One of Big Data SQL’s key benefits is that it leverages the great performance capabilities of Oracle Database 12c. I thought it would be interesting to illustrate an example – and in this case we’ll review a performance optimization that has been around for quite a while and is used at thousands of customers: Materialized Views (MVs).
For those of you who are unfamiliar with MVs – an MV is a precomputed summary table. There is a defining query that describes that summary. Queries that are executed against the detail tables comprising the summary will be automatically rewritten to the MV when appropriate:
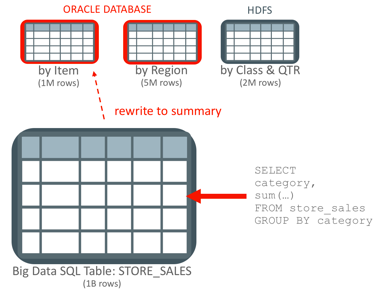
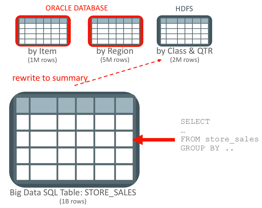
In the diagram above, we have a 1B row fact table stored in HDFS that is being accessed thru a Big Data SQL table called STORE_SALES. Because we know that users want to query the data using a product hierarchy (by Item), a geography hierarchy (by Region) and a mix (by Class & QTR) – we created three summary tables that are aggregated to the appropriate levels. For example, the “by Item” MV has the following defining query:
CREATE MATERIALIZED VIEW mv_store_sales_item
ON PREBUILT TABLE
ENABLE QUERY REWRITE AS (
select ss_item_sk,
sum(ss_quantity) as ss_quantity,
sum(ss_ext_wholesale_cost) as ss_ext_wholesale_cost,
sum(ss_net_paid) as ss_net_paid,
sum(ss_net_profit) as ss_net_profit
from bds.store_sales
group by ss_item_sk
);Queries executed against the large STORE_SALES that can be satisfied by the MV will now be automatically rewritten:
SELECT i_category,
SUM(ss_quantity)
FROM bds.store_sales, bds.item_orcl
WHERE ss_item_sk = i_item_sk
AND i_size in ('small', 'petite')
AND i_wholesale_cost > 80
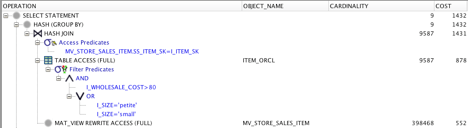
GROUP BY i_category;Taking a look at the query’s explain plan, you can see that even though store_sales is the table being queried – the table that satisfied the query is actually the MV called mv_store_sales_item. The query was automatically rewritten by the optimizer.
Explain plan with the MV:
Explain plan without the MV:
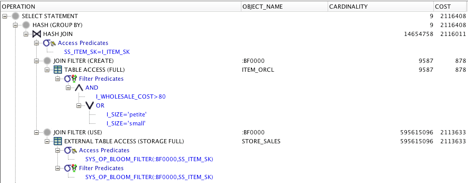
Even though Big Data SQL optimized the join and pushed the predicates and filtering down to the Hadoop nodes – the MV dramatically improved query performance:
- With MV: 0.27s
- Without MV: 19s
This is to be expected as we’re querying a significantly smaller and partially aggregated data. What’s nice is that query did not need to change; simply the introduction of the MV sped up the processing.
What is interesting here is that the query selected data at the Category level – yet the MV is defined at the Item level. How did the optimizer know that there was a product hierarchy? And that Category level data could be computed from Item level data? The answer is metadata. A dimension object was created that defined the relationship between the columns:
|
|
|
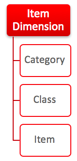
Here, you can see that Items roll up into Class, and Classes roll up into Category. The optimizer used this information to allow the query to be redirected to the Item level MV.
A good practice is to compute these summaries and store them in Oracle Database tables. However, there are alternatives. For example, you may have already computed summary tables and stored them in HDFS. You can leverage these summaries by creating an MV over a pre-built Big Data SQL table. Consider the following example where a summary table was defined in Hive and called csv.mv_store_sales_qtr_class. There are two steps required to leverage this summary:
- Create a Big Data SQL table over the hive source
- Create an MV over the prebuilt Big Data SQL table
Let’s look at the details. First, create the Big Data SQL table over the Hive source (and don’t forget to gather statistics!):
CREATE TABLE MV_STORE_SALES_QTR_CLASS
(
I_CLASS VARCHAR2(100)
, SS_QUANTITY NUMBER
, SS_WHOLESALE_COST NUMBER
, SS_EXT_DISCOUNT_AMT NUMBER
, SS_EXT_TAX NUMBER
, SS_COUPON_AMT NUMBER
, D_QUARTER_NAME VARCHAR2(30)
)
ORGANIZATION EXTERNAL
(
TYPE ORACLE_HIVE
DEFAULT DIRECTORY DEFAULT_DIR
ACCESS PARAMETERS
(
com.oracle.bigdata.tablename: csv.mv_store_sales_qtr_class
)
)
REJECT LIMIT UNLIMITED;-- Gather statistics
exec DBMS_STATS.GATHER_TABLE_STATS ( ownname => '"BDS"', tabname => '"MV_STORE_SALES_QTR_CLASS"', estimate_percent => dbms_stats.auto_sample_size, degree => 32 );Next, create the MV over the Big Data SQL table:
CREATE MATERIALIZED VIEW mv_store_sales_qtr_class
ON PREBUILT TABLE
WITH REDUCED PRECISION
ENABLE QUERY REWRITE AS (
select
i.I_CLASS,
sum(s.ss_quantity) as ss_quantity,
sum(s.ss_wholesale_cost) as ss_wholesale_cost,
sum(s.ss_ext_discount_amt) as ss_ext_discount_amt,
sum(s.ss_ext_tax) as ss_ext_tax,
sum(s.ss_coupon_amt) as ss_coupon_amt,
d.D_QUARTER_NAME
from DATE_DIM_ORCL d, ITEM_ORCL i, STORE_SALES s
where s.ss_item_sk = i.i_item_sk
and s.ss_sold_date_sk = date_dim_orcl.d_date_sk
group by d.D_QUARTER_NAME,
i.I_CLASS
);
Queries against STORE_SALES that can be satisfied by the MV will be rewritten:
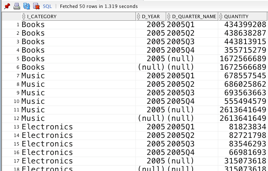
Here, the following query used the MV:
– What is the quarterly performance by category with yearly totals?
select
i.i_category,
d.d_year,
d.d_quarter_name,
sum(s.ss_quantity) quantity
from bds.DATE_DIM_ORCL d, bds.ITEM_ORCL i, bds.STORE_SALES s
where s.ss_item_sk = i.i_item_sk
and s.ss_sold_date_sk = d.d_date_sk
and d.d_quarter_name in ('2005Q1', '2005Q2', '2005Q3', '2005Q4')
group by rollup (i.i_category, d.d_year, d.D_QUARTER_NAME)And, the query returned in a little more than a second:
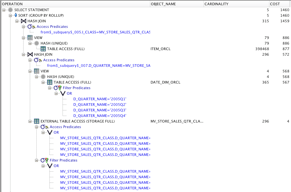
Looking at the explain plan, you can see that the query is executed against the MV – and the EXTERNAL TABLE ACCESS (STORAGE FULL) indicates that Big Data SQL Smart Scan kicked in on the Hadoop cluster.
MVs within the database can be automatically updated by using change tracking. However, in the case of Big Data SQL tables, the data is not resident in the database – so the database does not know that the summaries are changed. Your ETL processing will need to ensure that the MVs are kept up to date – and you will need to set query_rewrite_integrity=stale_tolerated.
MVs are an old friend. They have been used for years to accelerate performance for traditional database deployments. They are a great tool to use for your big data deployments as well!
