As data centers grow, comprehensive monitoring of data becomes more complex and costly. Each resource in the data center may generate large amounts of pipelined data, such as, data related to usage patterns, resource consumption, performance and availability, or diagnostic data. Quick access and efficient search for relevant data is essential for accurate analysis whether for business or service-related events. This critical data is usually indexed for faster search engine retrieval and commonly stored together, data and indexed metadata, in expensive, dedicated hardware. This expense has prompted a need for alternative, more cost-effective storage solutions such as cloud vendor object storage services like OCI Object Storage, AWS S3, Azure Blob Storage, or GCP Cloud Storage. The Autonomous Database Data Lake Search is an Autonomous Database native search application built on APEX available for download from the Autonomous Database AppStore, and which enables multi-cloud search capabilities, where your searchable data may be stored in your preferred cloud vendor object storage. The indexed metadata, however, will be stored in your Autonomous Database and accessed through and managed by the Autonomous Database Data Lake Search APEX application. This application is your index management and search interface for structured or non-structured data stored in OCI Object Storage, AWS S3, Azure Blog Storage, and/or GCP Cloud Storage.
The Autonomous Database Data Lake Search application provides:
- Multi-cloud, cost-effective object storage search capabilities
- Index metadata stored in low-cost Oracle Autonomous Database
- A no cost, no maintenance APEX search application running on Oracle Autonomous Database
- Precision multi-filter fusion search capabilities on structured (JSON) or non-structured (text, csv) datasets
- Log enrichment
- Trace analytics
- Single row and surrounding document retrieval
Leveraging external indexing of structured or non-structured data involves a strategic shift to secure, cost-effective storage solutions. One standout feature of this implementation is a more efficient use of storage. Autonomous Database Data Lake Search application allows you to configure and access your data from any cloud vendor object storage, ensuring no data is duplicated and where only the external indexed metadata is stored in the Oracle Autonomous Database. This model ensures scalability and significantly reduces operational costs compared to dedicated hardware and traditional database storage.
The Oracle Autonomous Database Data Lake Search application is an Oracle Autonomous Database native APEX application that removes the complexity of document index management and search. Application patching and enhancements are autonomously managed and applied by user-initiated updates.
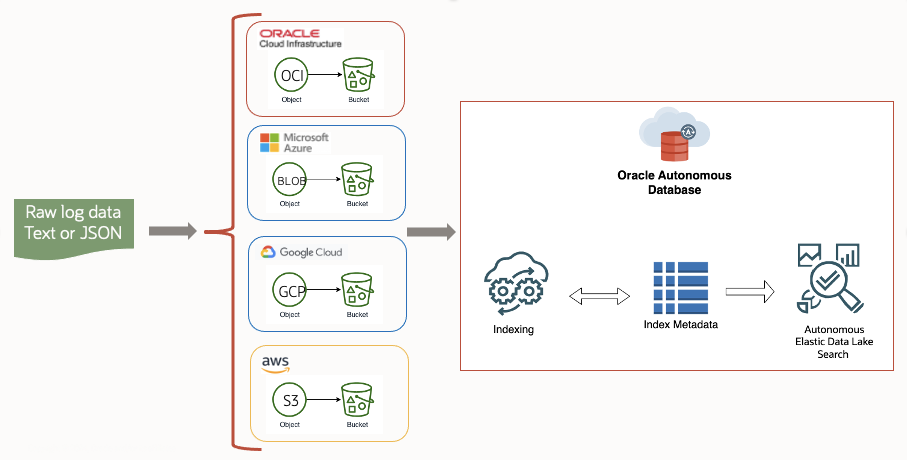
Figure 1 ADB Data Lake Search Topology and Workflow
Comprehensive Indexing and Search Capabilities
The intuitive UI abstracts the complexities associated with creating and maintaining indices, and serves as a centralized platform, empowering users with comprehensive search and filtering capabilities across multi-cloud datasets. The application has 4 intuitive workflows:
- Create the external index
- Extract the key fields from the target documents and assign to the index
- Manage Indexes
- Search UI
The following animated gifs walk you through each of these workflows.
Create External Index:
The Create External Index workflow below is a simple, comprehensive index creation for structured or non-structured data which calls the DBMS_CLOUD.CREATE_EXTERNAL_TEXT_INDEX API. The workflow requires 4 inputs:
- The location URI for the object storage where your documents are stored
- The index name you chose for the index
- Whether to enable JSON support for the index
- Whether to support gzip compression
As described below, you enter the URI for the object store where your documents are stored, define the index name, enable JSON by clicking on the JSON radio button (the default is non-structured data – text, csv), and if required, indicate gzip support under the Advanced drop down menu by selecting gzip compression. When you Submit, for indexes created with JSON support enabled, we provide advanced JSON capabilities. This includes parsing all JSON documents to extract key-value pairs. Additionally, we identify the schema template for the index and present users with a selection of available fields.
Figure 2 Create External Index
Extract Keys:
The keys pre-fetched in the create external index workflow are presented in the application and can be selected individually, or for all fields which correspond to your required search criteria. Once we click Finish, the relevant keys are extracted and available for search. The application then takes you to the Autonomous Database Data Lake Search home page where search operations are executed.
 Figure 3 Extract Keys
Figure 3 Extract Keys
Index Management:
The Index Management icon on the upper left takes you to the index admin dashboard. This dashboard shows you the available indexes that you have created, the total document count which are indexed, total size of the files for the respective index, an update schema option and trash icon to delete the index.
The index we will use in the example below, is an index created on database listener network logs for log analysis. When you click on an index name, you are directed to the page Object List which lists all associated objects/files, object size and last modified timestamp related to objects/files for that index. The filters on the left allow you to switch between available indexes within the Object List dashboard and modify the date range for either coarse grained or fine grained search. In this demo, we have a pipeline data flow from multiple hosts to the object store and this shows us the files that have been uploaded to object store in the last 15 minutes. The date range filter allows you to modify the date range on pre-defined time or custom defined date range.
 Figure 4 External Index Management
Figure 4 External Index Management
Search Demo:
The following animated GIF is to demonstrate the navigational flow and search capabilities of the Autonomous Data Lake Search APEX application. The use case we explore is searching through database listener network diagnostic logs to identify connection errors (TNS-12514) mapped to specific PDBs and hosts. We explore 3 fundamental search operations:
1. Filtered search on defined index keys
2. Free-form text search
3. User defined index key search with operators: IS, IS ONE OF, EXISTS
As we navigate through the demo, we validate our searches using the pre-defined index key filters. Our document examination includes single row document views and surrounding document views related to the targeted search criteria.
Figure 4 Search Demo
Conclusion:
The Autonomous Data Lake Search APEX application provides an Autonomous Database native search interface that is multi-cloud enabled leveraging cost effective storage. The application is integrated with the Autonomous database and is maintained autonomously in that configuration, patching and upgrades are managed for you, further minimizing operational costs. Check out the Autonomous Database AppStore for installation instructions and explore the other applications available to you.
Contributing Authors: Ramachandra Gopal Posina, Vaibhav Khanduja
