In an earlier post we looked at how you can see if a query uses Oracle Database In-Memory (DBIM) or In-Memory Parallel Query (IMPQ). In this post let’s look at what IMPQ is and how it works in 12c.
What is IMPQ?
Before 11gR2 Parallel Execution (PX) in the Oracle Database used direct reads to scan large tables and bypassed the buffer cache. As memory sizes got bigger and SGA sizes got bigger as a result, IMPQ was introduced in 11gR2 to make use of the SGA for data warehouse workloads. IMPQ is a performance enhancement feature that caches the data in the SGA so that further scans against the same data can avoid IO and read the data from the buffer cache much more faster. IMPQ makes use of the aggregated buffer cache across all nodes in a RAC cluster so that more data can be cached than can be done in a single server’s memory. It is not a RAC only feature, it kicks in for single instance databases too.
How does IMPQ work?
As you may already know PX uses granules to scan objects. Each object in a statement is divided into granules and granules are assigned to PX servers so that each process can read a part of the object. A granule can be a partition or a range of blocks depending on the physical definition of the object, the degree of parallelism (DOP), and the execution plan.
With IMPQ, for the first statement that accesses an object each PX server reads its granules and caches them in the buffer cache of the node it is on. In the following example a table is divided into four granules, PX server P1 on node 1 reads two of them and stores them in the buffer cache. PX server P2 on node 2 does the same for the other two granules. Note that the number of granules changes based on the object size and the DOP, I show four granules here for demonstration purposes.
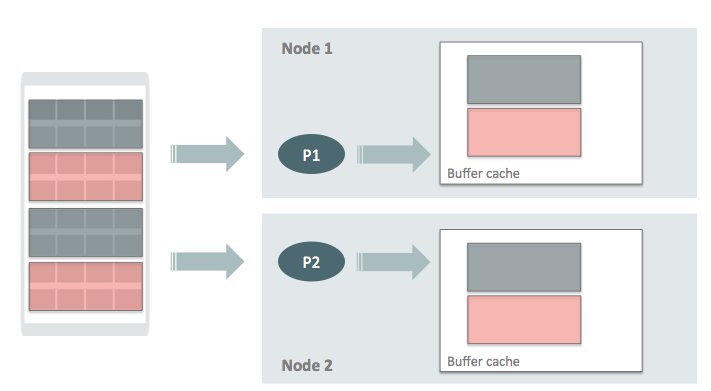
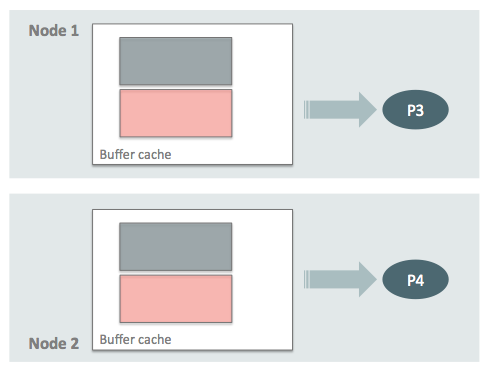
Now, half of the table is cached in node 1 and the other half is cached on node 2. When another parallel statement comes and accesses the same table, as you can see in the below picture the PX servers assigned to this statement (P3 and P4) will read the data from their node’s buffer cache instead of going to storage and doing IO. Note that cache fusion is not used to read data from other node’s memory, all buffer cache access is local.
In the following example, table T is 700MB and I have a 2-node RAC database, each node with a 500MB buffer cache. We see that the first execution did close to 90K physical reads and finished in around 4 seconds. The second execution shows no physical reads and finished in less than a second. This means the table was cached during the first execution and read from the cache during the second execution. Note that the first execution of the statement can take longer than without IMPQ because of the overhead of populating the buffer cache.
SQL> set autot on stat
SQL> select /*+ parallel(2) */ count(*) from t;
COUNT(*)
----------
179982
Elapsed: 00:00:03.58
Statistics
----------------------------------------------------------
7 recursive calls
4 db block gets
90486 consistent gets89996 physical reads
248 redo size
544 bytes sent via SQL*Net to client
551 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> select /*+ parallel(2) */ count(*) from t;
COUNT(*)
----------
179982
Elapsed: 00:00:00.68
Statistics
----------------------------------------------------------
6 recursive calls
0 db block gets
90485 consistent gets0 physical reads
248 redo size
544 bytes sent via SQL*Net to client
551 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processedWhen does IMPQ kick in?
IMPQ is tied to the parameter parallel_degree_policy. You need to set it to AUTO to enable IMPQ. Be aware that this setting also enables Auto DOP and Parallel Statement Queuing.
If IMPQ is enabled there are two decisions to be made for a statement to use IMPQ.
1. First the query coordinator (QC) decides to use IMPQ for an object or not. This decision is based on the object size to be scanned. By default if the object size is between 2% and 80% of the total buffer cache size in the cluster the object is a candidate for IMPQ. If the object is larger IMPQ will not be used and that object will be accessed using direct reads bypassing the buffer cache. For smaller objects IMPQ will not be used but the object can be cached like an object accessed by a serial query, Cache Fusion will be used to transfer data between nodes when necessary. For object size Oracle looks at the optimizer stats if they have been gathered, if not it looks at the actual object size.
If the query is using partition granules the object size is the total size of the partitions after static partition pruning. For dynamic partition pruning where the exact partitions to be scanned are determined at runtime the total table size is used in the IMPQ decision.
The total buffer cache size is calculated as the size of the buffer cache of the node where the QC resides multiplied by the number of nodes.
2. After the decision to use IMPQ is made the QC decides which granules will be cached on which node. It affinitizes each granule to a node so that subsequent accesses to the same granules are done on the same nodes. For partition granules this affinity is done based on the partition number, for block range granules it is done based on the data block address of the first block in the granule.
At this point the granules are assigned to PX servers on each node. Here each PX server makes the decision to use direct reads or buffered reads based on a set of heuristics and tries to cache as much data as possible. Depending on this decision, it is still possible to see direct reads even if the table is a candidate for IMPQ.
IMPQ adaptive offloading on Exadata
The smart scan capability of Exadata kicks in if an object is scanned using direct reads. If IMPQ tries to cache an object the object will be scanned using buffered reads and smart scan will not kick in. In this case you will see the wait event cell multiblock physical read instead of cell smart table scan. Not using smart scans means you will be using the database nodes to do filtering and projection. This can cause a query to run slower if that query benefits a lot from smart scan.
To prevent this PX servers use adaptive offloading on Exadata. The first scan of an object bypasses offloading and populates the buffer cache. In subsequent scans of the same object each PX server calculates the buffer cache scan rate and smart scan rate. Depending on the ratio of these rates PX servers will favor direct reads or buffer cache reads. So, if smart scan is very fast for your query you will see that PX servers will use more direct reads than buffer cache reads. For example, if the ratio of the smart scan rate to buffer cache read rate is 3:1 PX servers will scan 3x number of granules using direct reads compared to the number of granules scanned from the buffer cache. This rate comparison is done for each query execution by PX servers.
Things to be aware of
IMPQ on heterogeneous clusters
As of 12.1.0.2 IMPQ assumes the RAC cluster is homogenous which means every RAC instance has the same buffer cache size. If you have instances with different buffer cache sizes you can see IMPQ being used or not depending on which instance your session is on.
For example, if you have a 2-node RAC with node 1 having a 300MB buffer cache and node 2 having a 700MB buffer cache, IMPQ will use 600MB as the total buffer cache size if you are on node 1, it will use 1400MB if you are on node 2. So, if you query a table of 700MB, IMPQ may or may not kick in, if you are on node 2 it will try to cache the table, if you are on node 1 it will not.
To make use of IMPQ efficiently we recommend sizing the buffer cache equally on all instances.
Effect of DOP change on IMPQ
As of 12.1.0.2 granule-node affinity in IMPQ depends on the statement DOP. If you query a table with DOP=4 and then query the same table with DOP=8 the node affinity may not be the same. This means the second query may do IO to read the table even if the table is totally cached. This is because the node affinity depends on the starting data block address of a granule, DOP change means the number and size of granules can change which means the starting data block address can change.
DOP and the number of instances
Auto DOP automatically rounds up the DOP to a multiple of the number of instances so that every instance has equal number of PX servers. This means the table will be cached on all instances uniformly. If you are using hints to specify the DOP or if you are using Database Resource Manager(DBRM) to limit the DOP, make sure to set the DOP to a multiple of the number of instances to get the same behavior, this is because hints and DBRM override Auto DOP.
