Today, organizations have many cloud data platforms to choose from. You may prefer Oracle Autonomous AI Database for its powerful capabilities like fully automated management, powerful converged data architecture, and sophisticated SQL that helps simplifyies complex analytics. On the other hand, you may prefer an Iceberg-based data platform for its openness in terms of analytic engines and data formats.
The great news is – you don’t have to choose one or the other. Oracle has just announced new capabilities for Autonomous AI Database that enables you to combine the best of both as a single data platform. In this blog, we’ll explore powerful new capabilities now available for the Autonomous AI Database Catalog that allow you to find, understand, and query data across your data platform, whether you choose to load the data into the database or not.
Enterprise connectivity with Autonomous AI Database Catalog
The Autonomous AI Database Catalog simplifies connectivity to enterprise data assets and queries against those sources using SQL clients. You can then use a federated approach to data access, where data is not moved from its current store, or use simple options to load or continuously feed data into the database. The catalog can already connect to many databases both cloud and on-premises, cloud storage systems, data catalogs such as AWS Glue, and data shared using Delta Sharing.
Now we have added two important new features to the Catalog to make connecting and integrating disparate data even easier:
1. Iceberg catalog access
2. Plug and play SQL query access to all catalog data
Iceberg catalog access
Iceberg is one of the most popular open table formats among data science and AI communities. The Autonomous AI Database Catalog now supports Iceberg catalogs – allowing your Oracle database apps, tools, and analytics to access Iceberg tables seamlessly. You can search, discover, preview and query any Iceberg table in any Iceberg catalog, on any cloud.
We have initially certified catalog access with AWS Glue, Snowflake Open Catalog, Databricks Unity, and Apache Gravitino Iceberg catalogs, but practically any Iceberg catalog can be added with just a few simple steps.
Once added, you can then search those catalogs to find tables needed for analytics.
Plug and play SQL query access to data in all catalogs
To make it even easier to access catalog data from any SQL client, we have made an important addition to the SQL syntax on the Autonomous AI Database. You can now query any tables in any connected catalog using syntax such as
select * from owner.table@catalog;
Under the covers, this simple SQL is converted into the right type of query for the relevant data using the Catalog’s metadata. Where the table referenced in the query is in another connected database, the query will use existing database link syntax. Where the table referenced is in another type of catalog, such as an Iceberg catalog, the query generates an ‘inline’ external table to query the data.
This is a real game-changer for analytics because it enables users familiar with SQL and users who are using AI-based natural language queries, like Autonomous AI Database Select AI, to perform analytics on the whole enterprise data ecosystem, without having to move or copy data into the Autonomous AI Database. See Figure 1 below.
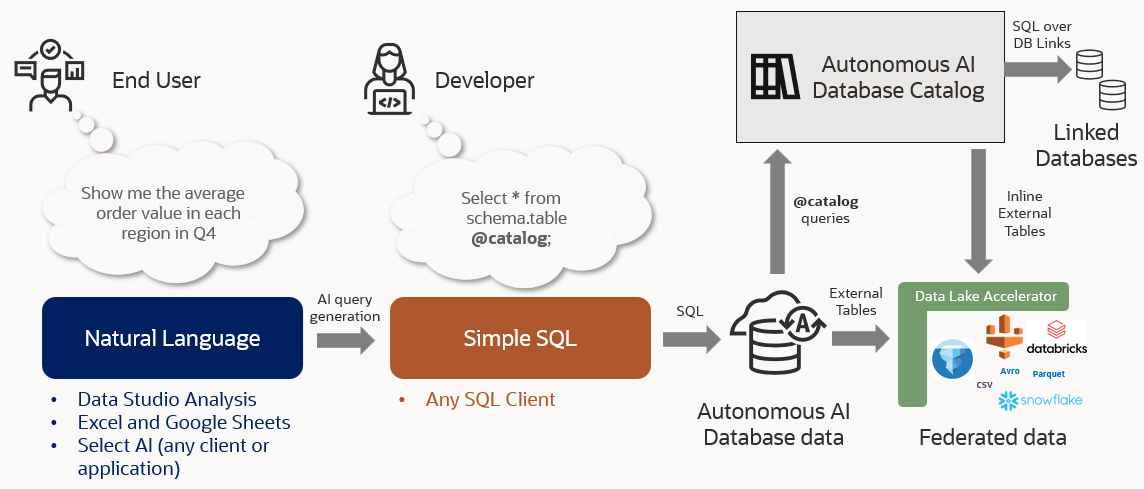
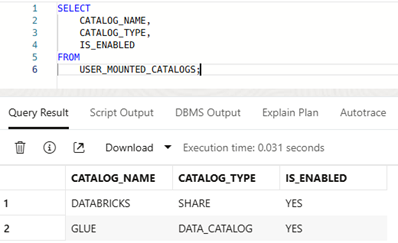
In addition, this new feature makes it very simple for users to query the catalog metadata from SQL, so they can determine which catalogs are available and what they contain. To see a list of all additional catalogs available on an Autonomous AI Database instance, you can use the following simple query:
SELECT CATALOG_NAME, CATALOG_TYPE, IS_ENABLED FROM USER_MOUNTED_CATALOGS;
For example, if you have two catalogs set up on your Autonomous AI Database, these will be listed in the query response:
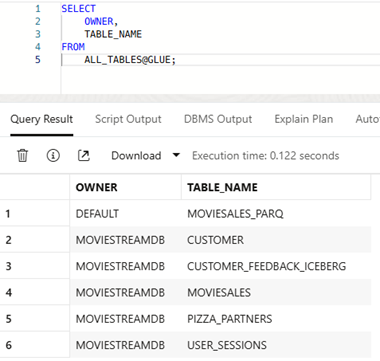
Then, you can run a query to list the available tables and their owning ‘schemas’ from any enabled catalog. For example, to see which tables are available in the ‘GLUE’ catalog above you can use this query:
SELECT
OWNER,
TABLE_NAME
FROM
ALL_TABLES@GLUE;
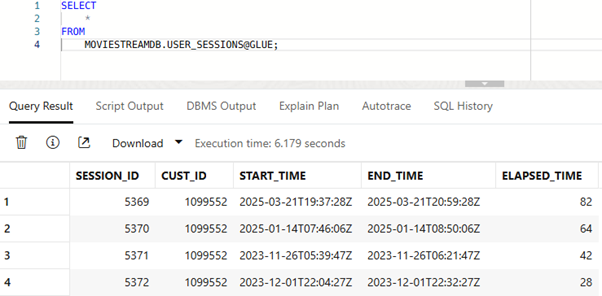
Now that you know the schema and table names to use, you can go ahead and query the data, using the simple SELECT * FROM OWNER.TABLE@CATALOG syntax:
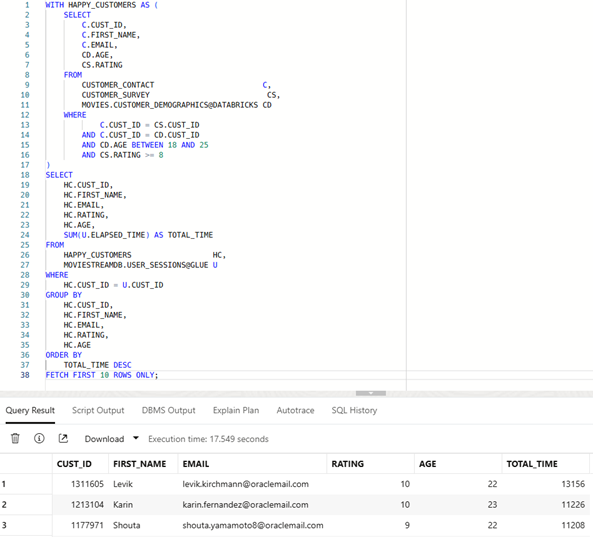
And, of course, you can combine queries on this external data with any data already available in the Autonomous AI Database. The example query below (Figure 5) finds the top 10 movie watchers who are aged 18-25 and ‘happy customers’ (those who gave a favorable rating for a fictonal movie service). Note that the data is distributed over several catalogs:
-
The main customer data has been loaded into Autonomous AI Database
-
The demographic data is on Databricks, and
-
The user session data that measures movie watch times is stored in an Iceberg table with an AWS Glue Data Catalog
See how this works through a quick demo: https://www.youtube.com/watch?v=XubFc-QHgsc
Natural Language queries over catalog data
This article shows how the catalog can simplify data access using SQL, but what if you want to access the same data without any knowledge of SQL? Can data be retrieved through natural language questions instead? The answer is yes. A data set in any connected catalog can be accessed using all the database’s SQL access paths – including the Autonomous AI Database Select AI’s natural language query capability. You just need to add views over the required catalog sources to your Select AI profile so that the Autonomous AI Database will consider them when generating SQL queries from natural language prompts. Adding a well-named view will also improve Select AI’s ability to understand the data semantics and so translate a natural language query into a working SQL query.
Summary
The catalog plays a key role in enabling organizations who want to combine the openness of Iceberg with the powerful capabilities of Autonomous AI Database. Furthermore, you can use it along with other data tools within the Autonomous AI Database to simplify the whole analytic workflow—discovering data with the catalog, then loading, preparing, and modelling it according to your needs.
The catalog continues to enhance its capabilities to support new integrations and new options to enrich enterprise metadata and improve productivity in data discovery, AI, and analytics. Look out for further announcements!
Get Started
For more information to get started, check out these resources:
- Try Oracle Autonomous AI Database for free
- Learn more about Oracle Autonomous AI Database
- Learn more about Data Studio
- Autonomous AI Database Catalog Documentation
- Live Lab: Data Studio: Self-service tools for everyone using Autonomous AI Database
- Live Lab: Data Engineering: Build a Data Platform with Autonomous AI Database
- Live Lab: Build a Data Lake with Autonomous AI Lakehouse
