keeping the full record available for audit and on-demand expansion.
- Tool output offloading: persisting full tool outputs to a tool log table and replacing them in context with a compact one-line reference.
The tool log pattern is worth examining in detail. A single web search can return three to four thousand tokens of raw results. Without offloading, every subsequent iteration in the same run carries those tokens. With offloading, the context receives only a reference:
def execute_tool(tool_name, tool_args, thread_id):
raw_output = run_tool(tool_name, tool_args)
# Full output persisted to the database
log_id = memory_manager.write_tool_log(
thread_id=thread_id,
tool_name=tool_name,
tool_output=raw_output
)
# Context receives only the compact reference
return f'[Tool Log ID: {log_id}] Results stored. Call read_tool_log to retrieve.'Semantic tool discovery
At Level 3, the number of available tools is unlikely to stay small. Passing every tool schema to the model on every iteration is a known failure mode: tool selection accuracy drops as the schema list grows, and token costs climb regardless of how many tools are actually relevant.
The notebook addresses this with a Toolbox: a vector-indexed registry of tool definitions where only semantically relevant tools are retrieved and passed to the model for each query. Tools are registered with LLM-augmented metadata so that embeddings capture intent and use case, not just function signatures:
@toolbox.register_tool(augment=True) # LLM enriches description for retrieval
def search_tavily(query: str, max_results: int = 5):
"""Search the web and persist results in the knowledge base.""" ...
# At runtime: only semantically relevant tools passed to the model
relevant_tools = memory_manager.read_toolbox(current_query)Idempotency and tool reliability
Tool call failures are a production reality. Network errors, rate limits, and transient service issues occur regularly. If the harness retries a failed tool call naively, it risks executing a side-effecting operation twice: writing a record, sending a message, or triggering a payment more than once.
The mitigation is idempotency: assigning each tool call a stable key before execution so that retries can be safely distinguished from duplicate calls. This is harness-level engineering, not model-level reasoning, and it belongs in the Level 3 design.
Prompt caching and message ordering
At Level 3, the harness also starts to affect inference economics through prompt caching. Most LLM providers implement prefix-based caching: if the beginning of a prompt is identical to a recent request, the cached computation can be reused, reducing latency and cost.
The implication for agent design is concrete. Rewriting earlier messages mid-conversation, to clean up history, reorder context, or inject new system instructions inline, breaks prefix stability and degrades cache hit rates. The correct pattern is to append new instructions rather than modifying existing message history. The Codex implementation established this explicitly: old prompts are preserved as exact prefixes of new prompts specifically to maintain caching benefits across long multi-step runs.
Level 3 is where the agent harness becomes a system in its own right. The inner loop, assembling context, invoking the model, and acting, has not changed. What has changed is everything around it: the scaffolding that feeds it, the operational constraints that govern it, and the persistence layer that gives it continuity across time and sessions.
Other Loops the Agent Engineer Should Know
The agent loop does not run in isolation. It sits inside a wider system of loops, and the engineering decisions made inside the agent loop are shaped by what happens in the loops around it.
Three matter most to agent engineers and memory engineers: the training loop that produced the model, the feedback loop that signals whether the system is working, and the human loop that bounds its authority.
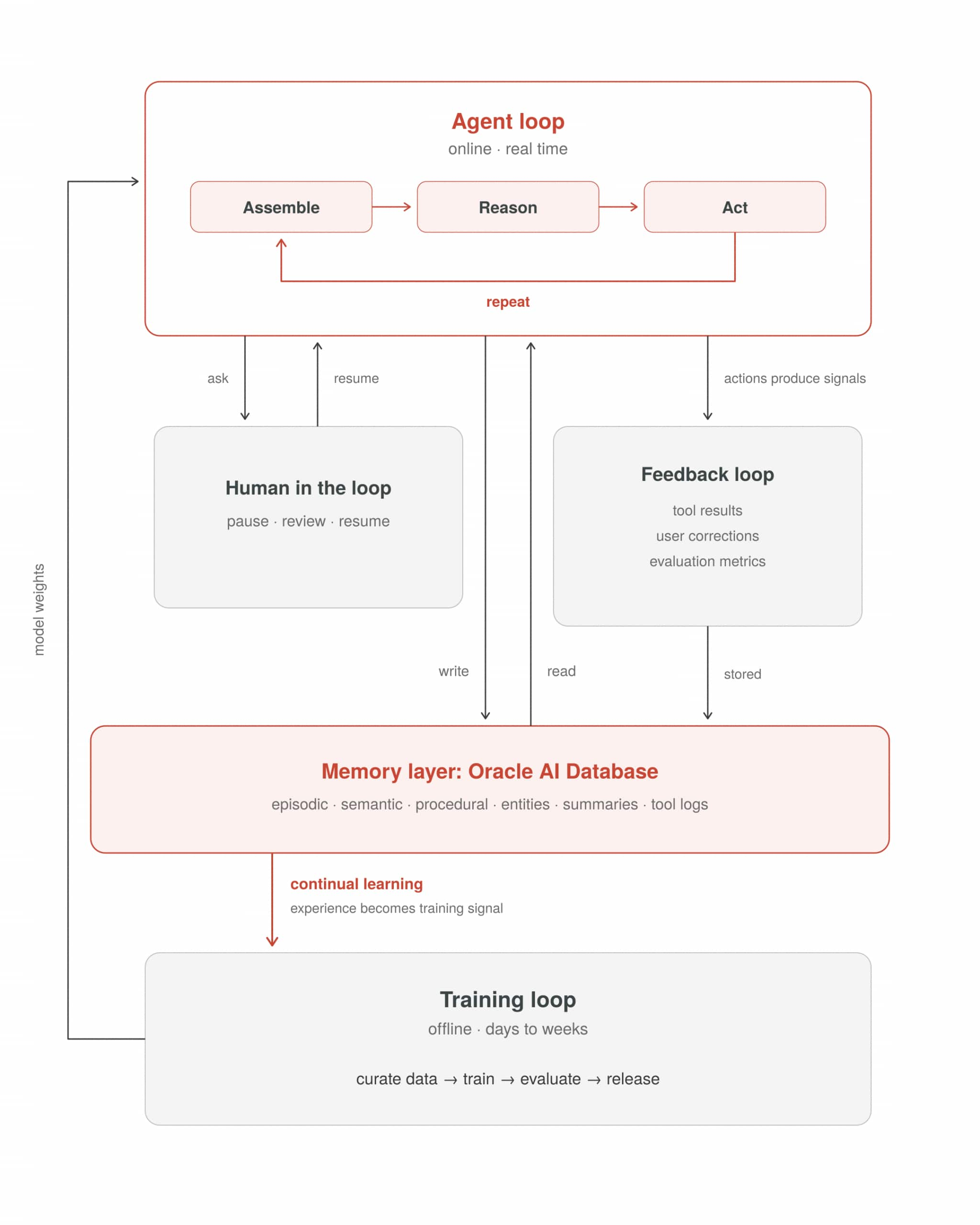
The training loop
The training loop is the cycle that produced the model in the first place: data collection, gradient updates, evaluation, and release. It operates offline, at a timescale of days or weeks, on curated datasets. The agent loop operates online, in real time, on live interactions.
Today these two loops are largely decoupled. Training happens, weights are frozen, and the agent loop runs on top of those fixed weights. The apparent learning you observe within a session, an agent recalling prior context or adapting to corrections, is not weight updating. It is retrieval. The agent is not learning; it is reading from memory.
This separation defines the boundary of what the agent loop can and cannot accomplish on its own. It can accumulate experience through memory operations. It cannot change the underlying model without a training cycle. Understanding this boundary tells you which problems belong to memory engineering and which require retraining.
The feedback loop
Every action the agent takes produces feedback. Tool results are feedback. User corrections are feedback. Evaluation metrics (hallucination rate, task completion, citation accuracy) are feedback at a system level.
At Level 3, the agent harness begins to make the feedback loop explicit and instrumentable. The notebook’s context window growth chart is a primitive example: watching whether token counts stabilize across runs tells you whether your context engineering is actually working. More sophisticated systems route evaluation signals back into memory stores, marking retrieved content as reliable or unreliable based on downstream outcomes, and gradually improving retrieval quality without retraining.
The feedback loop is what turns an agent into a system that improves over time. Without it, every invocation starts from the same baseline regardless of what the agent has done before.
Human in the loop
Long-horizon tasks regularly reach decision points where the agent lacks the information, authority, or confidence to proceed without human input. The human-in-the-loop pattern introduces a pause condition: the agent surfaces a question or proposed action, waits for review or correction, and then continues.
This is a stop condition of a different kind. Rather than halting because the task is finished, the loop pauses because it has reached the boundary of its autonomous authority. Designing this well involves two things: knowing in advance where those boundaries should sit for a given workflow, and ensuring the agent communicates specifically when it reaches one. A generic request for help is insufficient. The agent must surface a precise description of what information or decision is blocking progress.
Human-in-the-loop is not a safety net for when the agent fails. It is a deliberate architectural decision about where human judgment adds the most value in a system. The agent loop handles what can be reasoned about autonomously. The human loop handles what requires authority, context, or accountability that the agent does not have.
Where This Is Going
The agent loop, the training loop, and the feedback loop are currently operated as separate engineering concerns. That separation is practical, not fundamental. As agents accumulate experience across millions of runs, the information they generate (episodic memories, entity
graphs, workflow patterns, evaluation signals, context growth traces) becomes a training signal. The training loop will eventually consume the output of the agent loop, closing the circle.
When that happens, the quality of the memory layer becomes the quality of the training data. Agents with well-engineered memory (clean episodic records, accurately extracted entities, reliable retrieval signals) produce better training signals than agents that let context accumulate without structure.
This convergence has a name. Continual learning is the ability of a model to acquire new knowledge and capabilities from a stream of incoming data over time, without retraining from scratch and without catastrophically forgetting what it has already
learned. It is a formal machine learning discipline, not a metaphor, and it is the bridge between the two loops: the agent loop generates the experience, and continual learning is the process by which the training loop absorbs that experience into model weights.
Continual learning in agentic systems is the capacity of an agent to improve over time through the accumulation of high-signal memory units, with the extracted signal applied across three optimization surfaces: token space, weight space, and latent space.
The Union of the Agent Loop and the Training Loop
What connects them is the memory layer.
Oracle AI Database serves as the agent memory core, providing vector search, relational storage, and graph capabilities in a single engine. Memory operations that run inside the agent loop (encoding, storing, retrieving, injecting, and forgetting) produce a durable record of agent experience.
Oracle OCI provides the platform for continuous learning: the infrastructure to retrain models on that accumulated experience at scale, closing the loop from runtime behaviour back into model weights.
The agent loop and the training loop are converging. The memory layer is where they meet.
For engineers building agents today, this means the decisions made about memory architecture are not just operational decisions. They are decisions about what the system will be able to learn from tomorrow. A database that can serve low-latency semantic search at runtime can also serve as the data source for a continuous training pipeline.
Design your memory layer accordingly.
FAQ
1. What is the agent loop?
The agent loop is the repeating cycle a harness runs within a single agent turn: assemble context, invoke the model to reason, act on its decision, and repeat until a stop condition ends the run. It exists because long-horizon tasks cannot be completed in a single LLM call.
2. How do you stop an agent loop from running forever?
Define explicit stop conditions in the harness: a terminal message with no pending tool calls, a goal-completion check, an iteration cap, a wall-clock timeout, unrecoverable errors, and failure mode detection such as the agent repeating the same tool call with identical arguments.
3. What is the difference between a memory-augmented agent and a memory-aware agent?
A memory-augmented agent retrieves and injects information into context but does not manage it; memory is something that happens to the agent. A memory-aware agent encodes, stores, retrieves, injects, and forgets, actively managing its cognitive state within each run and across sessions.
4. How do I know which level my agent system sits at?
If there is no persistence beyond the context window, it is Level 1. If memory is read before the model call and written after the agent acts, it is Level 2. If there is a deliberate boundary between programmatic and agent-triggered operations, with techniques such as compaction, tool output offloading, and semantic tool discovery, it is Level 3.
5. What connects the agent loop to the training loop?
The memory layer. Agent runs generate experience: episodic records, entities, workflows, and evaluation signals. With continual learning, that experience becomes training signal. Oracle AI Database stores and serves it inside the agent loop; Oracle OCI provides the platform to retrain models on it. The patterns are implemented in the companion notebook.