Key Takeaways
- A working demo is useful evidence, not an adoption decision. A successful first run proves reconciliation in a controlled environment; it does not prove production readiness.
- Choose Oracle Database Operator for Kubernetes when Kubernetes is the right control surface. The pattern is strongest when platform engineers and DBAs want Oracle Database lifecycle intent represented through Kubernetes APIs and are ready to own the surrounding operating model.
- Standardization requires evidence beyond a healthy custom resource. Storage, recovery, security, observability, upgrades, support ownership, and the developer service contract need proof before the operator becomes a supported platform pattern.
- Managed services, existing DBA automation, and manual Kubernetes automation remain valid options. The right question is which model your organization can operate, secure, recover, and support with the least unnecessary risk.
A working demo is evidence, not an adoption decision
A database operator demo can look deceptively complete. You apply a custom resource, the operator reconciles it, a pod appears, a PVC binds, a service is created, and status eventually reports Healthy.
That is good evidence. It is not an adoption decision.
Oracle Database Operator for Kubernetes extends the Kubernetes API with custom resources and controllers for supported Oracle Database lifecycle operations. In platform terms, it lets teams express database lifecycle intent through Kubernetes objects and inspect reconciliation through status, events, logs, and related resources.
That API surface can be valuable. It can make Oracle Database lifecycle intent visible, repeatable, reviewable, and easier to integrate with platform workflows. But adoption depends on the operating model around that API: storage, images, Secrets, RBAC, webhooks, networking, recovery, observability, upgrades, support ownership, and the contract developers will consume.
In this series, we use Oracle Database Operator for Kubernetes v2.1.0 as the release basis for manifests, CRDs, samples, and API fields. Operator APIs and samples are release-specific, so use release-matched manifests and documentation for the version you plan to run.
The adoption question is not only whether Oracle Database can run on Kubernetes. It is whether this organization can support the operator-managed model better than the alternatives. The answer might be to standardize the operator path for defined use cases. It might be to keep piloting. It might be to use a managed Oracle Database service. It might be to rely on existing DBA-led automation. For a narrow non-production case, it might be to use manual Kubernetes automation and keep the support boundary small.
This article turns the first four parts of the series into an adoption review that platform engineers, Kubernetes administrators, DBAs, security teams, storage owners, networking teams, observability teams, and application teams can use.
Use the series evidence to choose an operating model
The first four articles built an evidence chain. They did not build a production certification.
In Part 1, the first run gave evidence for the control loop. The cluster accepted Oracle Database Operator for Kubernetes CRDs. The controller ran. A supported SingleInstanceDatabase sample could be reconciled and inspected. That is the right first test because it answers whether the API extension and controller model work in a controlled environment.
In Part 2, the custom resource became the operating contract. The spec described desired database intent. The status, events, logs, and related Kubernetes resources showed what the operator and cluster reported back. That distinction matters because a custom resource is an operating contract, not a complete runbook. The Kubernetes documentation on custom resources and controllers provides the platform model behind that distinction.
In Part 3, the first-run environment became a platform-readiness inventory. Storage classes, image access, Secrets, RBAC, webhooks, networking, observability, cleanup behavior, and ownership boundaries became part of the evaluation. A healthy object was only one signal.
In Part 4, recovery readiness separated Kubernetes health from database recoverability. For SingleInstanceDatabase, Healthy is evidence that the database is open for connections. That status is useful, but it does not prove backup, restore, RPO, RTO, high availability, or application cutover readiness. Recoverability requires database-level validation, not only Kubernetes health.
Together, those articles showed that Oracle Database lifecycle intent can be exposed and inspected through Kubernetes APIs for supported resources. They also showed that the operator path creates a shared platform and DBA contract.
They did not prove production RPO or RTO, performance under representative load, multi-zone readiness, disaster recovery readiness, patch safety, upgrade safety, security compliance, backup immutability, application cutover readiness, or a complete developer self-service contract.
That gap is not a failure of the demo. It is the adoption work.
Figure 1. A successful first run is the beginning of the evidence chain. Adoption requires platform, recovery, ownership, and developer-contract evidence.
Choose Oracle Database Operator for Kubernetes when Kubernetes is the right control surface
Oracle Database Operator for Kubernetes is a strong fit when Kubernetes is the intended control surface for Oracle Database lifecycle intent and the organization is prepared to own the surrounding database operating model.
This often applies when the workload requires Oracle Database and the platform already uses Kubernetes as the control plane for application and service lifecycle. In that environment, representing database intent as a custom resource gives platform engineers and DBAs a shared API object to review. It also fits teams that already use GitOps, Kubernetes RBAC, namespace boundaries, policy engines, events, and status inspection as part of normal operations.
The operator path is a good candidate when the selected Oracle Database Operator for Kubernetes resource kind supports the lifecycle operations the workload needs. The operator supports multiple Oracle Database resource families and controllers, but lifecycle capabilities are resource-specific. A workflow documented for one resource family should not be assumed for another. Before adoption, verify the installed CRDs, release-specific documentation, controller image, and platform-approved image policy for the resource kind you plan to operate.
For the SingleInstanceDatabase path used earlier in this series, the custom resource lets teams express database configuration and persistence intent through Kubernetes. The operator can reconcile supported resources and report observed state. That is useful, but it does not remove the need for DBA judgment. DBAs still own database configuration standards, patch policy, backup and recovery strategy, capacity planning, performance baselines, security posture, and recovery validation.
The operator path gives teams more Kubernetes-native control and inspectability. The tradeoff is that more operational responsibility remains inside the organization. Platform teams must operate CRDs, controller deployments, RBAC, webhooks, certificate-management dependencies, image access, registry policy, storage classes, namespace scope, and upgrade paths. DBAs must decide which lifecycle operations belong in the custom resource and which remain in database runbooks.
Release manifests are useful for evaluation, but long-lived environments need an approved image policy: pinning or mirroring where required, image scanning, pull Secret handling, rollback planning, and registry access that matches the organization’s governance model.
Choose the operator path when Kubernetes is the right control surface, not merely because Kubernetes is available.
Choose a managed Oracle Database service when the team wants less platform ownership
A managed Oracle Database service may be the better operating model when the application needs Oracle Database capabilities but does not need database lifecycle represented inside Kubernetes.
This is often the more straightforward production path when the application can consume an external Oracle Database endpoint. Instead of owning data-bearing pods, PVC behavior, image pull policies, registry access, webhooks, operator upgrades, and cluster-level database dependencies, the team works with a database service operating model.
Managed Oracle Database services to evaluate include options such as Oracle Autonomous AI Database Serverless and Oracle Base Database Service. If the decision also includes broader Autonomous Database variants, Exadata-based services, or Oracle Database services integrated with another cloud provider, evaluate those services against their current documentation and responsibility model before treating them as equivalent options. The right choice depends on workload, location, governance, operational requirements, and service-specific capabilities.
A managed service may fit better when backup, restore, patching, scaling, monitoring, encryption, identity, and lifecycle operations align more closely with service APIs and cloud operations than with Kubernetes custom resources. Evaluate those capabilities in the documentation for the specific service and configuration you plan to use. Do not assume every managed service exposes the same lifecycle model or responsibility boundary.
Managed services can reduce direct infrastructure and lifecycle ownership. They do not remove application architecture, data governance, access control, cost management, schema design, migration planning, or operational accountability. Teams still need to decide who owns network connectivity, identity, credential use, application failover behavior, data retention, audit requirements, and incident response.
The adoption question is not “operator or managed service, which is better?” The better question is “which operating model lets this organization prove recovery, security, support, and developer expectations with less risk?”
Use existing DBA automation or manual Kubernetes automation when the ownership model is stronger
Existing DBA automation should be evaluated as a first-class alternative, especially when it already proves recovery and compliance requirements. Many organizations have mature Oracle Database operations built around RMAN, Data Pump, Data Guard, storage snapshots, enterprise backup platforms, patching runbooks, monitoring, auditing, change management, and incident response.
If those processes already meet production requirements, the operator evaluation should show how Kubernetes-managed Oracle Database resources fit into that model rather than replacing it by assumption. DBA-led automation may be the stronger path when the platform team is not ready to own stateful database operations inside Kubernetes, when production runbooks are already audited and reliable, or when introducing a new reconciliation loop adds uncertainty without a clear lifecycle benefit.
Manual Kubernetes automation can also be reasonable in narrow cases. A team might use StatefulSets, PVCs, Services, Jobs, CronJobs, Helm charts, Kustomize overlays, or scripts for temporary environments, non-production use cases, or highly customized workflows the operator does not expose. This can be useful when the team needs only a small Kubernetes wrapper around a DBA-owned process.
The tradeoff is that manual automation usually shifts reconciliation logic, idempotency, error handling, drift detection, retry behavior, and support burden back to the platform or DBA team. Simpler object creation is not the same as a safer lifecycle model. Kubernetes documentation for Persistent Volumes, Storage Classes, Services, and NetworkPolicies is useful background, but these primitives do not create a complete database operating model by themselves.
Other database operators can be useful developer-experience benchmarks, especially around backup, restore, high availability, and observability. They are not drop-in replacements for Oracle Database workloads unless the application and organization are prepared for a database-engine migration.
Kubernetes data-protection tools can complement the operator path, but they do not remove the need for Oracle-aware recovery validation. A restored namespace, running pod, or bound PVC is not the same as a validated Oracle Database restore.
Figure 2. The operator path is strongest when Kubernetes is the right control surface and the organization is ready to own the surrounding platform responsibilities.
Require production evidence before standardizing the pattern
Standardization should be based on evidence across the operating model, not on a single healthy custom resource.
Before Oracle Database Operator for Kubernetes becomes a standard platform pattern, require evidence across eight adoption gates. Each gate should have an owner, an artifact the team can review, and a clear statement of what remains outside the evidence.
Gate 1: Platform foundation
The platform foundation gate shows that the operator control plane is installed, inspectable, and owned. Review whether the installed CRDs match the selected release, the operator deployment and pods are healthy, webhook and certificate-management dependencies are understood, RBAC has been reviewed, watch scope is documented, and the operator namespace, resource limits, image policy, and upgrade path have owners.
This gate belongs primarily to platform engineering, Kubernetes administrators, and security. It confirms that the operator control plane exists and can be inspected. It does not prove that the database is recoverable, secure, performant, or approved for production.
Gate 2: Database lifecycle fit
The database lifecycle gate shows that the selected custom resource can represent the workload’s intended lifecycle. Build the operation list from the release-specific documentation for the selected resource kind, edition, and database version. Confirm which operations are supported for that exact path, such as create, configuration update, patching, scaling, deletion, cloning, Data Guard-related workflows, or other release-specific workflows. Do not infer that a workflow documented for one resource family, edition, or sample applies to another. Test failure behavior in non-production, and document immutable fields, edition-specific limits, and operations that remain outside the operator.
This gate belongs to DBAs, platform engineering, and application technical leads. It confirms that the custom resource can serve as the intended lifecycle contract. It does not mean every database operation is automated or safe for production.
Gate 3: Storage and data persistence
The storage gate shows that the platform understands where data lives and how storage behaves. Review the approved StorageClass, access mode, capacity model, expansion behavior, reclaim policy, snapshot or backup consistency model, deletion behavior for custom resources, PVCs, PVs, and namespaces, performance expectations, durability expectations, and escalation path.
This gate belongs to storage teams, platform engineering, and DBAs. It confirms that the team can explain the storage layer. It does not prove Oracle Database consistency or restore success.
Gate 4: Recovery evidence
The recovery gate shows that the team can restore the workload under rehearsed conditions. Select a recovery mechanism for the resource kind and workload. That may be an operator-supported resource workflow, a managed-service workflow, or an external DBA or platform recovery method. Rehearse restore into a safe target. Validate with a database-level marker row or another DBA-approved check. Measure RPO and RTO instead of assuming them. Document backup artifacts, retention, encryption, restore permissions, and restore ownership.
This gate belongs to DBAs, platform engineering, application owners, security, and compliance. It proves recoverability under tested conditions, not coverage for every possible failure mode. Recovery approval requires database-level validation, not only Kubernetes health.
Gate 5: Security and access
The security gate shows that access and credentials have an operating model. Decide who can create, update, or delete database custom resources; who can read or update database Secrets; who can view operator logs; whether manifests reference Kubernetes Secrets directly or the platform populates those Secrets from OCI Vault or a third-party vault through an approved integration; how credential rotation works; how image pull Secrets are handled; how network segmentation is enforced; and how admission controls or policy engines apply.
A Kubernetes Secret reference is a delivery mechanism, not a full credential-management policy. This gate belongs to security, platform engineering, DBAs, and networking. Useful background includes the Kubernetes documentation on Secrets, RBAC, and admission controllers.
Gate 6: Observability and support
The observability gate shows that teams can detect and triage problems. Confirm access to custom resource status, conditions, events, pod logs, operator logs, database-native logs, database metrics, alerts, dashboards, and incident workflows. Understand Kubernetes event retention limits. Document support handoffs across Oracle Database, the operator, Kubernetes, storage, networking, registry access, and cloud services.
This gate belongs to platform engineering, SRE or operations, DBAs, and support management. Kubernetes Events are useful signals, but they are not durable audit history by themselves.
Gate 7: Upgrade and fallback
The upgrade gate shows that the pattern can be maintained after adoption. Test the operator upgrade path, review CRD upgrade impact, check compatibility for existing custom resources, and rehearse database patch and rollback or fallback workflows for the selected resource kind and edition. Plan backup or restore points before upgrades, and test application-impact scenarios before making the pattern broadly available.
This gate belongs to platform engineering, DBAs, release engineering, and change management. It creates a maintenance model; it does not make every future upgrade risk-free.
Gate 8: Developer service contract
The developer contract gate shows that application teams know what the platform provides and what it does not. Document the request path, approval flow, naming standards, supported versions, approved storage choices, connection information delivery, credential delivery, internal SLO or SLA expectations, backup and restore expectations, maintenance behavior, failover behavior, restore behavior, and changes that require DBA or platform approval.
Most application teams should not directly own production SingleInstanceDatabase manifests unless the organization intentionally makes that the contract. A safer default is a platform-owned template, GitOps workflow, or service request process with DBA and security review.
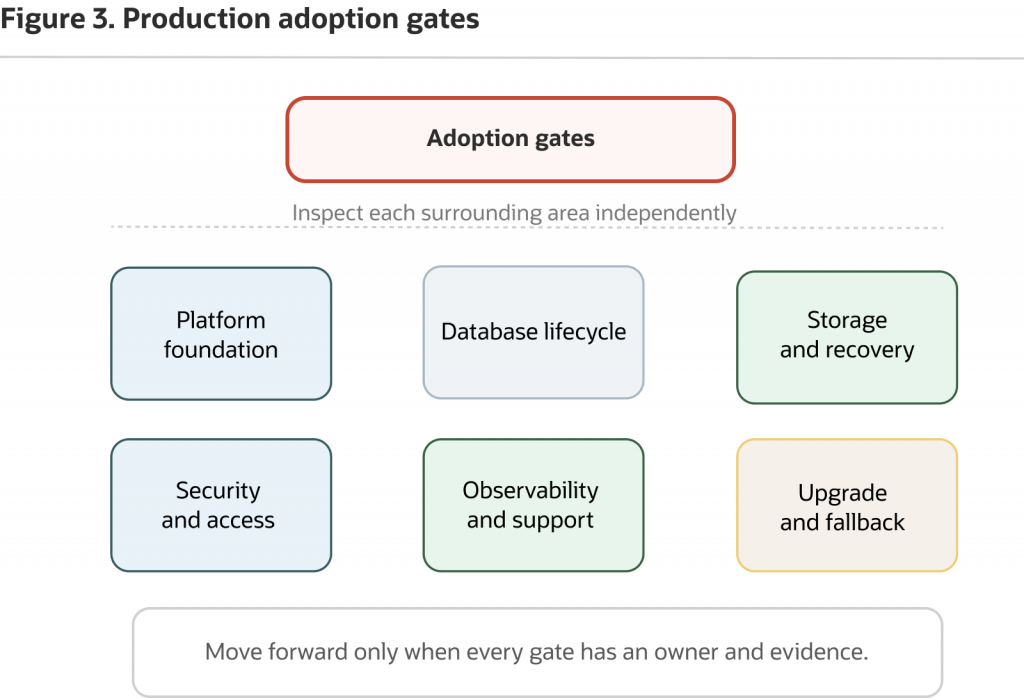
Figure 3. Standardize only after each gate has evidence, owners, and a runbook or decision.
Collect a compact adoption evidence snapshot
The following commands are not a production checklist. They are a compact, read-only evidence snapshot to help platform engineering, DBAs, security, storage, networking, observability, and application teams discuss whether the operator path is ready for the next rollout stage.
Assume a Linux/Bash environment, kubectl, a non-production Kubernetes cluster, Oracle Database Operator for Kubernetes already installed, and a test SingleInstanceDatabase named freedb-lite-sample in the oracle-db-operator-demo namespace. The release-tagged Free Lite sample uses metadata.namespace: default; these commands assume your test resource has been applied or copied into oracle-db-operator-demo, or that you adjusted the namespace variables for your environment.
The operator namespace in these examples is oracle-database-operator-system, and the operator deployment is oracle-database-operator-controller-manager. Names may vary by installation.
Set variables for the example names before running the snapshot:
export OPERATOR_NS="oracle-database-operator-system"
export OPERATOR_DEPLOYMENT="oracle-database-operator-controller-manager"
export DB_NS="oracle-db-operator-demo"
export SIDB_NAME="freedb-lite-sample"
export ADMIN_SECRET="freedb-admin-secret"Start with the operator API and control plane:
kubectl api-resources --api-group=database.oracle.com
kubectl get crds | grep -i 'database.oracle.com' || true
kubectl get deployments -n "$OPERATOR_NS"
kubectl get pods -n "$OPERATOR_NS"This tells you whether the operator API resources are discoverable, CRDs exist, and the operator deployment and pods are present. It does not prove production readiness, correct RBAC, recovery readiness, storage suitability, Secret-management readiness, image-governance readiness, or upgrade safety.
If your adoption review depends on the SingleInstanceDatabase API shape, inspect the CRD directly:
kubectl get crd singleinstancedatabases.database.oracle.com
-o jsonpath='{.spec.group}{"n"}{.spec.names.kind}{"n"}{.spec.names.plural}{"n"}{.spec.scope}{"n"}{.spec.versions[*].name}{"n"}'For the v2.1.0 release basis used in this series, the expected shape is:
database.oracle.com
SingleInstanceDatabase
singleinstancedatabases
Namespaced
v1alpha1 v4If you need to confirm which CRD version is the storage version, inspect the version flags:
kubectl get crd singleinstancedatabases.database.oracle.com
-o jsonpath='{range .spec.versions[*]}{.name}{" served="}{.served}{" storage="}{.storage}{"n"}{end}'This confirms the CRD shape for the release basis used in this series. It does not prove the controller image matches the CRD release, the sample manifest is appropriate for your environment, or the resource kind supports every lifecycle operation you need.
Next, inspect the database custom resource and related platform resources:
kubectl get singleinstancedatabases.database.oracle.com -n "$DB_NS"
kubectl describe singleinstancedatabases.database.oracle.com "$SIDB_NAME"
-n "$DB_NS"
kubectl get pod,pvc,svc -n "$DB_NS"
kubectl get events -n "$DB_NS" --sort-by='.metadata.creationTimestamp'
kubectl get storageclassThese commands are most useful in a dedicated demo namespace. In a shared namespace, the output can include unrelated resources; use your platform’s approved labels or inventory process to associate pods, PVCs, and services with the database custom resource.
This surfaces declared state, observed state, namespace events, workload resources, storage resources, services, and available storage classes. Event retention and ordering are cluster-dependent, so treat events as troubleshooting signals, not durable audit history. A bound PVC tells you that Kubernetes attached storage. It does not prove Oracle Database consistency, restore success, storage performance, long-term durability, backup coverage, or network approval.
If your kubectl get output includes a database version column, treat it as environment-specific. For example, a mutable image tag such as latest-lite can resolve differently over time or across environments, so do not encode a fixed database version in documentation or automation unless your image policy pins it.
Now inspect status without treating it as approval:
kubectl get singleinstancedatabases.database.oracle.com "$SIDB_NAME"
-n "$DB_NS"
-o jsonpath='{.status.status}{"n"}'If reconciliation succeeded, the output may be:
HealthyFor SingleInstanceDatabase, Healthy is evidence that the operator reports the database as open for connections. It is not backup approval, restore approval, high-availability approval, security approval, performance approval, patch approval, upgrade approval, or production approval.
A short recovery-evidence gap check can reinforce that distinction:
kubectl api-resources --api-group=database.oracle.com | grep -Ei 'backup|restore' || trueIf backup or restore resources appear, verify which resource family they apply to. Backup and restore capabilities are resource-specific and release-specific. Discovery output may show one served API version while the CRD stores another, so inspect the CRD version flags before interpreting capability or compatibility. A Healthy SingleInstanceDatabase does not prove that the team has selected, rehearsed, and validated a recovery mechanism for that workload.
When platform access allows it, inspect recent operator logs:
kubectl logs -n "$OPERATOR_NS"
deployment/"$OPERATOR_DEPLOYMENT"
--all-containers=true
--tail=200This shows whether recent controller logs are available for troubleshooting. It does not prove durable audit history, database-level correctness, backup success, restore success, or compliance-ready log retention. Keep log output short and redact sensitive operational details before sharing logs in tickets, demos, or documentation.
Finally, inspect Secret metadata and RBAC without exposing credential values:
kubectl get secret "$ADMIN_SECRET" -n "$DB_NS"
kubectl describe secret "$ADMIN_SECRET" -n "$DB_NS"
kubectl get role,rolebinding -n "$DB_NS"
kubectl get clusterrole,clusterrolebinding | grep -Ei 'oracle|database-operator|database.oracle.com' || trueThis confirms that the referenced Secret object exists, Secret metadata and key names can be inspected without printing values, and obvious namespace or cluster RBAC objects can be discovered. The Secret key name depends on your Secret design; SingleInstanceDatabase examples commonly use oracle_pwd. Do not print or decode Secret values during an adoption review.
These commands do not prove least privilege. Customized installations may use names that do not match the grep pattern, so a real RBAC review must inspect the service accounts, roles, cluster roles, bindings, and effective permissions used by the installed operator.
The value of this evidence snapshot is not that it approves production. It gives the adoption review a shared fact base: what is visible, what is owned, and what remains unproven.
Assign ownership before developers depend on the service
The operator path is not ready for developer self-service until ownership is assigned across platform engineering, DBAs, security, networking, storage, observability, operations, and application teams.
Platform engineering owns the Kubernetes side of the pattern: operator installation, CRDs, controller deployments, RBAC, service accounts, namespace scope, webhooks, webhook certificate-management dependencies, cert-manager if that is the installed certificate-management path, image registry access, image pinning and scanning policy, pull Secrets, storage-class integration, network exposure patterns, cluster observability, alert routing, and operator upgrades.
DBAs own the database side of the pattern: database configuration intent, edition and version choices, SID and PDB naming standards, patch policy, backup and recovery strategy, recovery validation, database-level security, roles, privileges, auditing, encryption posture, performance baselines, capacity planning, cloning policy, and data retention.
Security owns or approves the Secret and vault integration pattern, RBAC review, admission controls, image security requirements, network segmentation, audit requirements, credential rotation, break-glass procedures, data classification, and compliance controls.
Storage teams own or approve storage classes, capacity tiers, performance tiers, reclaim policy, expansion, snapshots when used, restore semantics, and data deletion procedures. Networking teams own or approve service type decisions, load balancer policy, DNS, firewall rules, NetworkPolicy or equivalent segmentation, and TLS or TCPS routing requirements.
Observability, SRE, or operations teams own alert routing, dashboard ownership, incident triage, log retention, escalation paths, and on-call handoffs. Developers own application connection behavior, retries, failover handling, schema migration coordination, test data requirements, declared service requirements, safe consumption of credentials and connection strings, and participation in recovery or maintenance rehearsals.
This ownership model should be written down before application teams depend on the service. Without it, the platform may appear self-service on day one and become ambiguous during the first incident.
Roll out the operator path in stages
Standardization should be the result of repeated evidence across representative environments, not the result of one successful demo.
A lab evaluation should prove only the control loop. The exit evidence is simple: the operator is installed in non-production, one supported sample reconciles, and status, events, logs, pods, PVCs, and services are inspectable. Avoid claiming production readiness at this stage.
An internal pilot should test the operating model with platform, DBA, security, storage, networking, observability, and developer participation. Exit evidence should include an approved storage class, approved image path, Secret workflow, RBAC model, network exposure model, selected recovery mechanism, and basic observability.
A production-candidate pattern turns the pilot into a repeatable platform offering. Exit evidence should include templates or a GitOps workflow, change approval path, recovery rehearsal, upgrade rehearsal, runbooks, support model, and developer contract. “Production candidate” is an internal evaluation state, not a vendor certification.
A limited production workload should be low risk and run under the real support model. Exit evidence should include incidents and changes handled through normal process, restore tested or validated according to policy, monitoring and alerting used in practice, and ownership boundaries confirmed.
A standard platform pattern should be an approved option for defined use cases. Exit evidence should include documented eligibility criteria, repeatable provisioning, tested recovery, upgrade plan, security approval, support coverage, and a developer-facing contract.
The final stage is reassessment or exit. If recovery cannot be proven, ownership remains unclear, security gates fail, upgrades are not supportable, a managed service fits better, or existing DBA automation is stronger, stop widening the pattern and choose the safer operating model.
Make the adoption decision explicit
The next step is not another demo. The next step is an adoption review that names the operating model, evidence gaps, owners, rollout stage, and decision.
Standardize Oracle Database Operator for Kubernetes as an approved platform pattern only when the selected resource supports the required lifecycle, storage and recovery evidence exist, RBAC and Secret handling are approved, observability and support handoffs are documented, upgrade and fallback have been rehearsed, a recovery rehearsal has succeeded, and the developer service contract is published.
Continue as a limited pilot when the first-run and custom-resource model works but some production gates remain open. This is the right outcome when the team needs more evidence for recovery, upgrades, observability, cost, security, or support handoffs. The pattern may still be useful for development and test while production evidence matures.
Use a managed Oracle Database service when the workload needs Oracle Database but not in-cluster lifecycle control, and when the managed service better satisfies recovery, patching, scaling, compliance, or operational ownership needs. This is often the right choice when the application can use an external endpoint and the platform team wants less direct responsibility for stateful Kubernetes database operations.
Use existing DBA automation when mature Oracle Database operations are already better aligned with production requirements. If existing runbooks prove backup, restore, patching, monitoring, retention, encryption, audit, and support requirements, the operator path should earn its place rather than displacing that model by default.
Use manual Kubernetes automation for a narrow case when the workload is temporary, non-production, or highly customized; when the operator does not support the required workflow; or when the team intentionally accepts script ownership without a richer operator contract.
Decline the operator path for a workload when recovery cannot be proven, ownership is unclear, security and access controls are not ready, the workload is too critical for the team’s current Kubernetes database maturity, or another Oracle Database operating model is safer.
A responsible adoption review should end with a written decision: standardize with conditions met, continue piloting with named gaps, use a managed service, rely on existing DBA automation, use manual Kubernetes automation for a narrow case, or decline adoption for the workload.
Bring the evidence from the first four articles. Assign owners to unresolved gates. Decide the next rollout stage.
Oracle Database Operator for Kubernetes can be a strong platform pattern when Kubernetes is the right control surface and the surrounding operating model is proven. If that evidence is not ready yet, the responsible answer is not failure. It is a better decision.
