Many thanks to Prabhu Thukkaram from the GoldenGate Streaming Analytics team for this post :).
GoldenGate Stream Analytics is a Spark-based platform for building stream processing applications. One of the key differentiators is productivity or time-to-value, which is a direct result of the following
Support for diverse messaging platforms – Kafka, OCI Streaming Service, JMS, Oracle AQ, MQTT, etc.
Natively integrated with Oracle GoldenGate to process and analyze transaction streams from relational databases
Interactive pipeline designer with live results to instantly validate your work
Zero-code environment to build continuous ETL and analytics workflows
Pattern library for advanced data transformation and real-time analytics
Extensive support for processing geospatial data
Secured connectivity to diverse data sources and sinks
Built-in support for real-time visualizations and dashboards
Automatic application state management
Automatic configuration of pipelines for high availability and reliability
Automatic configuration of pipelines for lower latency and higher throughput
Automatic log management of pipelines for better disk space utilization
Built in cache (choice of Coherence and Apache Ignite) for better pipeline performance and sharing of data across pipelines. Caching is seamlessly integrated and no need to run additional cache clusters
Continuously refresh your DataMart, Datawarehouse, and Data Lake (ADW, OCI Object Store, HDFS/Hive, Oracle NoSQL, Mongo DB, AWS S3, Azure Data Lake, Google Big Query, Redshift, etc.). Please note some of this will be arriving in 19.1.0.0.4 which is the next version.
Alerts via Email, PagerDuty, Slack, etc., using OCI Notification Service
This video discusses industry use cases and demonstrates the ease with which data pipelines can be built and deployed using GoldenGate Stream Analytics. If you are aware of the value proposition and interested in deploying GGSA pipelines to Big Data service, then please continue reading.
The Marketplace instance of GoldenGate Stream Analytics embeds Apache Spark and Apache Kafka so data pipelines can be built and tested without other dependencies. While this is good for developers to quickly build and test pipelines, it is not ideal for enterprise deployments and production. For production we will need a runtime platform that can scale with increasing workloads, is highly available, and one that can be secured with highest standards. This blog describes how to run GGSA pipelines in the Big Data Service runtime environment.
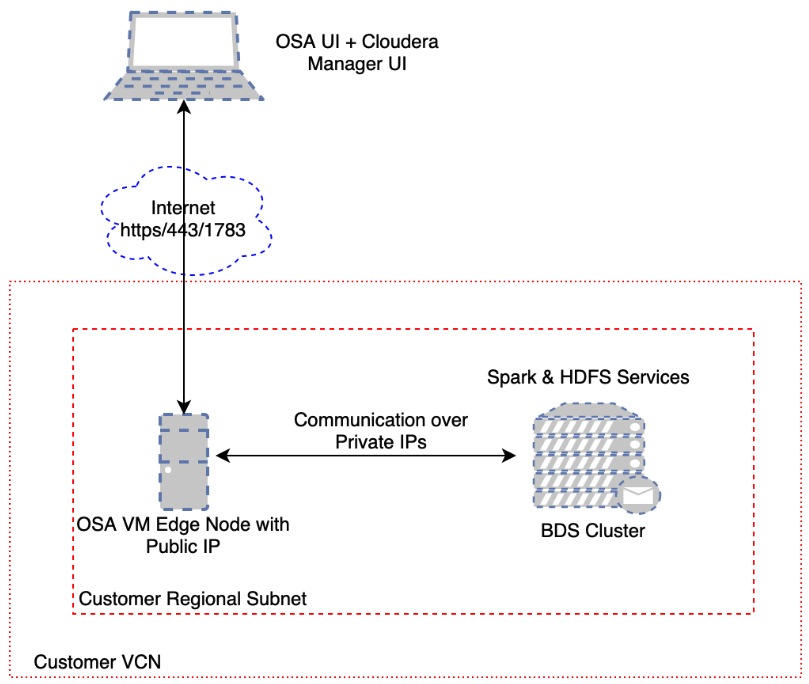
Topology
In this example, the marketplace instance of GoldenGate Stream Analytics is created in the same regional subnet as the BDS cluster. A marketplace instance of Stream Analytics can be provisioned from here. You can also refer to the GGSA Marketplace user guide. Big Data Service can be provisioned from here.
Topology is shown in the diagram below and the GGSA instance is accessed using its public IP address.
Please note your GoldenGate Stream Analytics instance will also act as a Bastion Host to your BDS cluster. Once you ssh to GGSA instance, you will also be able to ssh to all your BDS nodes. To do this you will need to copy your ssh private key to GGSA instance. You will also be able to access your Cloudera Manager using the same public IP of GGSA instance by following steps below.
The default security list for the Regional Subnet must allow bidirectional traffic to edge/OSA node so create a stateful rule for destination port 443. Also create a similar Ingress rule for port 7183 to access the BDS Cloudera Manager via the OSA edge node. An example Ingress rule is shown below.
SSH to GGSA box and run the following port forward commands so you can access the Cloudera Manager via the GGSA instance.
sudo firewall-cmd --add-forward-port=port=7183:proto=tcp:toaddr=<IP address of Utility Node running the Cloudera Manager console> sudo firewall-cmd --runtime-to-permanent sudo sysctl net.ipv4.ip_forward=1 sudo iptables -t nat -A PREROUTING -p tcp --dport 7183 -j DNAT --to-destination <IP address of Utility Node running the Cloudera Manager console>:7183 sudo iptables -t nat -A POSTROUTING -j MASQUERADE
You should now be able to access the Cloudera Manager using the URL https://<Public IP of GGSA>:7183
Prerequisites
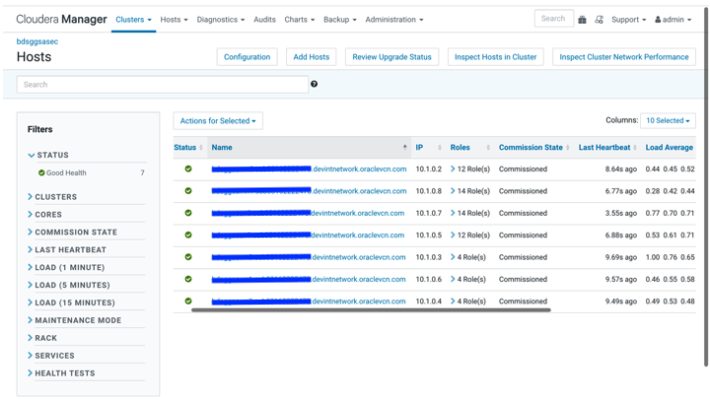
Retrieve IP addresses of BDS cluster nodes from OCI console as shown in screenshot below. Alternatively, you can get the FQDN for BDS nodes from the Cloudera Manager as shown in the next screenshot.
Patch spark-osa.jar in $OSA_HOME/osa-base/resources/modules/spark-osa.jar so dfs.client.use.datanode.hostname is set to true. Please make a copy of spark-osa.jar before replacing with the patch. This will be automatic in the next OS›A version 19.1.0.0.4. None of this workaround will be necessary. For now you can obtain the patch from here and here are the steps to patch
Copy downloaded ~/spark-osa.jar to /u01/app/osa/osa-base/resources/modules/spark-osa.jar
Start OSA by running “sudo systemctl start osa”
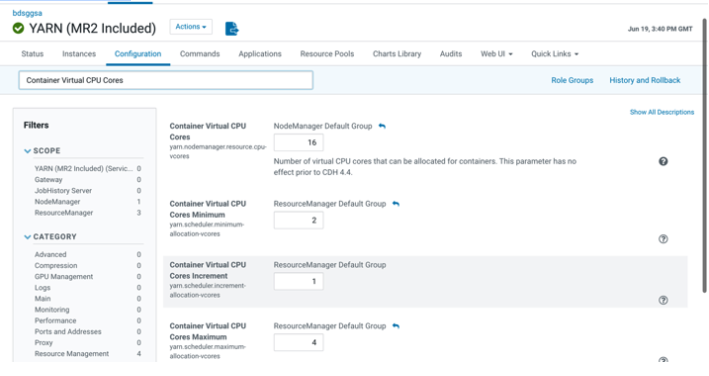
Reconfigure YARN virtual cores using Cloudera Manager as shown below. This will allow many pipelines to run in the cluster and not bound by actual physical cores. Container Virtual CPU Cores :- This is the total virtual CPU cores available to YARN Node Manager for allocation to Containers. Please note this is not limited by physical cores and you can set this to a high number, say 32 even for VM standard 2.1. Container Virtual CPU Cores Minimum :- This is the minimum vcores that will be allocated by YARN scheduler to a Container. Please set this to 2 since CQL engine is a long-running task and will require a dedicated vcore. Container Virtual CPU Cores Maximum :- This is the maximum vcores that will be allocated by YARN scheduler to a Container. Please set this to a number higher than 2 say 4. Note: this change will require a restart of the YARN cluster from Cloudera Manager.
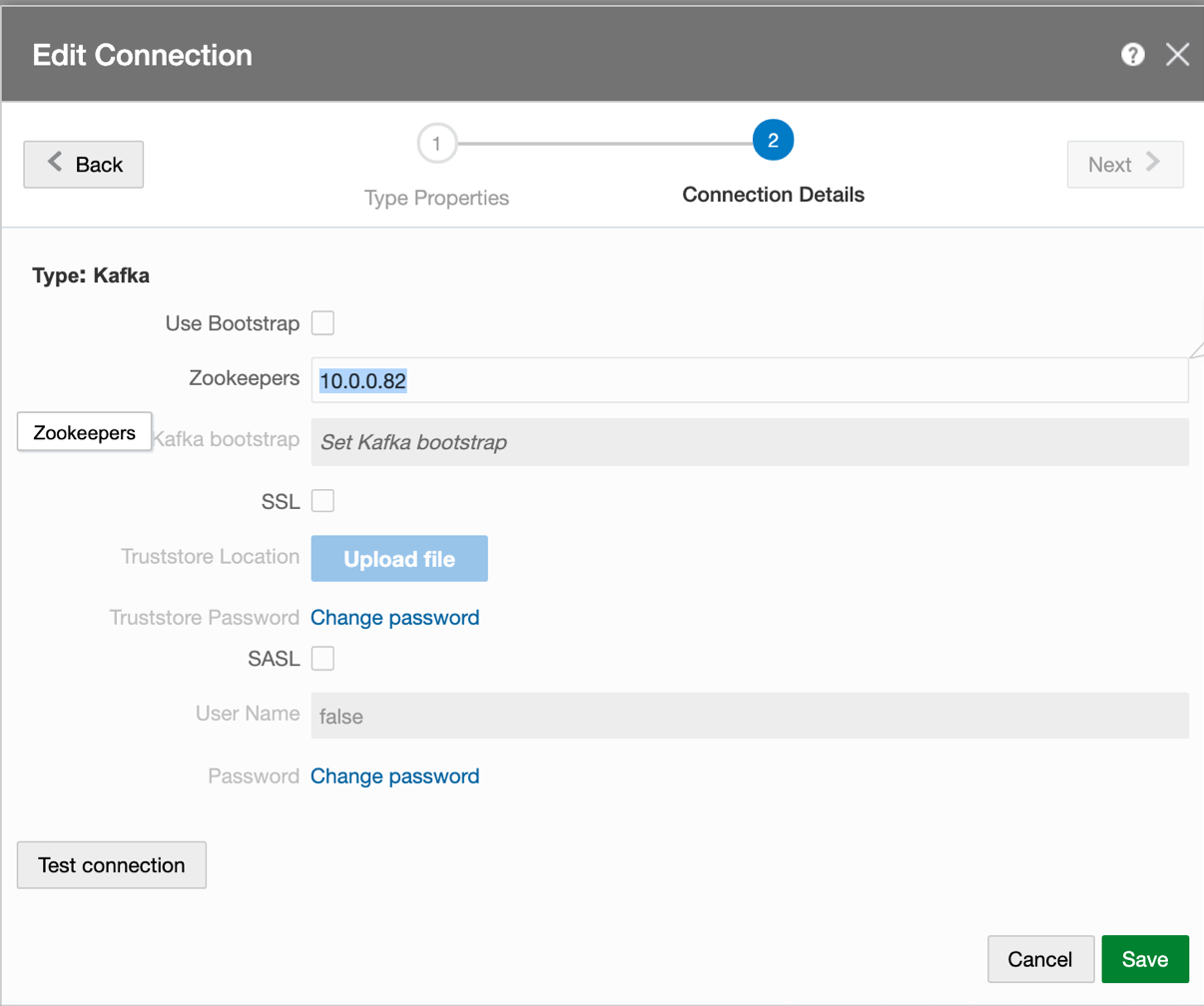
If using Kafka from OSA Marketplace instance, set advertised listeners to private IP of the OSA node and port 9092 in /u01/app/kafka/config/server.properties. E.g. advertised_listeners=PLAINTEXT://10.0.0.13:9092. Please restart the Kafka service after this change by running “sudo systemctl restart kafka”. This will be automatic in the next OSA version 19.1.0.0.4.
Deploying GGSA Pipelines to Non-Kerberized Dev/Test BDS cluster
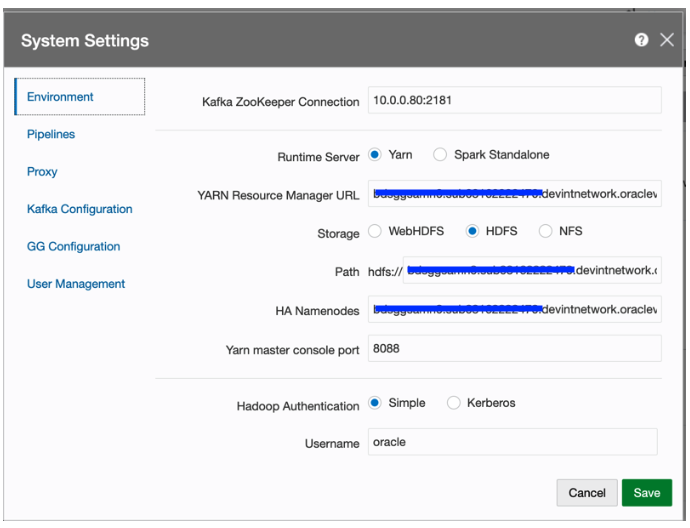
In GGSA system settings dialog, configure the following:
Set Kafka Zookeeper Connection to Private IP of the OSA node. E.g. 10.0.0.59:2181
Set Runtime Server to Yarn
Set Yarn Resource Manager URL to Private IP or Hostname of the BDS Master node (E.g. xxxxx.devintnetwork.oraclevcn.com)
Set storage type to HDFS
Set Path to <PrivateIP or Host Of Master><HDFS Path>. E.g. 10.x.x.x/user/oracle/ggsapipelines or xxxxx.devintnetwork.oraclevcn.com/user/oracle/ggsapipelines.
Set HA Namenode to Private IP or Hostname of the BDS Master node. E.g. xxxxx.devintnetwork.oraclevcn.com
Set Yarn Master Console port to 8088 or as configured in BDS
Set Hadoop authentication to Simple and leave Hadoop protection policy at authentication if available
Set username to “oracle” and click Save.
A sample screenshot is shown below: Deploying GGSA Pipelines to Kerberized Production BDS Cluster
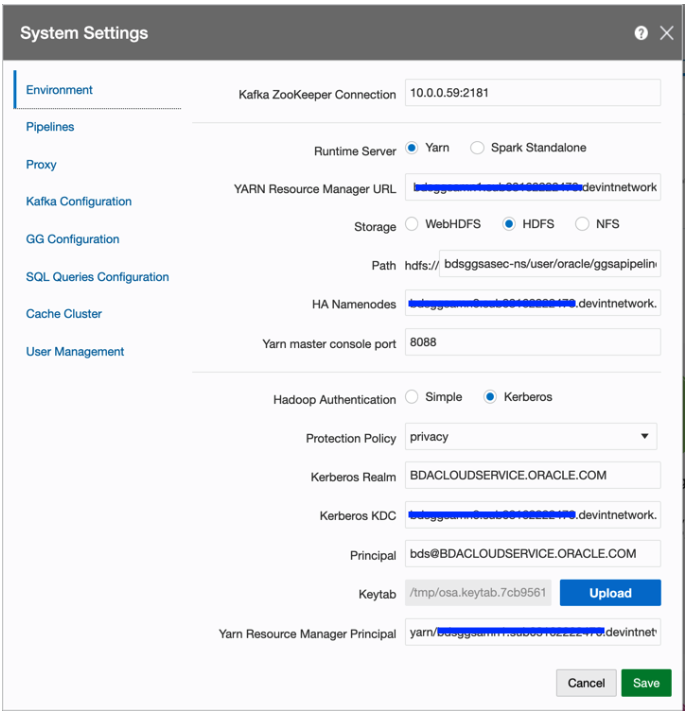
In GGSA system settings dialog, configure the following:
Set Kafka Zookeeper Connection to Private IP of the OSA node. E.g. 10.0.0.59:2181
Set Runtime Server to Yarn
Set Yarn Resource Manager URL to Private IPs of all master nodes starting with the one running active Yarn Resource Manager. In the next version of OSA, the ordering will not be needed. E.g. xxxxx.devintnetwork.oraclevcn.com, xxxxx.devintnetwork.oraclevcn.com
Set storage type to HDFS
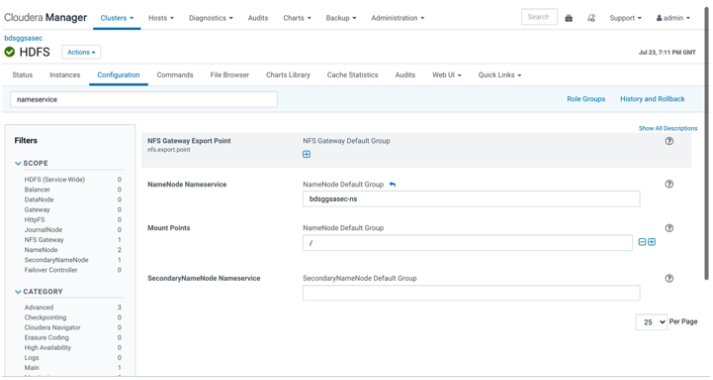
Set Path to <NameNode Nameservice><HDFS Path>. E.g. bdsggsasec-ns/user/oracle/ggsapipelines. The path will automatically be created if it does not exist but the Hadoop User must have write permissions. NameNode Nameservice can be obtained from HDFS configuration as shown in the screenshot below.
Set HA Namenode to Private IPs or hostnames of all master nodes (comma separated) starting with the one running active NameNode server. In the next version of OSA, the ordering will not be needed. E.g. xxxxx.devintnetwork.oraclevcn.com, xxxxx.devintnetwork.oraclevcn.com
Set Yarn Master Console port to 8088 or as configured in BDS
Set Hadoop authentication to Kerberos
Set Kerberos Realm to BDACLOUDSERVICE.ORACLE.COM
Set Kerberos KDC to private IP or hostname of one of the BDS master nodes. E.g. xxxxx.devintnetwork.oraclevcn.com
Set principal to bds@BDACLOUDSERVICE.ORACLE.COM. Please see this documentation to create a Kerberos principal (e.g. bds) and add it to hadoop admin group, starting with step “Connect to Cluster’s First Master Node” and through the step “Update HDFS Supergroup”. Note, you can hop/ssh to the master node using your GGSA node as the Bastion. You will need your ssh private key to be available on GGSA node though. Also, do not forget to restart your BDS cluster as instructed in the documentation.
Fetch the keytab file using sftp, etc and set Keytab field in system settings by uploading the same
Set Yarn Resource Manager principal which should be in the format “yarn/<FQDN of BDS MasterNode running Active Resource Manager>@KerberosRealm” E.g. yarn/xxxxx.devintnetwork.oraclevcn.com@BDACLOUDSERVICE.ORACLE.COM
Sample screenshot shown below:
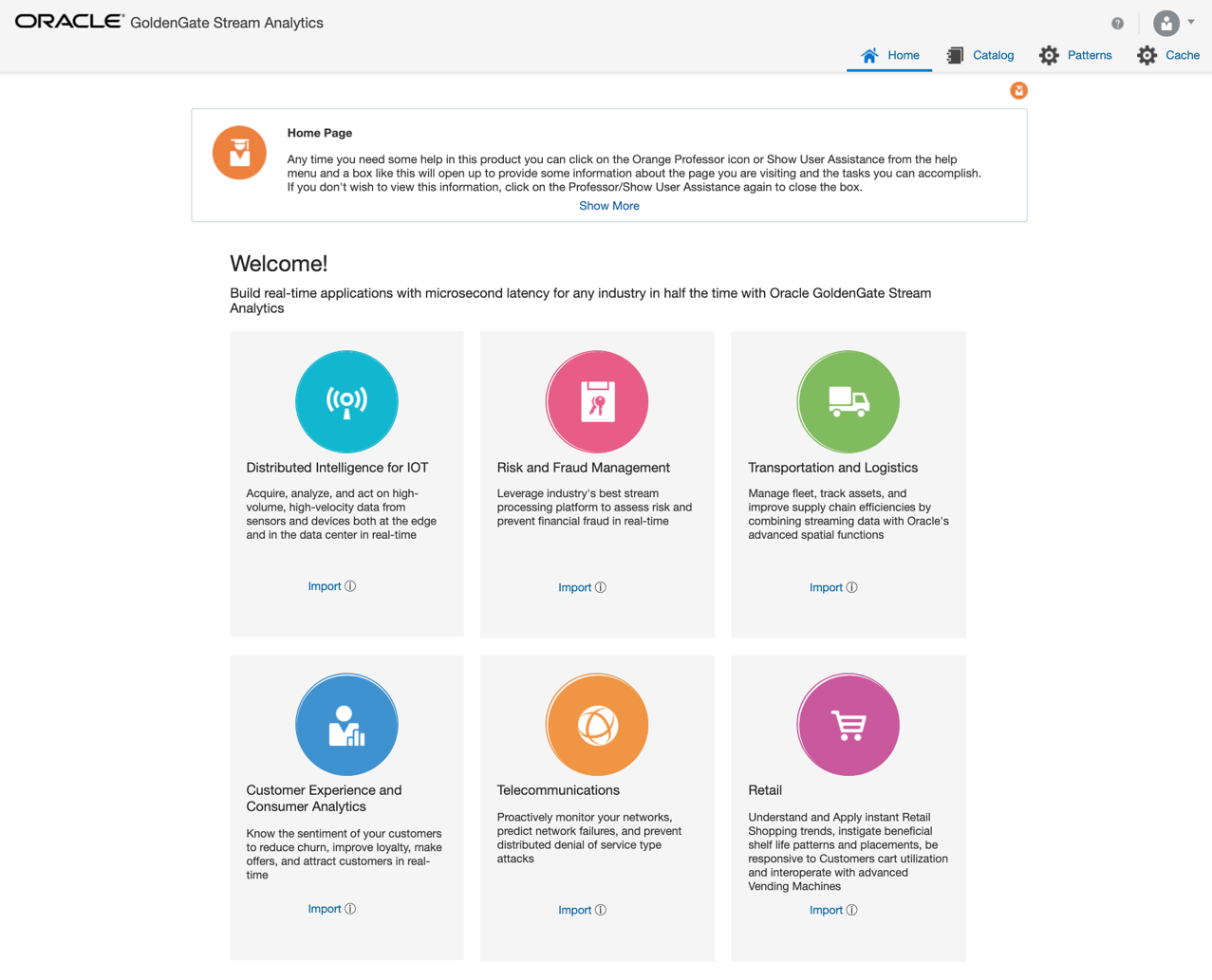
Running Samples on BDS
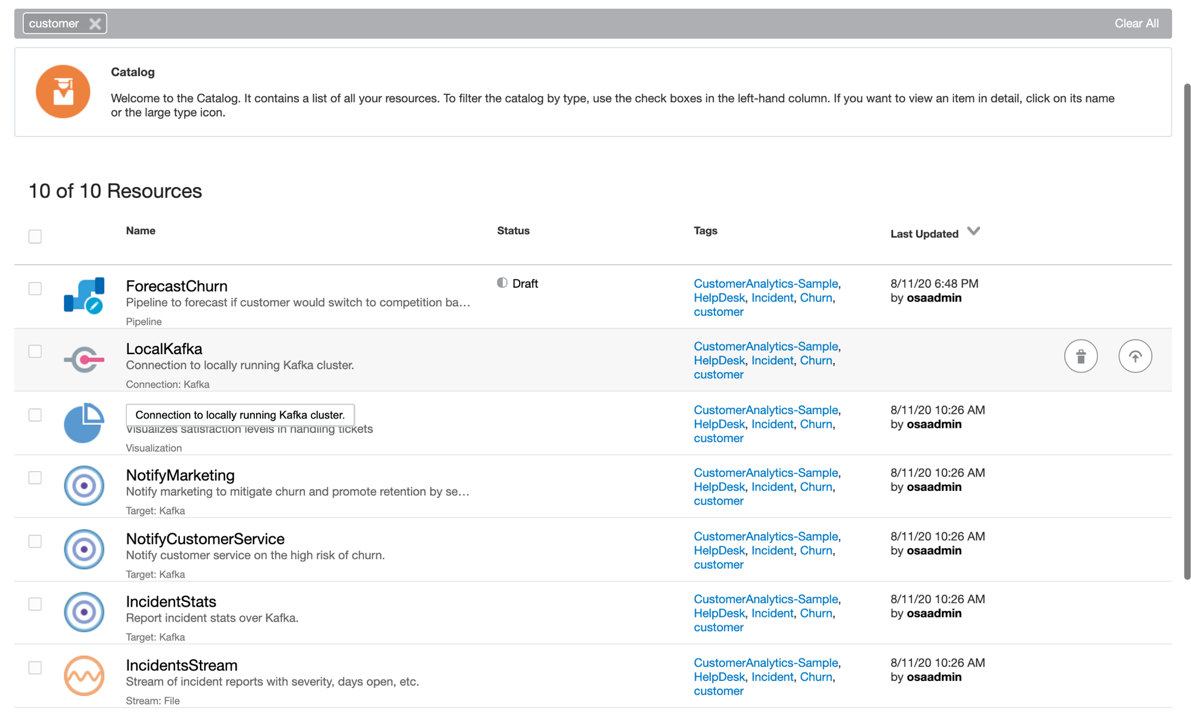
To import a sample, click “import” on any of the six samples in screenshot below and switch to Catalog or just click on the circle. To run the sample on BDS change the hostname in Kafka connection of the sample pipeline from “localhost” to the private IP address (run hostname -i to get IP address) of the GGSA instance node. After this change you can just open the pipeline or you can publish the pipeline and then open the associated dashboard. Please see screenshots below.
Authors
Marty Gubar
Director Product Management
I'm a product manager on the Autonomous Database development team.