Today, we released an exciting and useful new feature to wrap up the year strong – Data Pipelines in Autonomous Database (ADB). Data pipelines provide a continuous, incremental and fault-tolerant way to export and import data into ADB. With data pipelines, you can quickly and automatically load data into your database such as from your object store, as your ETL jobs and other data sources bring in new, clean data into your object store.
If you are loading data into or exporting out of ADB today, you are likely familiar with the DBMS_CLOUD package that provides the ability to load data into your database from the object store with DBMS_CLOUD.COPY_DATA or export data to your object store using DBMS_CLOUD.EXPORT_DATA. You may find yourself performing these operations repeatedly (you may even have scheduled jobs) to work with new data that is flowing into your object store or tables. This new Data Pipeline feature introduces the package DBMS_CLOUD_PIPELINE to simplify and automate this process, providing a unified solution of scheduled jobs for periodic data load and export of new data files with intuitive configurable knobs, legible troubleshooting outputs and default parallelism for optimal scalability.
The two types of data pipelines available are:
- Load Data Pipelines: Data pipelines used for periodically loading data into the database, from new data files lying in your object store of choice. Some use cases for load pipelines would be:
– Continuous migration of new on-premise data sets into the database via the object store of choice, using a load pipeline
– Loading new, incoming real-time analytic data or outputs of an ETL process into the database using a load pipeline, via data files store in the object store
- Export Data Pipelines: Data pipelines used for periodically exporting new, incremental data as results from a table or query in the database, to the object store of choice. An example use case for export pipelines would be:
– Exporting new time-series style data generated by your application from the database to the object store at periodic intervals
Now that we understand what a data pipeline is in ADB, let’s walk through how to create and set up a pipeline, to understand how it works. The steps you will follow to create and use a data pipeline are:
- Create a new data pipeline to either load data into the database or export data from the database
- Configure your data pipeline by setting the right attributes as it relates to your data
- Test that the data pipeline loads or exports some sample data as expected
- Start a pipeline to continously load or export your data
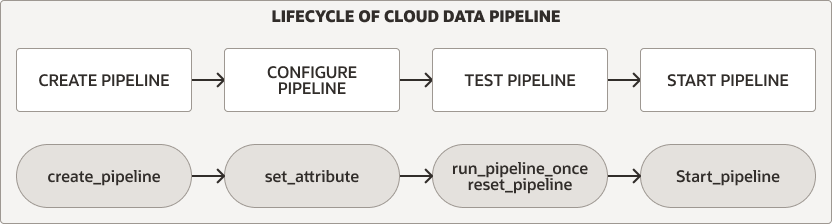
1) Create a new data pipeline
Begin by creating a data pipeline to either load data or export data continuously. Here, we have an example for creating a data pipeline to load data (Note the pipeline_type parameter):
BEGIN
DBMS_CLOUD_PIPELINE.CREATE_PIPELINE(
pipeline_name => 'MY_FIRST_PIPELINE',
pipeline_type => 'LOAD',
description => 'Load employee data from object store into a table'
);
END;
/
2) Configure your data pipeline attributes
Next, you will set the right attributes for the data pipelines, such as the type of data files (eg. json, csv) and the location where the data files will lie (eg. an object store bucket or file folder), as well as create the destination table in the database that your pipeline will load data into. In this example, we are considering employee data so let’s create the destination table “Employee”:
CREATE TABLE EMPLOYEE (name VARCHAR2(128), age NUMBER, salary NUMBER);
We have defined the attributes for the data pipeline below – Importing all data files of JSON type from an object storage bucket location at an interval of every 30 minutes (the default is 15 minutes) with a priority selected as High (ie. the HIGH database service name)
If you will be loading data from an object storage URL as is recommended below, you will need to setup an object storage bucket and create a credential to access it.
Follow this LiveLab for step-by-step instructions on how to create an object storage bucket with your data files in it and a credential parameter to access it from your database. For the credential, you may also setup Resource Principles for the various different object store cloud providers to simplify access, if needed.
BEGIN
DBMS_CLOUD_PIPELINE.SET_ATTRIBUTE(
pipeline_name => 'MY_FIRST_PIPELINE',
attributes => JSON_OBJECT(
'credential_name' VALUE 'OBJECT_STORE_CRED',
'location' VALUE 'https://objectstorage.us-phoenix-1.oraclecloud.com/n/namespace-string/b/mybucket/o/',
'table_name' VALUE 'EMPLOYEE',
'format' VALUE '{"type": "json"}',
'priority' VALUE 'HIGH', 'interval' VALUE '30') );
END;
/
3) Test your data pipeline
Before we throw your configured pipeline into the deep end, let’s test that it works. Call the DBMS_CLOUD_PIPELINE.RUN_PIPELINE_ONCE procedure to run your pipeline once, on-demand. This will not create a repeating scheduled job.
BEGIN
DBMS_CLOUD_PIPELINE.RUN_PIPELINE_ONCE(
pipeline_name => 'MY_FIRST_PIPELINE'
);
END;
/
You can monitor and troubleshoot your pipeline’s running job via the user_cloud_pipeline_history view or the query status_table for each file in the pipeline via the user_cloud_pipelines view.
SELECT pipeline_id, pipeline_name, status, error_message FROM user_cloud_pipeline_history
WHERE pipeline_name = 'MY_FIRST_PIPELINE';
PIPELINE_ID PIPELINE_NAME STATUS ERROR_MESSAGE
----------- ------------------ --------- -------------
7 MY_FIRST_PIPELINE SUCCEEDED
If something did go wrong causing your pipeline’s file load to fail, you may query the database table USER_LOAD_OPERATIONS along with the operation IDs of your pipeline to get the related LOG and BAD files for the data load. This will provide insight into which lines in the data file cause a problem in the load.
-- More details about the load operation in USER_LOAD_OPERATIONS.
SELECT owner_name, type, status, start_time, update_time, status_table, rows_loaded, logfile_table, badfile_table
FROM user_load_operations
WHERE id = (SELECT operation_id
FROM user_cloud_pipelines
WHERE pipeline_name = 'MY_PIPELINE1');
--Query the relevant LOG and BAD files
SELECT * FROM PIPELINE$4$21_LOG;
SELECT * FROM PIPELINE$4$21_BAD;
(Optional – Reset Pipeline)
Before proceeding to Start your pipeline, you may use the DBMS_CLOUD_PIPELINE.RESET_PIPELINE procedure to reset the pipeline’s state and history of loaded files. As below, you may also optionally purge the data in database or object store. A data pipeline must be in stopped state to reset it.
BEGIN
DBMS_CLOUD_PIPELINE.RESET_PIPELINE(
pipeline_name => 'MY_FIRST_PIPELINE',
purge_data => TRUE
);
END;
/
4) Start your data pipeline
Now that we have tested that our data pipeline is successfully configured, all we have left to do is simply Start the pipeline.
Once your pipeline has been started, it is now running and since it is a load data pipeline, it will pick up new data files to load that have not been successfully processed yet, as they are moved into your object storage bucket.
It is important to note here that the load pipeline identifies, loads and keeps track of new data files by their filename; updating or deleting data from an existing filename that had already been loaded successfully in the past will not affect data in the database. The pipeline will also retry loading a previously failed file several times.
BEGIN
DBMS_CLOUD_PIPELINE.START_PIPELINE(
pipeline_name => 'MY_FIRST_PIPELINE'
);
END;
/
Data Pipelines greatly simplifies the repetitive nature of loading or exporting new data of similar structure, as it is being populated within a specified location or table. In addition to configuring your own data pipeline, we also provide Oracle-maintained data pipelines mentioned here out of the box, that are preconfigured to export database logs to a selected object store location.
As we wrap up an excellent year, I hope this feature finds its way into your Autonomous Database toolkit in the coming years. For more detail about Data Pipelines and other Autonomous features, refer to our well-written documentation.
We have several impactful and exciting new features coming early next year, so look forward to more of these posts and how-to’s very soon. Happy holidays folks!
Like what I write? Follow me on the Twitter!
