Oracle has just released a new AI service that allows customers to uncover insights in unstructured documents powered by deep learning models. This service is called OCI Document Understanding, which allows you to extract text, tables and identify document types among other great capabilities.
Although the AI services are very easy to use, the output is complex to analyze and requires some extra processing to get the desired output. Other providers encourage you to use functions or Python code to analyze, process and consume that information. But, what happens if you need more information in the future? How can this process be simplified?
Using Autonomous Database (JSON, ATP or ADW), you can not only store the JSON output of the AI Services. Any application, business user or data scientist can query and use it! In this blog we are going to use a feature called table extraction, which identifies all the tables in a document and extracts the content in tabular format maintaining the row/column relationship.
The table extraction feature comes with a sample PDF which we are going to use. You can see that there is a small table that automatically is recognized and printed.
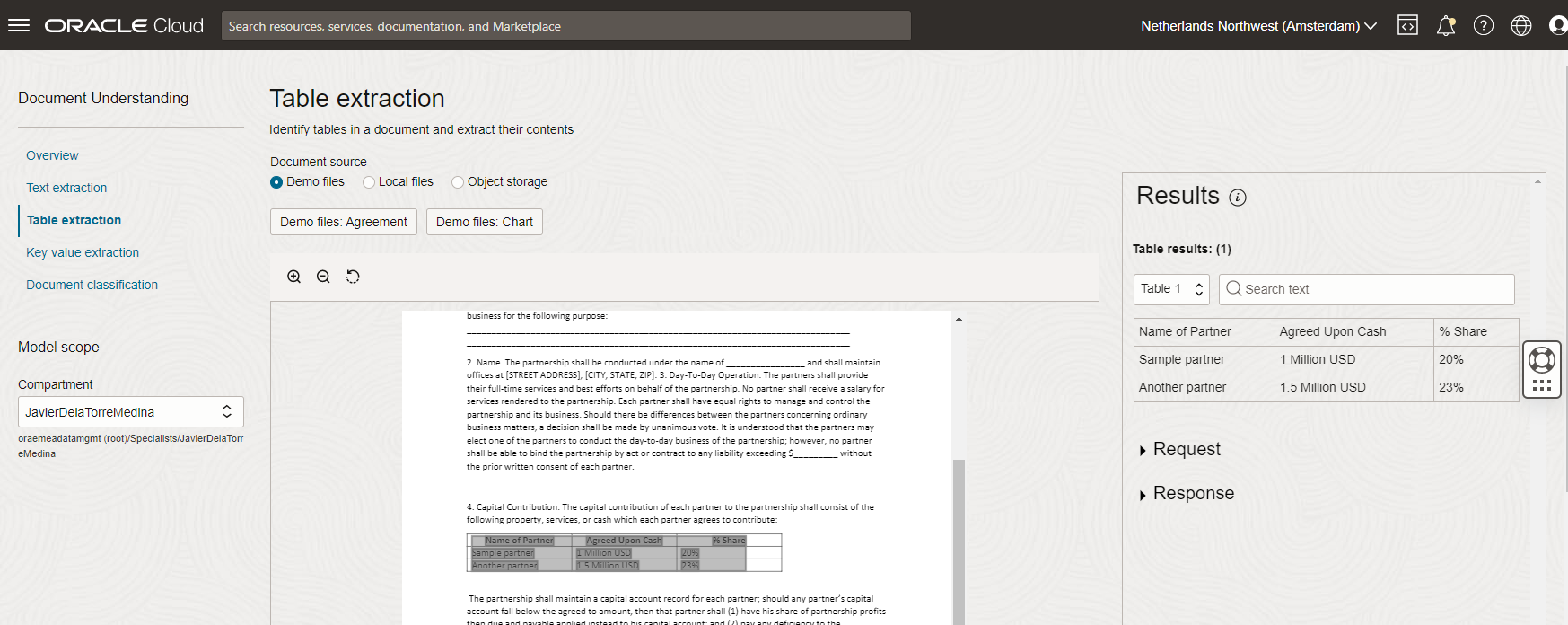
The response you get is a JSON document that contains a lot of useful information about our PDF, but we want to focus just on the table because it has the information we need. You will soon see that the JSON is quite big and complex. Let’s have a look into the structure to better understand how to get the needed information:
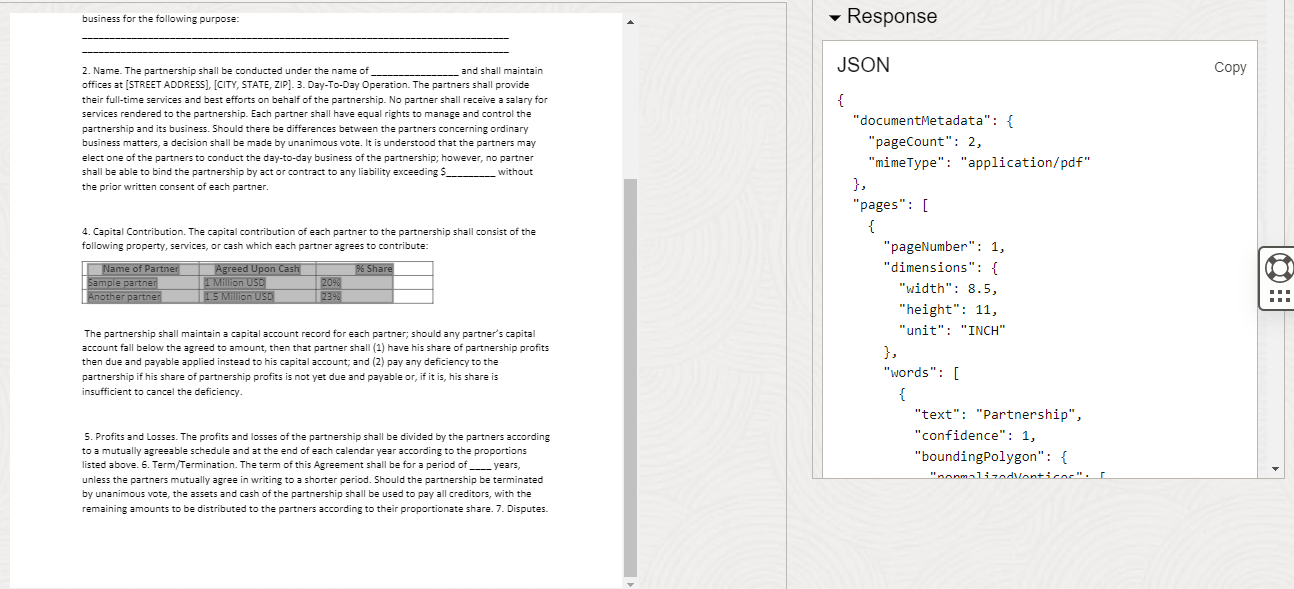
In this case, the PDF is just two pages long, but the table is on the first page. We need the table structure, which already is providing some information like the number of rows and columns. Also you can see the headers and the body rows:
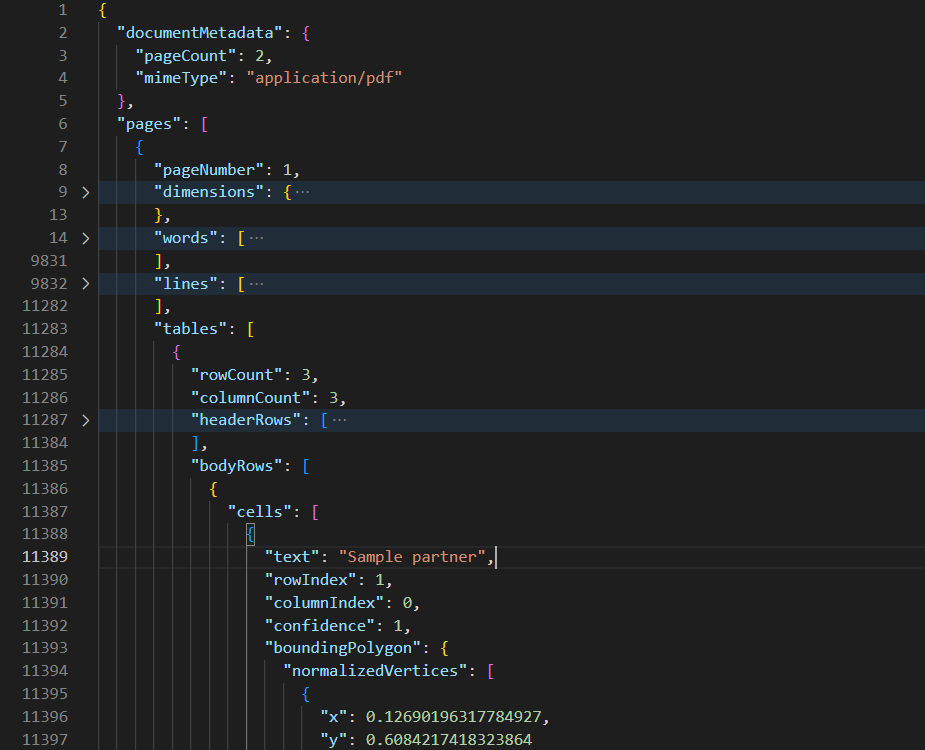
If we have a look into the body rows, each cell of the table is stored in the JSON with a rowIndex and columnIndex. We will need to use these values to navigate the table:
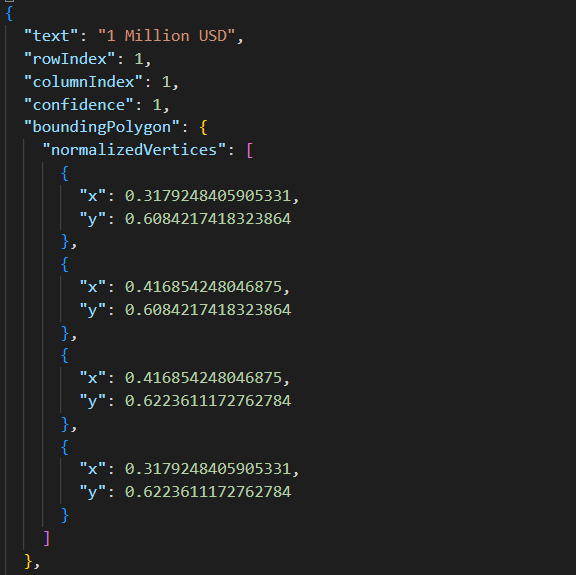
Notice the cells are stored consecutively. It can be tricky to work with these documents; normally, you have to start coding with Python or other languages. However, using Autonomous Database, you can store and analyze them directly! Let’s have a look to the power of Autonomous Database. First, let’s create a new collection:
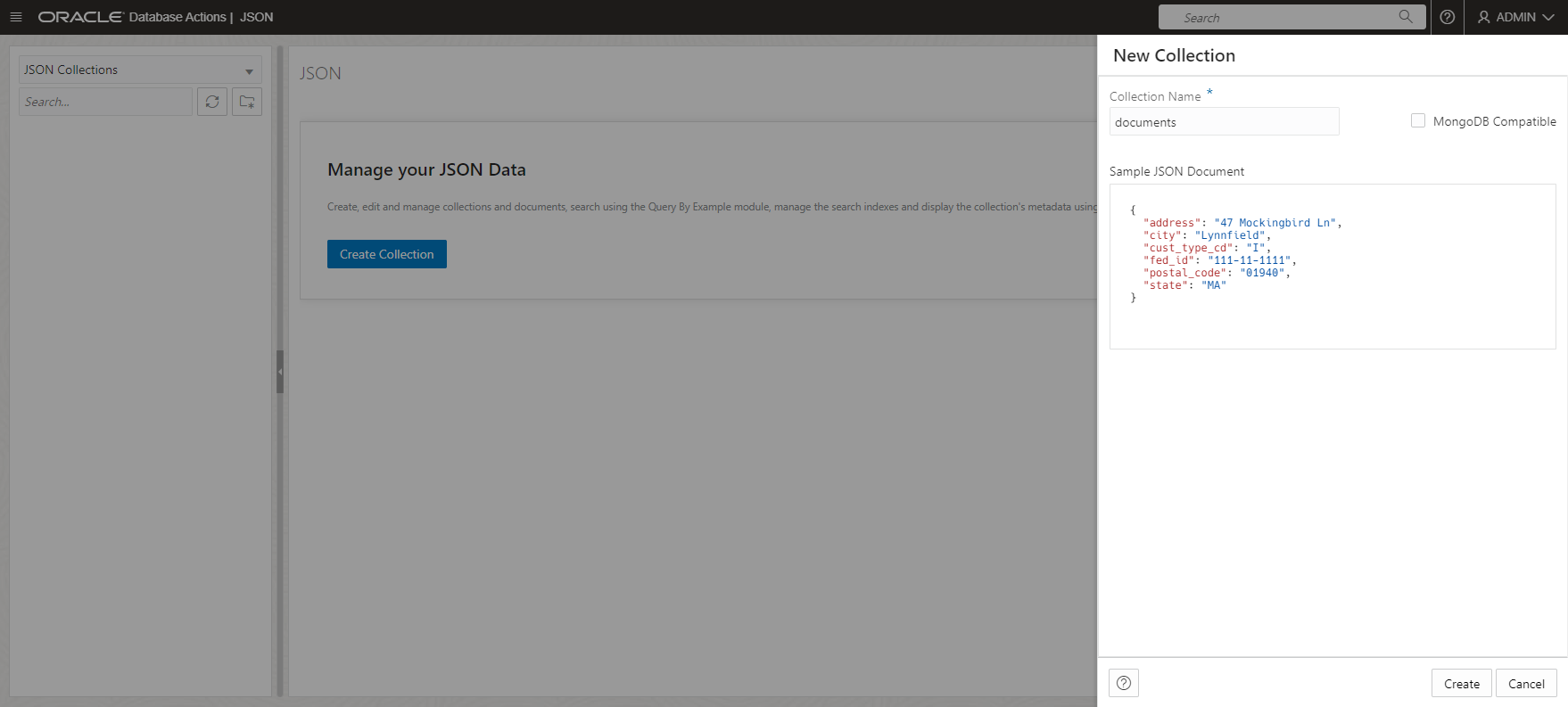
The output of the analysis is normally stored in object storage and there are many ways of consuming object storage data into Autonomous Database – and even automate the ingestion. For this blog, we are just going to copy and paste the JSON to consume it:
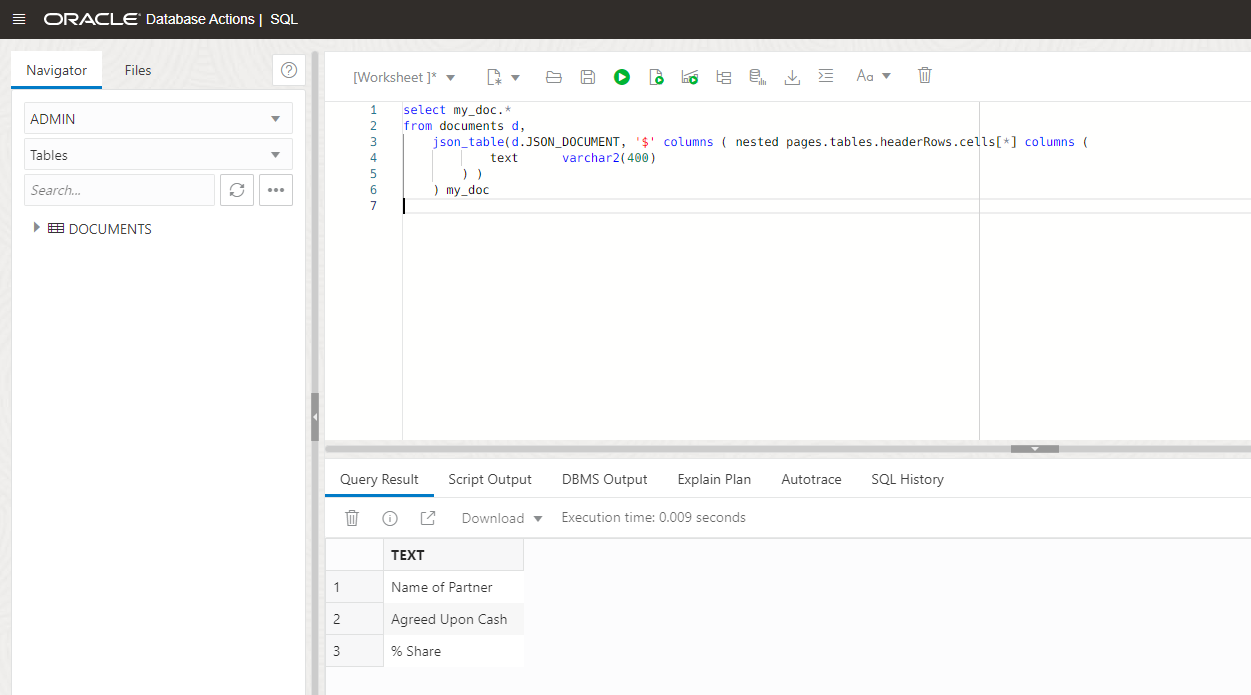
Now we can switch to SQL for analyzing it. The first thing we are going to do is to have a look into the headers. We are going to use the JSON_TABLE function to show the results in a structured way. We can see that is a nested document:
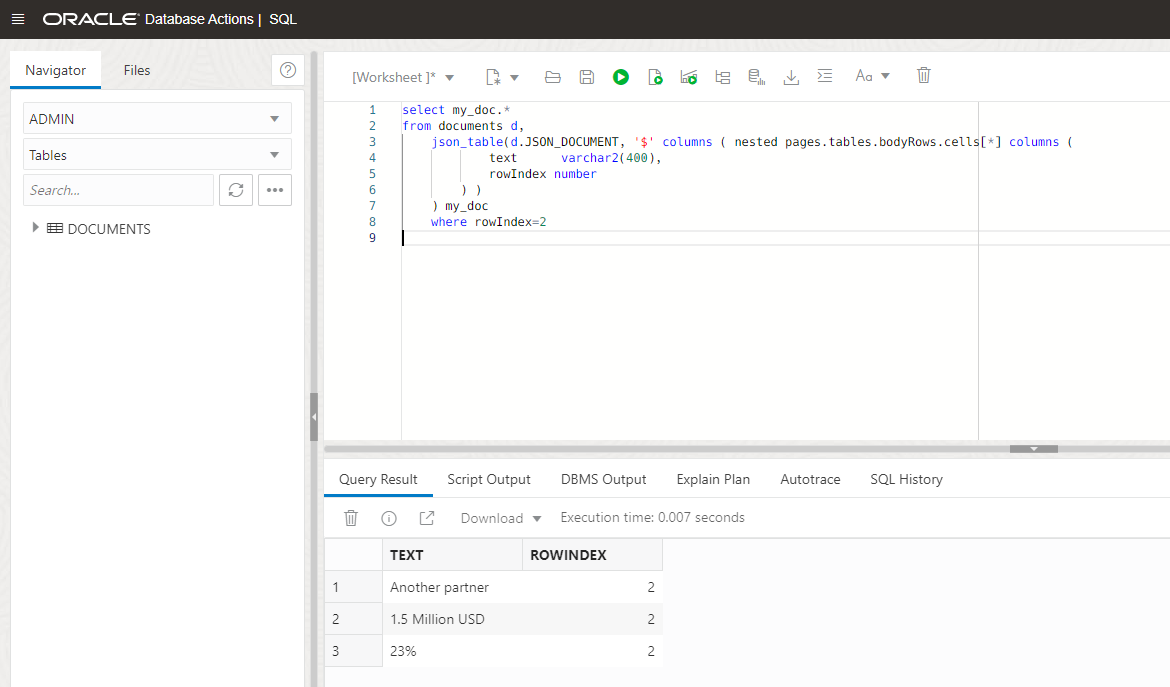
Using the same query, we can change the headerRows with bodyRows to have a look into the content:
If you inspect the result, you’ll see just one column. However, the result we are looking for is one row with three columns. We need to use a small trick! Use the function JSON_ARRAYAGG to convert that column into a single row. This row will be an array:
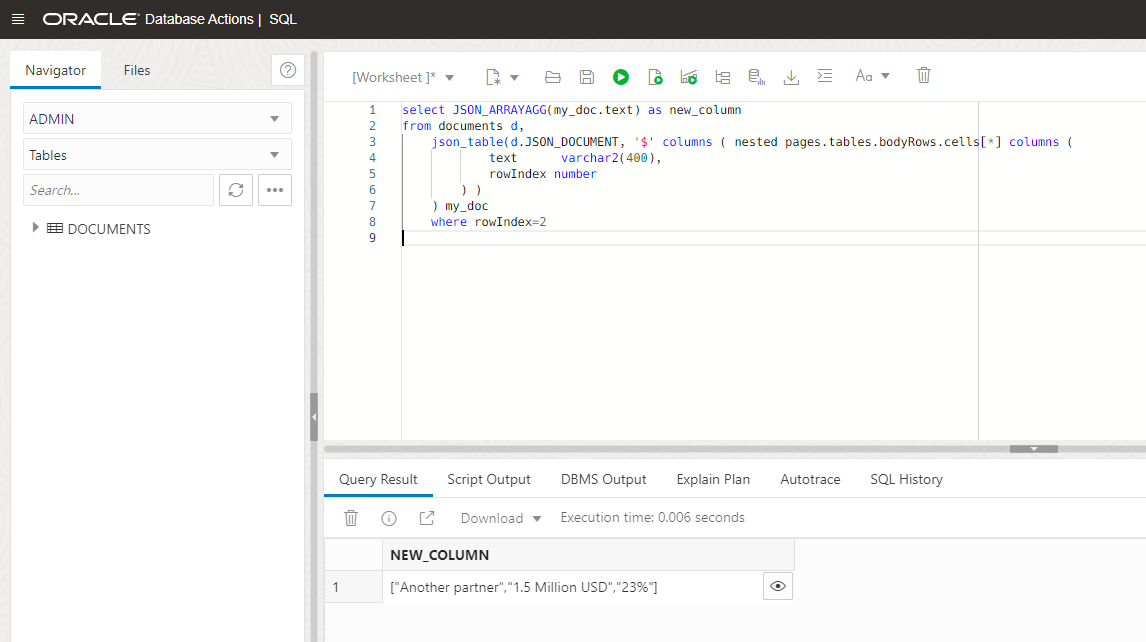
Now that we have the array, we can use the JSON_TABLE function again to obtain the three columns:
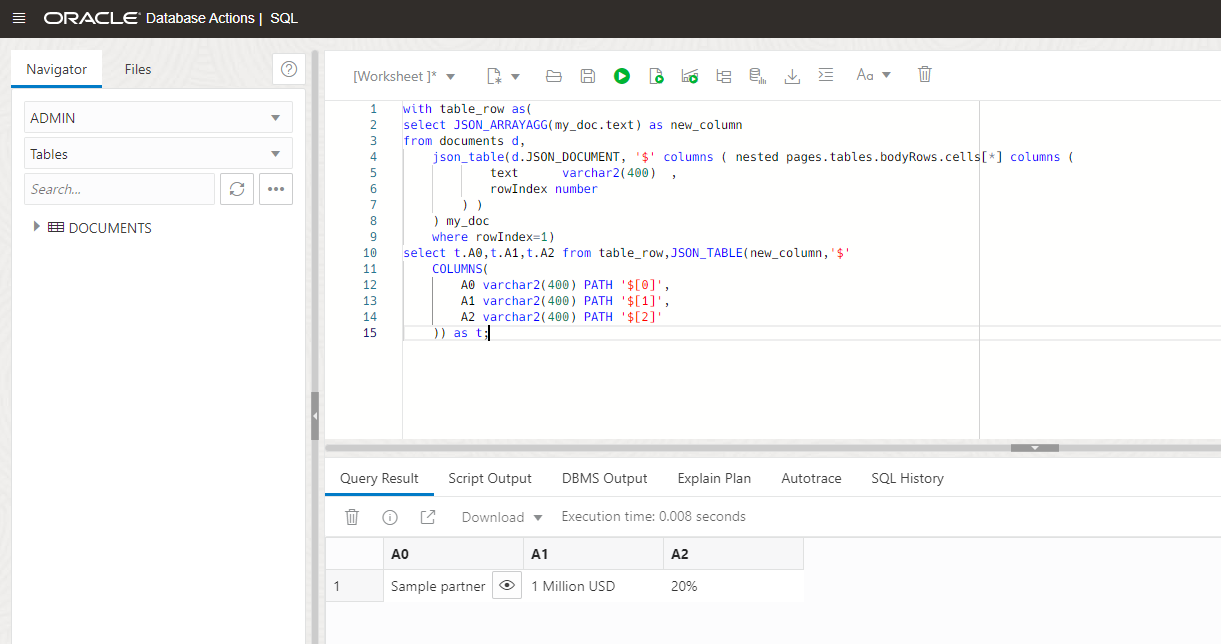
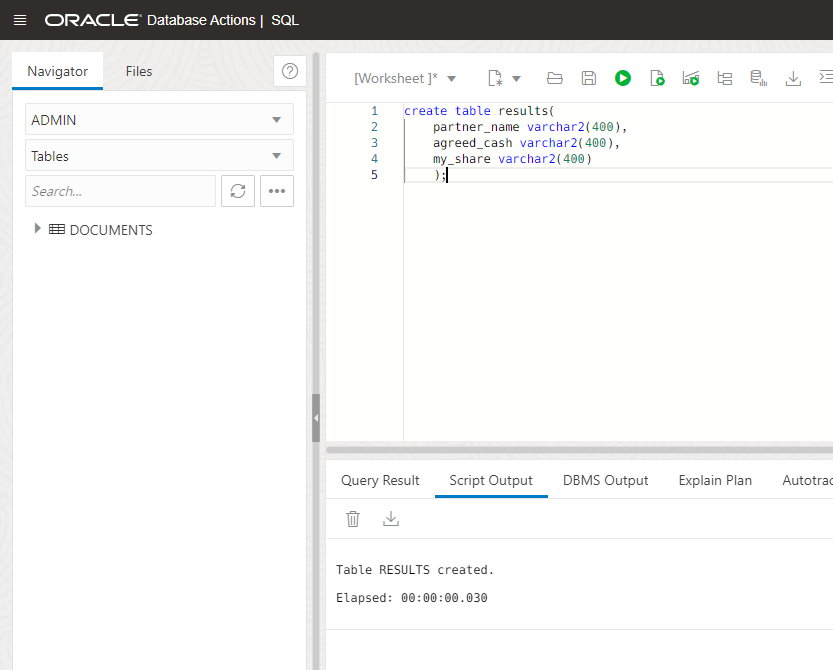
You can see that we are looking into the rowIndex 1. Now we can create a loop to iterate over all the rows. The first thing we are going to do is create a table to store the results of the query. As it’s just three columns, I will create it manually without the need of the headers:
Finally, let’s run the code that will iterate over the cell rows and them insert into the table:
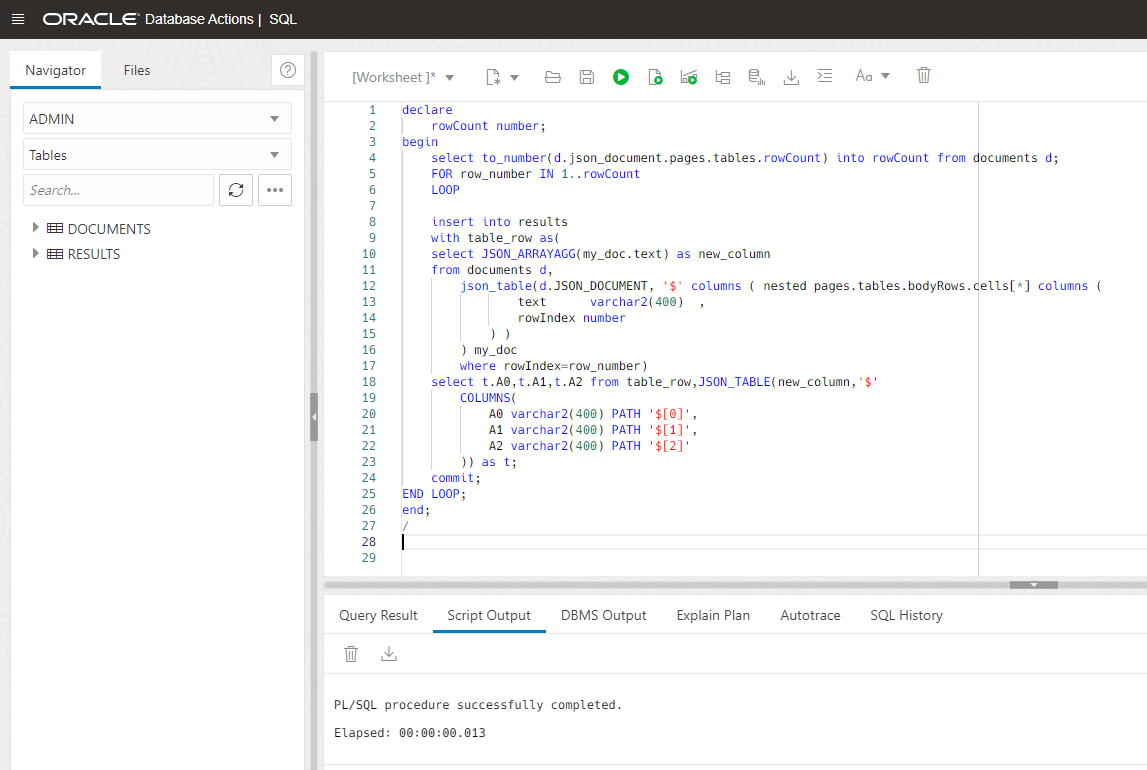
If we run a simple query, we can see all the data is stored in the table:
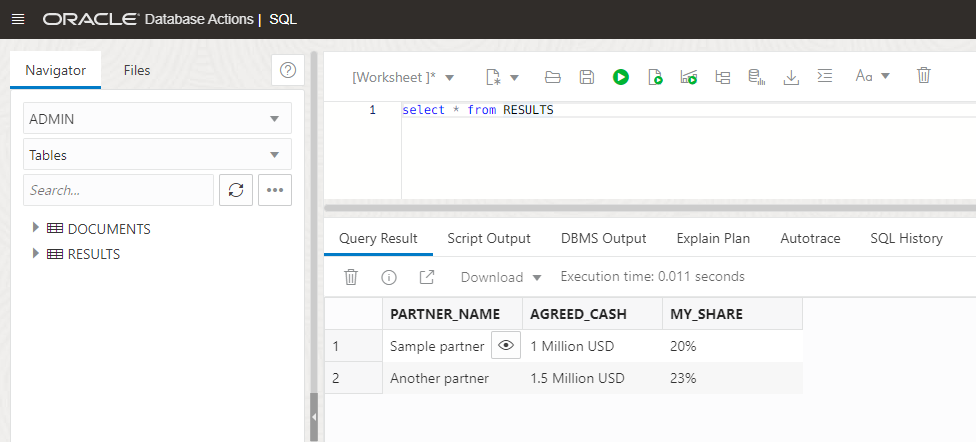
You have seen how easy is to use all the power of SQL over native JSON stored in the Autonomous Database.
Next:
- Learn more about Oracle Autonomous Database
- Check out the JSON Developer’s Guide
- Try it out! Go to Oracle LiveLabs for a hands-on experience with Oracle Database JSON capabilities