This is a guide to help you learn how to use variables in Data Transforms. Variables can be used in the following ways:
– Set a fixed value to the variable, or refresh it from a database table and use it in various data flows.
– Branch execution flow in the workflow based on the variable value.
Setup needed
Before you use a variable, it needs to be defined in Data Transforms. Use the variable menu to create a variable and name it appropriately. Note that the scope of the variable is within a project. Navigate to your project and click on the Variables menu.
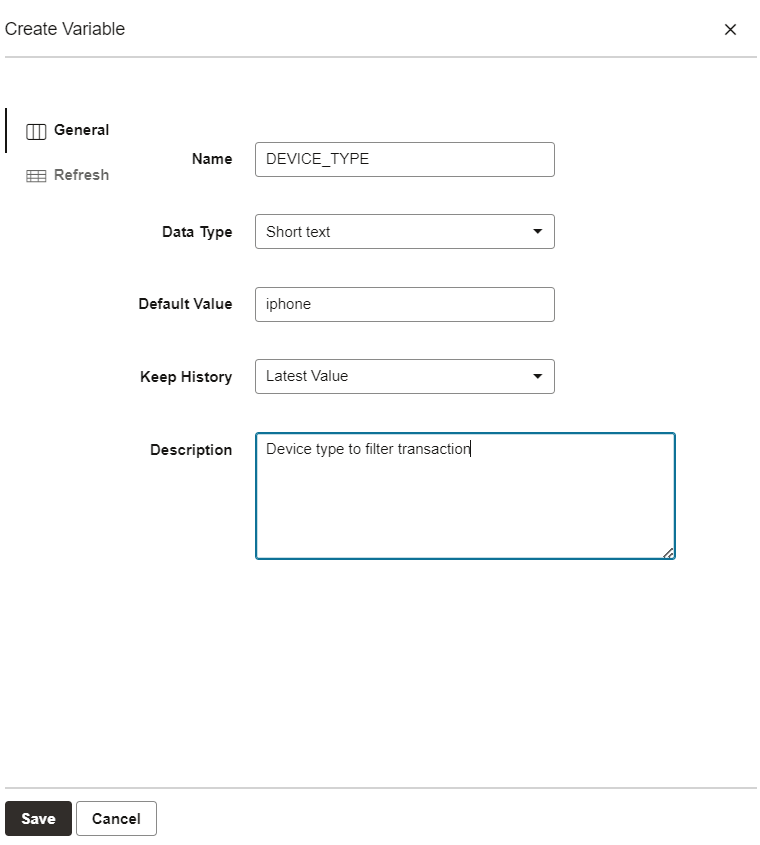
Keeping history for variable is optional and it allows you to look at the variable values for debugging purposes.
Optionally you can write a refresh SQL if you plan to load the variable value from a database table.
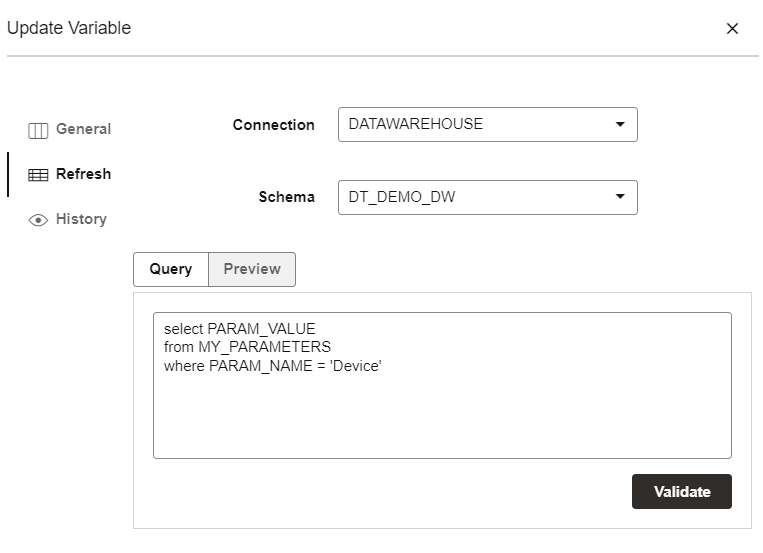
Now the variable has been created and we can use it in the project.
Using the variable in a data flow
Variables can be simply referred to in a data flow by prefixing it with the format #<variable_name>. During execution, it will be substituted by the value.
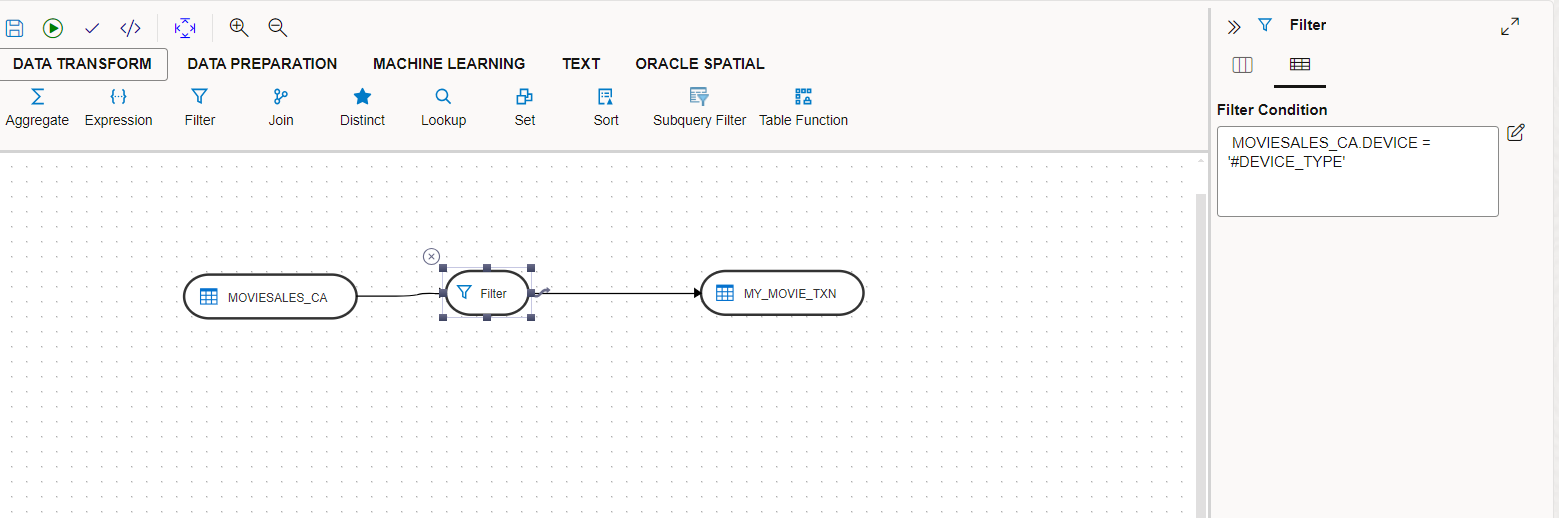
In the following example, the variable DEVICE_TYPE is being used in the filter in a data flow. Note the filter expression:
MOVIESALES_CA.DEVICE = ‘#DEVICE_TYPE’
The variable is quoted since the substituted value need to be quoted. Since the variable value is simply substituted during execution, you can use it creatively in many places. Another common place where it can be used is in the transformation expression in the mapping.
Using the variable in a workflow
In a workflow you can use the variable as a step in the overall flow. For the variable step, you can select the following actions:
- Set a value.
- Refresh a value. It uses the SQL defined in variable definition.
- Evaluate a value. This produces success or failure response that can be used for branching the execution flow.
The following is the example for refreshing the variable.
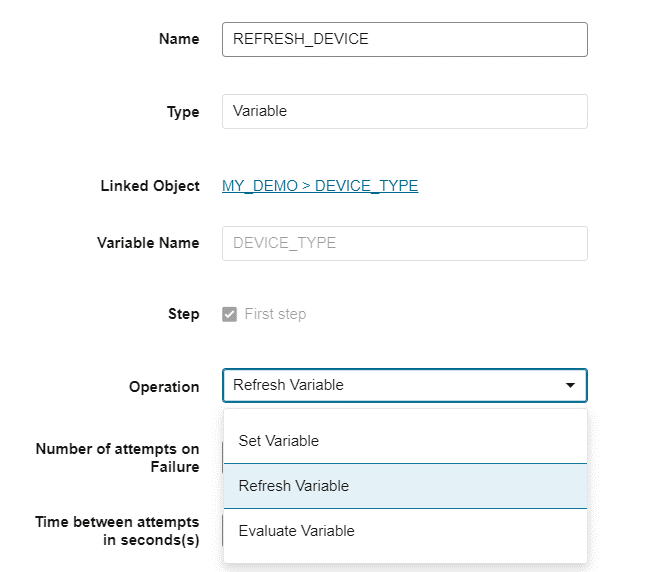
In this example the variable step is being used for evaluation.
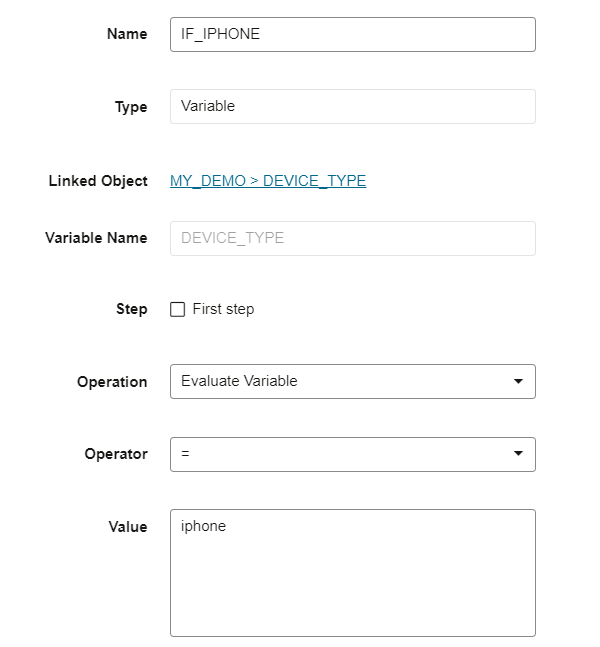
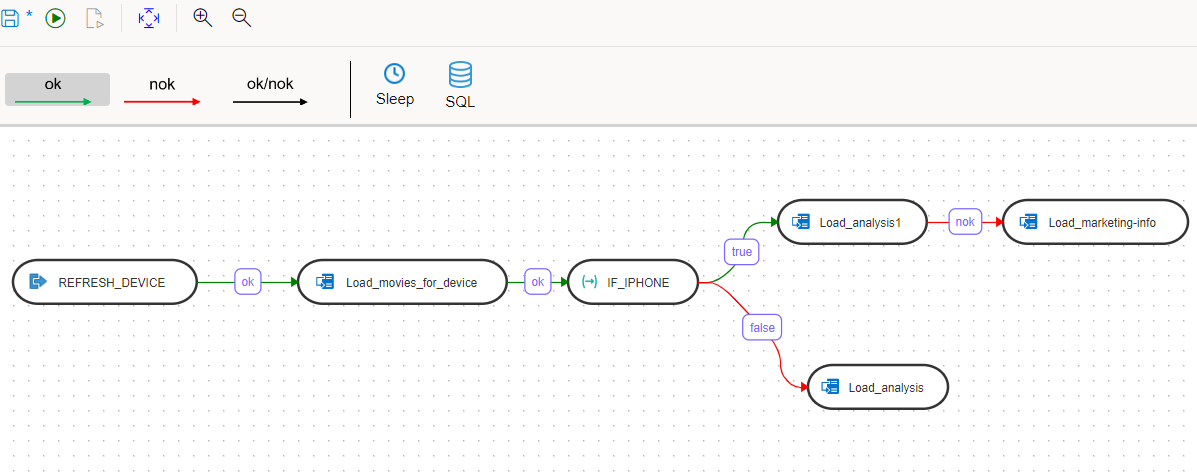
Now we can build the entire workflow. In the following workflow, DEVICE_TYPE variable is being refreshed in the first step (REFRESH_DEVICE) by executing the SQL and the data flow ‘Load_movies_for_device’ is being executed which refers to the DEVICE_TYPE variable in it’s filter step. After that this workflow has a variable evaluation step IF_IPHONE. If the variable value is equal to ‘iphone’ then the execution path for “true” gets executed, else the execution flows to the “false” path.
Conclusion
Variables are essential in developing a complex data pipeline. They can be used in filtering data, transformation expressions and branching execution. The variable values can be set manually or refreshed from a database table. Use it creatively in your data pipeline development.
