Autonomous Database is a great platform for querying and accessing data lakes in object storage. You can easily mix-and-match queries across data within your database and within your data lake. In order to efficiently scan data in object store, Autonomous Database provides optimizations for all common data types, table formats and directory structures in object storage.
Autonomous Database has now added support for Implicit Partitioning for External Tables. This accelerates query performance by enabling pruning of data based on logical conditions (for example, accessing data for a given month or product line).
This new feature also makes it much easier to create and manage these partitioned tables. Simply by pointing to the root directory for your table’s files, you can create a partitioned tables across thousands of partitions and millions of files with a simple command. Moreover, as you add new directories and files to your table in object storage, this new data is automatically recognized by Autonomous Database with implicit partitioning since all of the partitioning-pruning is occurring at runtime; your external table is always up to date, and you never need to ‘sync’ your external table definition with your directory structures.
The details
External Tables with Implicit Partitioning automatically discovers the underlying partitioning structure based on the hierarchical structure of your files (e.g. Hive-style) and adds these additional partitioning keys to the external table as virtual columns. This feature supports Hive file organizations (directory structures like ‘/sales/country=USA/year=2024/month=01/’ as well as non-Hive (‘/sales/USA/2024/01/’).
This virtual columns (‘country’, ‘year’, or ‘month’) are added to the table definition and are used for data pruning when running SQL queries, allowing to skip unnecessary data segments. Unlike in the case of simplified partitioning, no maintenance or refresh is needed; the partition layout is detected at runtime. Partition structure is not captured in the database dictionary.
Code in action
Let me demonstrate how Implicit Partitioning works in action. Below is the code snippet that defines the structure in my object store and creates an external table named CUSTSALES. Here is Object Store structure we are working with:
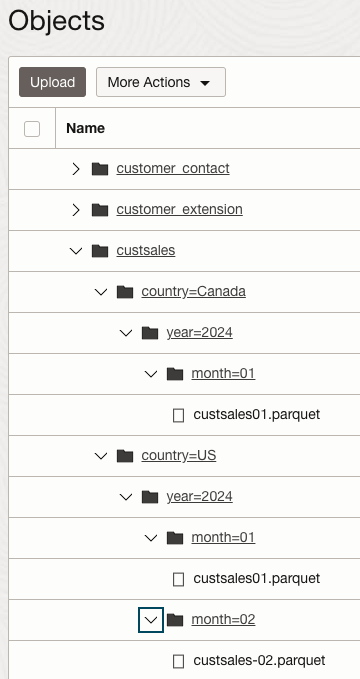
This table has 3 neasted layers of parititioning: county, yeas and month. I want to emphasize that this is an external table, not a partitioned external table. It uses implicit partitioning with the implicit_partition_type parameter set to ‘hive’. The new Implicit Partitioning feature enables Oracle Autonomous Database to automatically detect the underlying partition structure and create a virtual column. Consequently, I can query the table right after creation, using the MONTH column as a partitioning predicate to filter data efficiently.
DECLARE
l_TABLE_NAME DBMS_QUOTED_ID := ‘“CUSTSALES”’;
l_CREDENTIAL_NAME DBMS_QUOTED_ID := ‘“OCI_CRED”’;
l_FILE_URI_LIST CLOB := ‘https://objectstorage.us-sanjose-1.oraclecloud.com/n/mytenancy/b/moviestream_gold/o/custsales/*.parquet';
l_FORMAT CLOB := ‘{“schema”:”first”,”type”:”parquet”, “implicit_partition_type”:”hive”}’;
BEGIN
DBMS_CLOUD.CREATE_EXTERNAL_TABLE
( TABLE_NAME => l_TABLE_NAME
,CREDENTIAL_NAME => l_CREDENTIAL_NAME
,FILE_URI_LIST => l_FILE_URI_LIST
,FORMAT => l_FORMAT
);
END;
/
Example query using implicit partitioning:
SELECT * FROM CUSTSALES WHERE COUNTRY=’US’ and YEAR=’2024’ and MONTH = ‘01’;
By specifying predicates COUNTRY=’US’ and YEAR=’2024’ and MONTH = ‘01’, we force the database to read the only underlying directories that correspond to this filter.
Oracle’s early adopter customers are already witnessing significant performance benefits with this new functionality. It allows them to boost performance by 10 to 100 times over millions of partitions, even when dealing with hundreds of terabytes of data. These kinds of improvements are transformative, especially for data-intensive workloads
Conclusion
This illustrates how Oracle Autonomous Database automatically manages partitioning, enhancing query performance by skipping unnecessary data segments based on the partitioning predicate. If the underlying data structure in the Object Store changes, there’s no need to modify anything on Autonomous Database: You can simply run a query, and Autonomous Database will automatically reflect all changes in the data layer. I believe you’ll find it valuable when you are handling large datasets stored in Object Stores.
To learn more check out:
