Having a well-thought out cloud disaster recovery (DR) strategy can be majorly advantageous to a business’ financial and operational reputation. If you’re running any application or platform in the cloud or on-premise, having a disaster recovery setup is crucial for keeping your data safe and minimizing downtime in case of any kind of outages. Here is some reasoning to keep in mind:
-
Disaster recovery provides a safety net for data loss: In the event of a disaster, such as a natural disaster or a cyber attack, data loss is a significant risk. By configuring disaster recovery, you can restore your database to a previous state before the disaster occurred. This means you won’t lose all your data and can quickly resume operations without starting from scratch.
-
Minimize downtime: A DR setup will cover situations when your database goes down, to avoid any significant impact on your business operations and recover your database to a previous state, minimizing downtime and ensuring business continuity.
-
It is net cost-effective: The cost of downtime for your business is likely much more significant than investing in a disaster recovery plan. By having a solid DR plan in place, you will avoid lost revenue, lost productivity, and other expenses that can result from downtime.
-
Compliance requirements: Many industries have specific compliance requirements around disaster recovery and backup strategies. A good disaster recovery service ensures you meet these requirements.
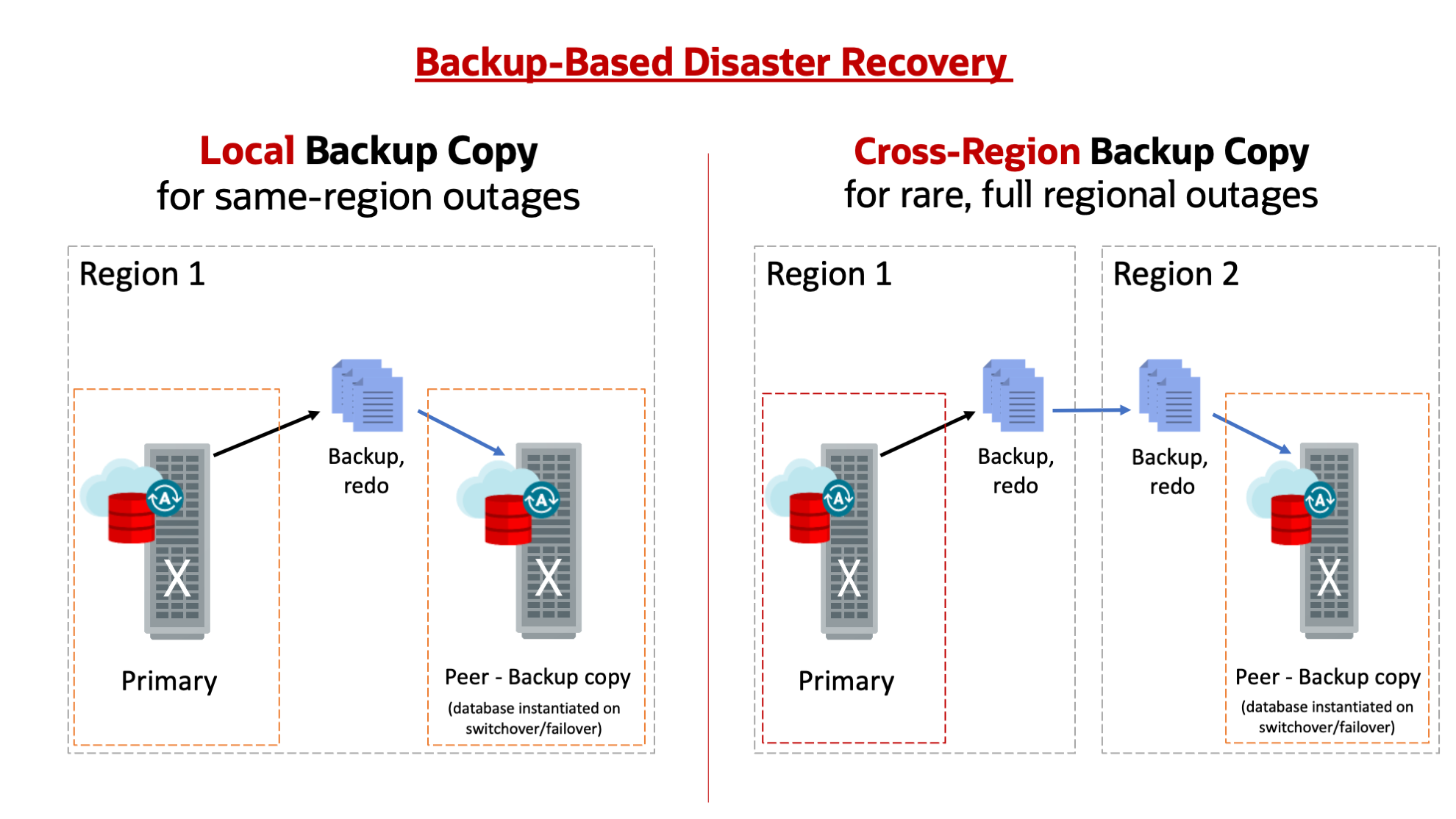
To protect against such risks, Autonomous Database (ADB) provides standbys with Autonomous Data Guard (AuDG), which you may have read about in my previous blog posts. As described in detail in previous posts, AuDG is the highest level of disaster recovery service available in ADB for your business critical systems. With feedback from you, our awesome users, I am happy to introduce a second disaster recovery type available today, which has a lower cost than AuDG but a higher recovery time, for less critical and non-production systems – Backup-based Disaster Recovery! As the name suggests, backup-based DR provides recovery from outages not by providing a physical, refreshing Standby like AuDG does, but simply by instantiating a database using the latest available backups and redo logs for your database.
This also means that, unlike Autonomous Data Guard, you will not be billed for any additional CPU usage on your backup copy while it is simply standing by, which is what significantly reduces the cost of this DR option. Local backup copies make use of your database’s automatic backups and therefore do not incur any additional costs. Cross-region (remote) backup copies are only billed for twice (2x) of the storage consumed for the backup data replicated to the remote region (billed as database storage for OCPU-based databases and as backup storage on ECPU-based databases).
As I walk you through more detail and how to use this new Disaster Recovery feature, let’s brush up on our disaster recovery terminology:
Disaster Recovery (DR) Peers: Two or more databases that are peered (linked and replicated) between each other. In ADB, peers may be a Primary (ie. source database), an Autonomous Data Guard Standby (ie. a refreshing, physical copy of the Primary) or a Backup Copy.
Switchover: This is a user operation that can be triggered to switch roles between the Primary and the DR peer (ie. The Standby / Backup Copy assumes the Primary role, and the Primary switches into being the Standby / Backup Copy). A switchover will only succeed if no data loss can be guarantee, and so this is the recommended operation while testing your disaster recovery setup.
Failover: This is a user operation that too can be triggered to switch roles between the Primary and the DR peer database. However, unlike a switchover, triggering a failover may incur some data loss during. A failover is generally recommended during an actual failure.
Primary or Source Database: The main database that is actively being used to read from and write to by a user or application.
Autonomous Data Guard Standby Database: A replica of the primary database which is constantly and passively refreshing (ie. replicating) data from the primary. This standby database is used in case of failure of the primary.
Backup Copy: This is the new type of disaster recovery peer introduced today with Backup-Based Disaster Recovery – This type of peer is not a physical standby database but is simply a set of backups stored from the source (primary) database, that are used to instantiate a new database at the time of switchover or failover.
Local (same-region) peer: This type of disaster recovery peer protects your system against local outages (such as localized disk corruption or network failures). Your local peer will lie in a different Availability Domain (AD) than the Primary database, in regions with multiple ADs, or a different Exadata machine in regions with only one AD.
Remote (cross-region) peer: This type of disaster recovery peer protects your system against full regional outages (such as natural disasters or complete regional network outages). Your remote peer will lie in a different region than the Primary database.
Recovery Point Objective (RPO): An organization’s maximum tolerance for data loss, after which business operations start to get severely impacted, usually expressed in minutes. Lower is better.
Recovery Time Object (RTO): An organization’s maximum tolerance for the unavailability (or downtime) of a service after which business operations start to get severely impacted, usually expressed in minutes. Lower is better.
View and Manage your Disaster Recovery options in ADB
For the simplest user experience, the new Backup-Based Disaster Recovery looks and feels much like your previous Autonomous Data Guard options and is fully-managed by Oracle. This means only a few simple clicks and a few minutes of patience get you to a fully functional backup-based disaster recovery solution.
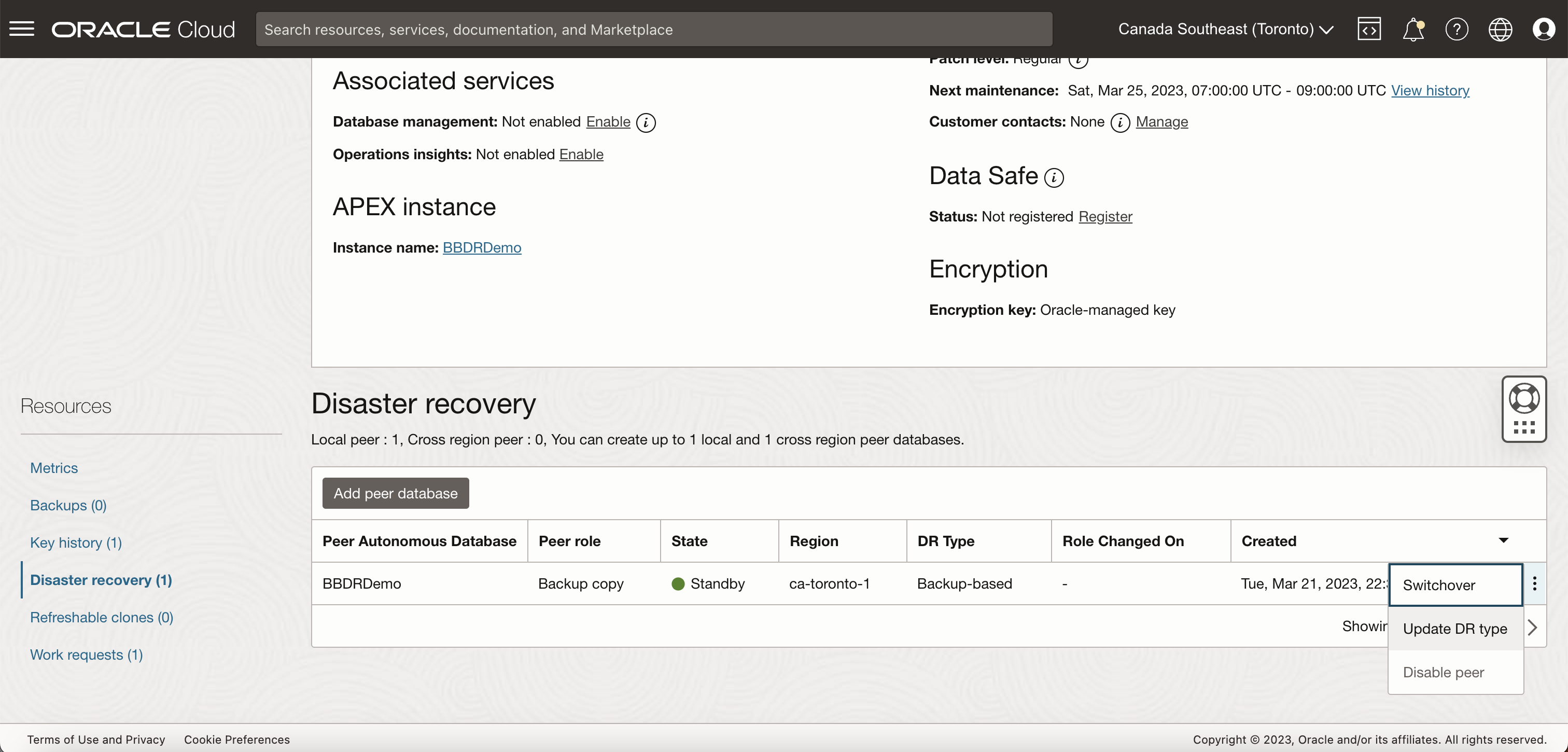
You already know how to navigate to your Autonomous Database console in Oracle Cloud, by clicking on your database name of choice from your list of database instances. Scroll down and select your Disaster Recovery tab to view your disaster recovery peers.
You will have the option to have 1 local peer and 1 cross-region (remote) peer as part of your disaster recovery setup. Each peer can be either a backup copy or an Autonomous Data Guard Standby.
You will notice that all your databases without AuDG already enabled, come with local Backup-Based Disaster Recovery by default, with no action required by you. This is because ADB already takes local (same-region) backups automatically for you, so ADB makes use of those backups and there is no additional cost to enable a local backup copy.
As with AuDG, switchover / failover to a local backup copy is seamless and does not require any wallet or connection strings changes to be made to connect to the database.
If you prefer your local DR option to be AuDG, you may select “Update DR Type” and update your local DR peer to be Autonomous Data Guard as per your database RTO / RPO requirement. Highly critical production systems should use a database with Autonomous Data Guard.
The complete RTO and RPO Service Level Objective that ADB targets can be viewed in the documentation here.
With Backup-Based Disaster Recovery enabled, the RTO is based on the size of the database. The SLO targets are:
Local and Cross-Region Backup Copy: RTO = (1hr + 1hr per 5TB) mins, RPO = 1 min
With Autonomous Data Guard standbys enabled the SLO targets are:
Local Standby Database: RTO = 2 mins, RPO = 1 min
Cross-Region Standby Database: RTO = 15 mins, RPO = 1 min
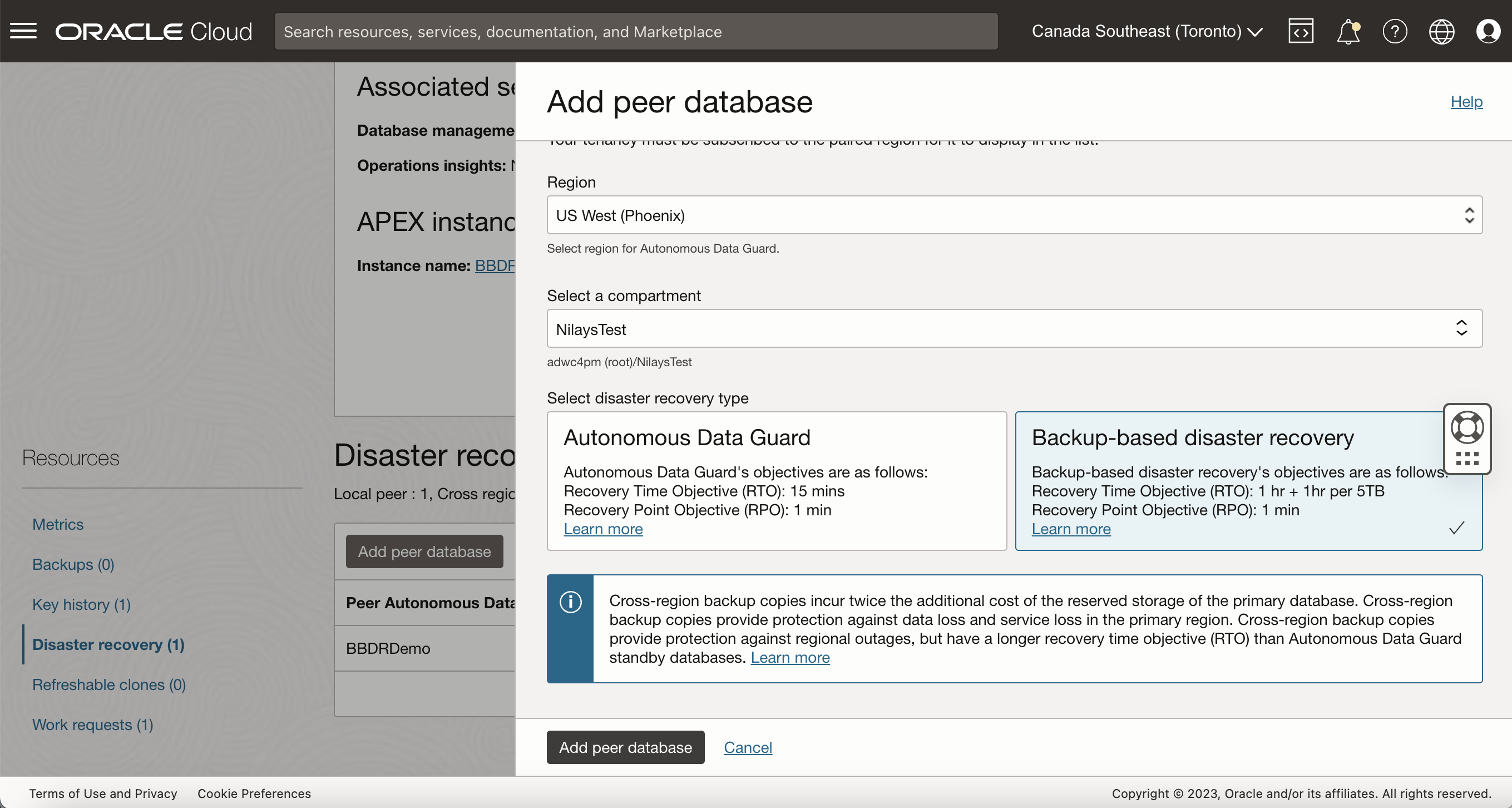
In addition to a local backup copy, you may also add a cross-region backup copy by selecting Add Peer Database. Select your remote Paired Region of choice (your tenancy must be subscribed to the remote region). When adding a remote peer, you may optionally provide the region-specific networking details for the peer (VCN, subnets etc.) if you intend for the remote peer to have Access Control Lists (ACLs) or Private Endpoints applied. Additionally, you may also optionally peer your source region and remote region’s Virual Cloud Networks (VCNs) if you would like to connect to your private peer database across VCNs.
After switchover / failover to a cross-region backup copy, connecting to the remote peer does require using of the remote peer’s wallet or connection strings. Read the documentation here about connection strings / wallets for remote peers for more detail. Similarly, use the respective Database Tools URLs (APEX, OML, ORDS etc) from Database Actions on the remote database.
As with your local DR peer option, you may choose to select Autonomous Data Guard as your remote peer as per your database RTO / RPO requirement. Highly critical production systems should use a database with Autonomous Data Guard.
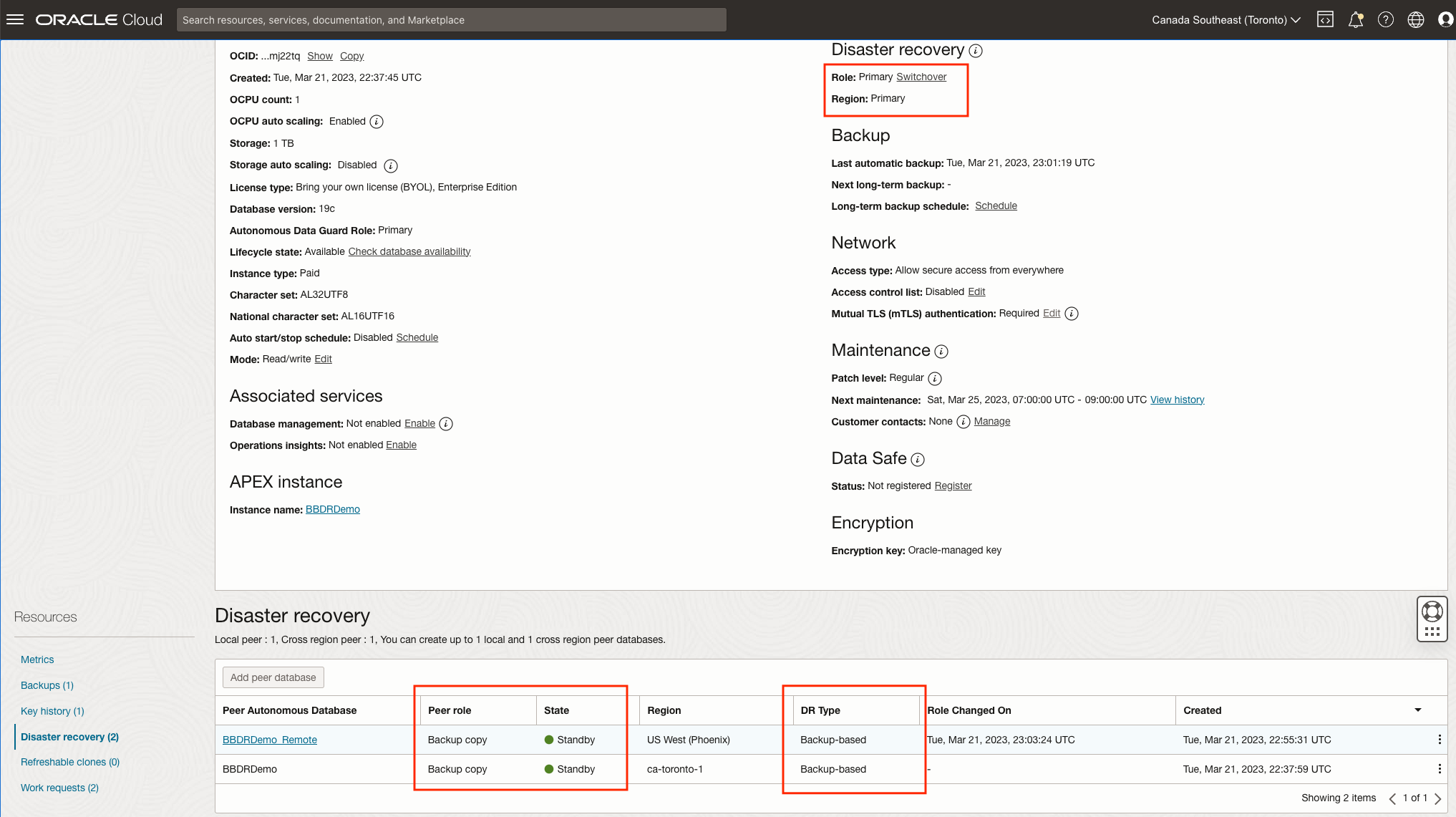
You’re done, that’s all you need to do to protect your database! You will now see your backup-based peer in a Provisioning state until it turns to green and becomes available for use in the “Standby” state. Depending on the size of your primary database it may take several minutes or hours to copy over the necessary backups.
Note the Role of your peers as Primary and Backup Copy as well as their identifiable Disaster Recovery Type: Backup-Based or Autonomous Data Guard
Now that you have DR set up, everything that follows describes functionality you will use either in a disaster type scenario, or to test your applications / mid-tiers against your Autonomous Database disaster recovery peers.
Switchover – Your no-data-loss-guaranteed first line of defense to switch to or test your DR peer
When your peer is provisioned, you will see a “Switchover” option on the database console, as well as in the menu options under the Disaster Recovery tab, while your peer databases are both healthy (ie. in the Available, Standby or Stopped states). Clicking the Switchover button and selecting the local or remote peer performs a role change, switching roles between the primary database and the backup copy, with no data loss guaranteed. With a Backup Copy, this may take several minutes or hours with backup-based DR depending on the size of your database (Remember the RTO from above) as your peer is instantiating your database from the stored backups at this time.
Note, as with AuDG, to switchover to a cross-region (remote) peer, trigger the switchover from the remote region peer.

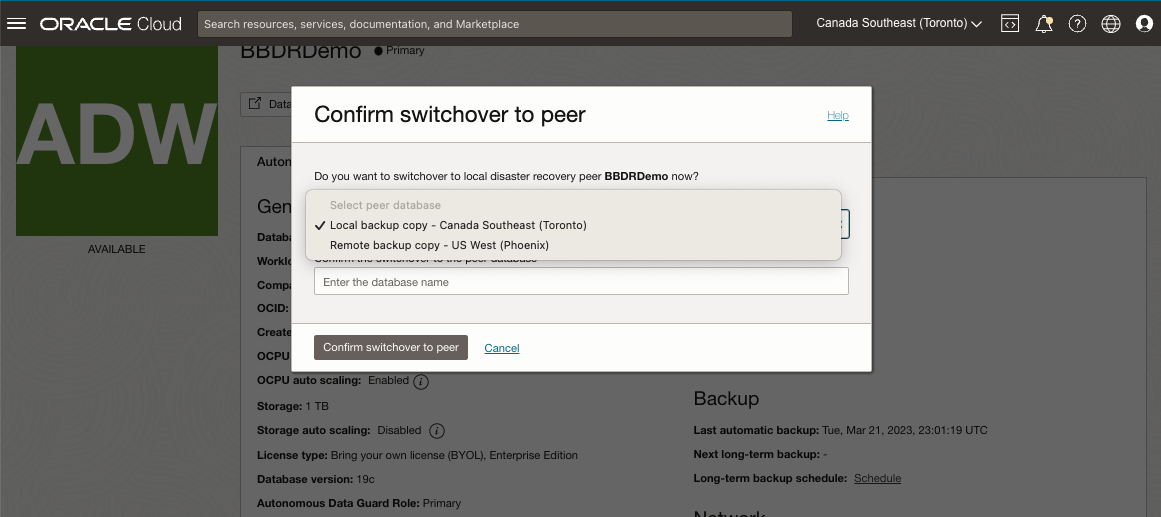
Since switchover guarantees no data loss, we always recommend attempting a switchover first in a failure scenario, only resorting to failover if switchover fails. Additionally, we recommend using switchover to test your applications against your disaster recovery configuation and this role change behaviour.
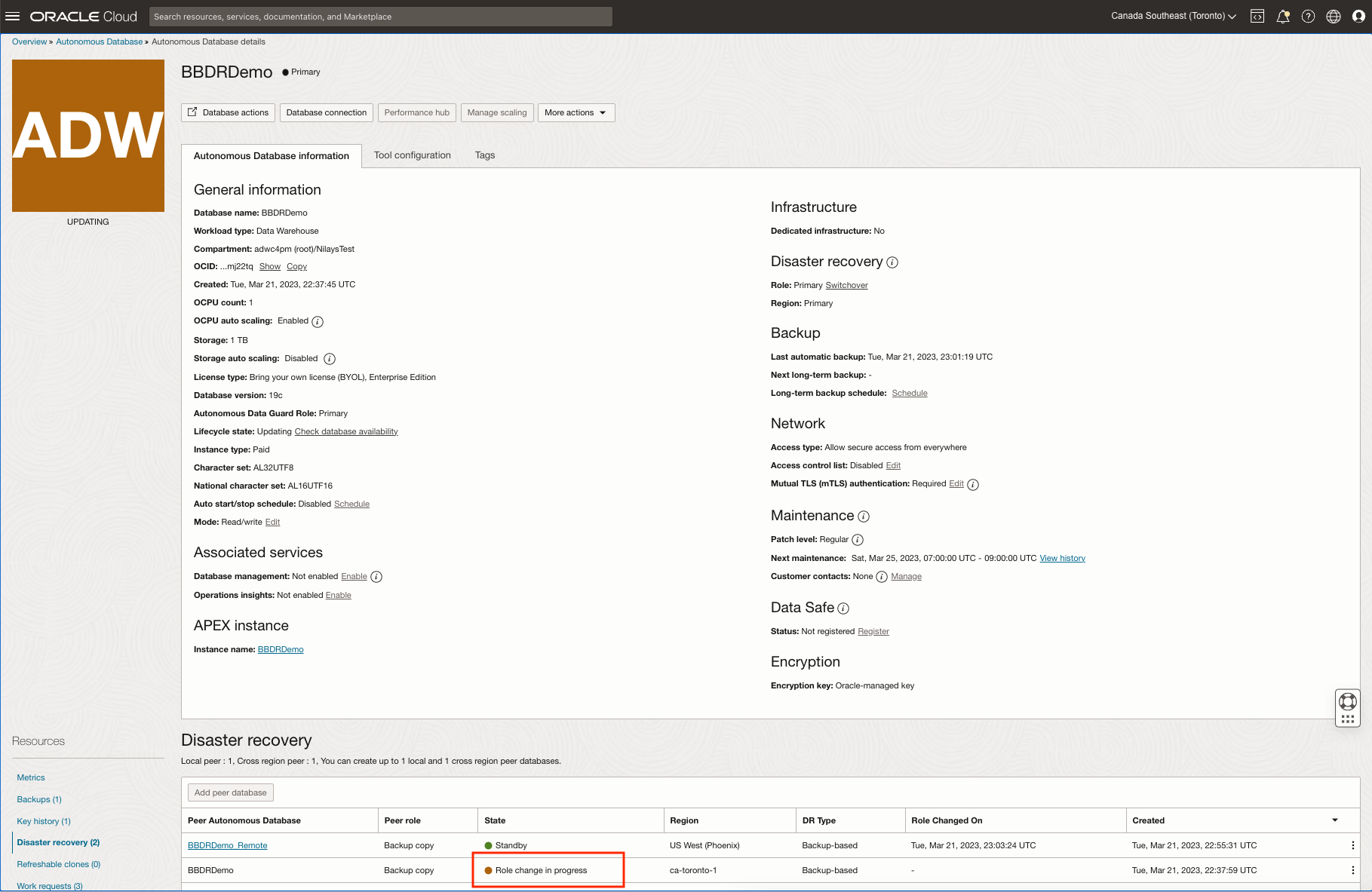
Failover – When your Primary database goes down due to a major outage, you are protected by your Disaster Recovery Peer
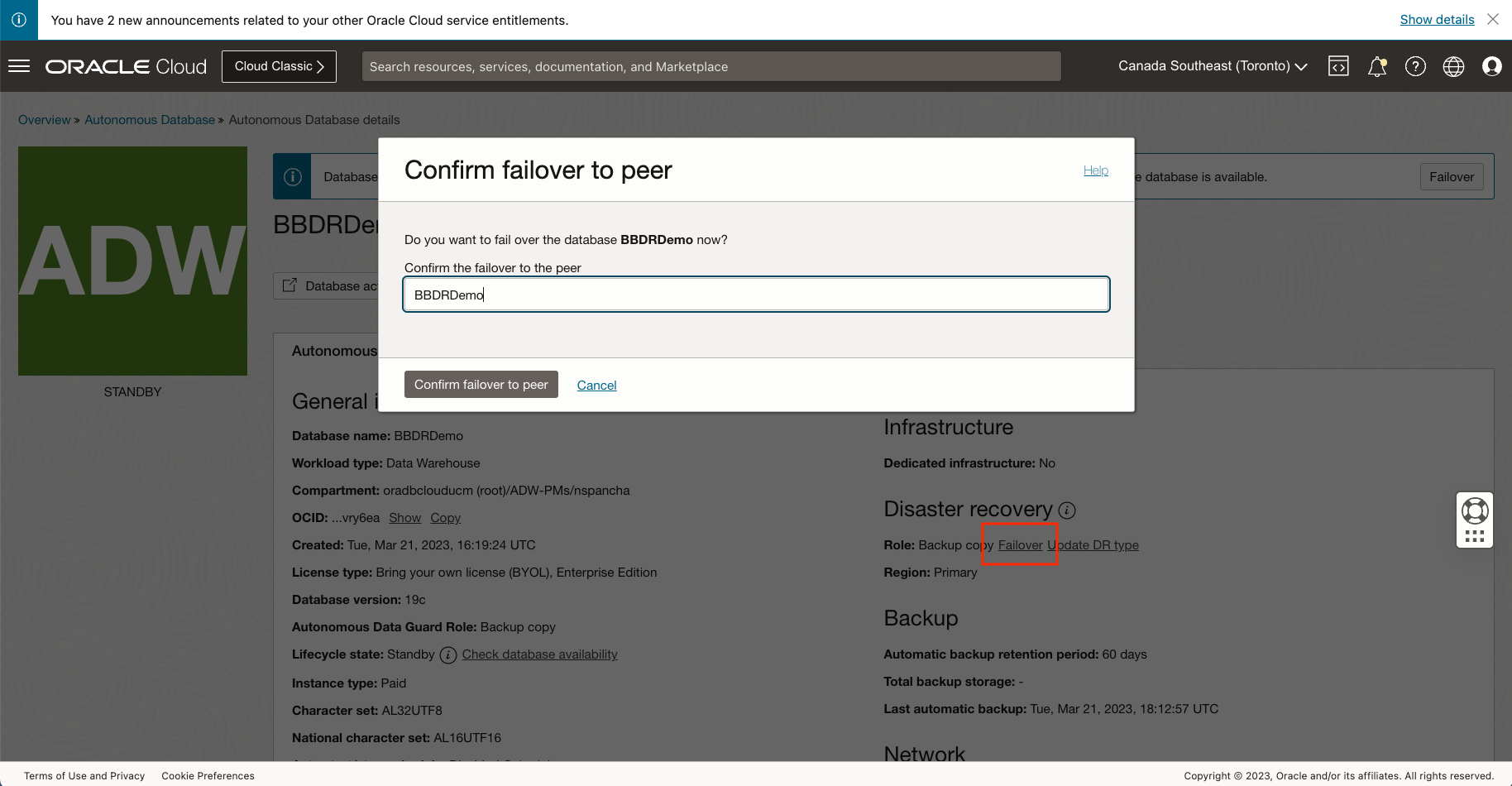
If a disaster were to occur and your primary database is brought down, you may “Failover” to your standby. A failover is a role change while the DR peer is available for use and in the “Standby” state, switching from the primary database to the your peer when the primary is inaccessible or switchover fails due to an outage. The UI here nudges users toward the recommended attempt a switchover first, before attempting a failover; You will only see a failover option if a Switchover fails. While calling the API, you may trigger either switchover or failover as per your need.
During a failover, the system automatically recovers as much as data as possible minimizing any potential data loss; however as mentioned above there may be a few seconds or minutes of data loss. You would usually only perform a Failover in a true disaster scenario, accepting the few minutes of potential data loss to ensure getting your database back online as soon as possible.
Note, as with AuDG, to failover to a cross-region (remote) peer, trigger the switchover from the remote region peer. Also note that that backup-based disaster recovery does not provide automatic failover for local DR as local AuDG does, since the RTO for backup copies is significantly longer. If your setup requires automatic failover, use Autonomous Data Guard.
Once a switchover or failover is complete and the region or machine you switched over from is available, you will once again, automatically see your the connected previous primary update and be made available for use as a disaster recovery peer, for you to switchover or failover back when necessary.
You may track the progress and actions during your disaster recovery setup (and other ADB actions) under the Work Requests tab, on the database console.
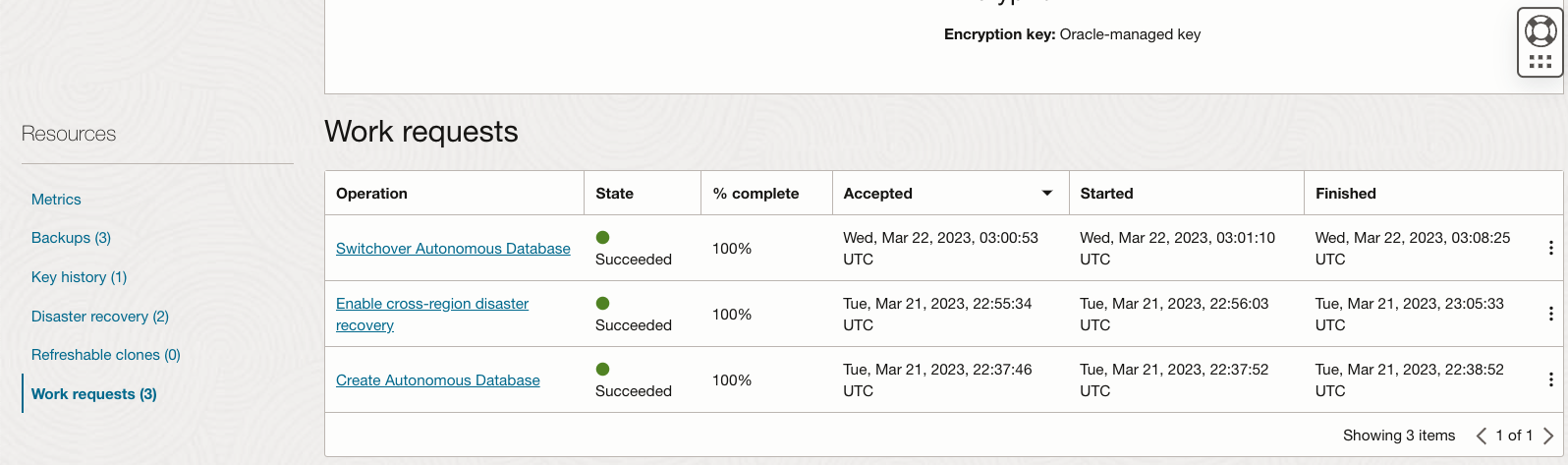
We talked above about all of the options on the database UI console. Of course, as with the rest of Oracle’s cloud platform, there are Autonomous Database APIs for all the actions mentioned above, including Switchover and Failover, that can be scripted as per your automation needs at any time. You may also subscribe to useful Events to be notified of your DR peer’s operations. Read all the details about backup copies and standby databases by referring to the official documentation. Backup-Based Disaster Recovery is also available in other Autonomous workload types – Autonomous JSON Database and the APEX Service.
In conclusion, backup-based disaster recovery adds a critical and accessible piece to Autonomous Database’s disaster recovery and extreme reliability story. By enabling it on your database, you can protect your data, minimize downtime and ensure business continuity. It’s a cost-effective way to avoid the risks of data loss and downtime, and meet compliance requirements all while having peace of mind.
With this new low-cost disaster recovery option there is really no excuse – Every Autonomus Database user out there should make use of this easy-to-use feature and be well-protected against local and regional failures.
Like what I write? Follow me on the Twitter!
