Modern businesses generate and rely on massive amounts of data, often spread across multiple platforms and clouds. Object Stores – such as OCI Object Store, Amazon S3, Google Cloud Storage, and Azure Blob Storage – are an essential part of many organizations’ data ecosystems as they offer inexpensive and convenient places to store a large volume of data, including modern table formats like Apache Iceberg, as well as other file types. To extract value from these distributed datasets in a timely manner, organizations need to directly access, efficiently process, and share the data across multiple engines and tools for analysis, AI, machine learning, and reporting—without having to create costly and complex process of moving or consolidating them.
Autonomous AI Database captures the critical data that organizations rely on to operate their businesses. It empowers advanced analytics by seamlessly combining operational data with data from Object Stores, eliminating the need for complex integrations or data movement. With the introduction of Data Lake Accelerator, Oracle Autonomous AI Database address the need for highly scalable query performance on Object Store data by offering a flexible, cost-efficient solution that dynamically scales resources based on query requirements.
What is Autonomous AI Database Data Lake Accelerator?
Data Lake Accelerator works
Autonomous AI Database Data Lake Accelerator is designed to improve the performance and scalability of external data processing tasks. It is an integrated feature of Autonomous AI Database that automatically allocates computational resources to accelerate the scanning and processing of data in Object Stores, offering:
- Dynamic scalability: Automatically scales resources by adding extra CPUs to complement your Autonomous AI Database base configuration.
- Performance optimization: Enhances query response times by accelerating external data scans, allowing businesses to analyze large external datasets more efficiently.
- One-click activation: Activate immediately in the Autonomous AI Database console or via API, without disrupting the in-flight database operations.
- Cost-efficiency: Lets you pay only for the resources you use, with dynamic CPU allocation. Data Lake Accelerator leverages Bring Your Own License (BYOL) pricing, further reducing costs.
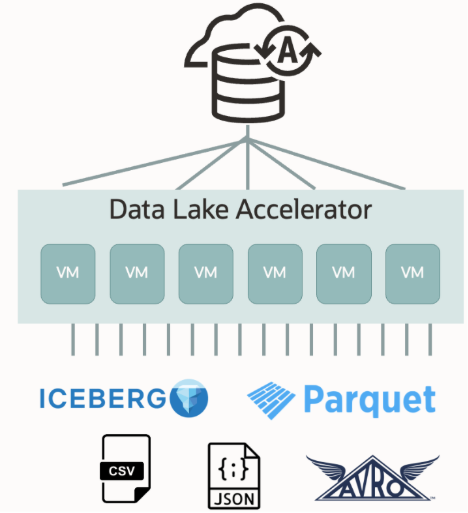
How Data Lake Accelerator Works
When a query against external data is submitted, Autonomous AI Database evaluates its computational needs. If additional resources are required, its Data Lake Accelerator allocates the necessary CPUs dynamically, enabling efficient resource utilization while reducing both processing times and overall costs.
Behind the scenes, this is achieved by additional virtual machines (VMs) automatically provisioned by Autonomous AI Database without any action required from the user. These VMs allow Autonomous AI Database to highly parallelize reading from Object Store, significantly accelerating query performance. This parallel processing works across a variety of file types, including CSV, JSON, Parquet, ORC, and especially Iceberg—the most modern and widely adopted table format for data lakes.
How to Get Started with Data Lake Accelerator
Since Data Lake Accelerator is an integrated, built-in feature of Autonomous AI Database, it is easy to enable this performance-enhancing feature. Once enabled, Autonomous AI Database automatically and dynamically manages resources.
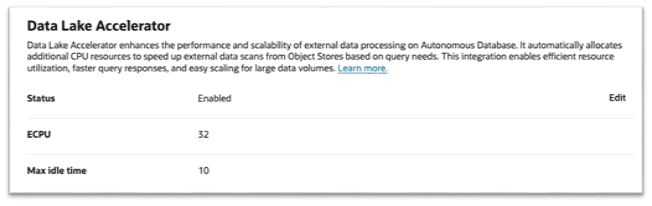
Navigate to the Tools Menu in the Cloud Console to enable or disable the Data Lake Accelerator and specify the allocated amount of compute.
Ready to Accelerate Your Data Processing?
Autonomous AI Database Data Lake Accelerator plays a key role in combining the capabilities of Oracle Autonomous AI Lakehouse with open-source components like Iceberg—the leading open table format for modern data lakes—or other file types in Object Store. In conjunction with Autonomous AI Database’s external table caching, it provides outstanding performance and automated resource management, enabling organizations to gain insights data easier, more efficient, and cost-effective – without any changes to existing queries.
