More and more organizations are interested in using AI to help optimize or accelerate their business operations and processes. One of the emerging interests in using AI in business settings is using natural language to find answers on private, domain-specific content owned by an individual, a team, or an organization.
In Figure 1 we show a simple application that uses retrieval augmented generation – or RAG – to more easily gain answers from natural language queries. The app provides a quick start by using sensible defaults, or allows you to dig in and make customizations to match your specific requirements. In this blog we will show how Oracle Autonomous Database can help build such applications, speed up development and reduce architectural complexity.

RAG is an AI framework that combines information retrieval and natural language generation: instead of relying solely on pre-trained knowledge (i.e., embedded in LLM models), a system using RAG first retrieves relevant documents or data from an external source—e.g. a database or search engine—based on a user’s query; then, it uses a generative language model to produce a coherent, informed response using the retrieved content.
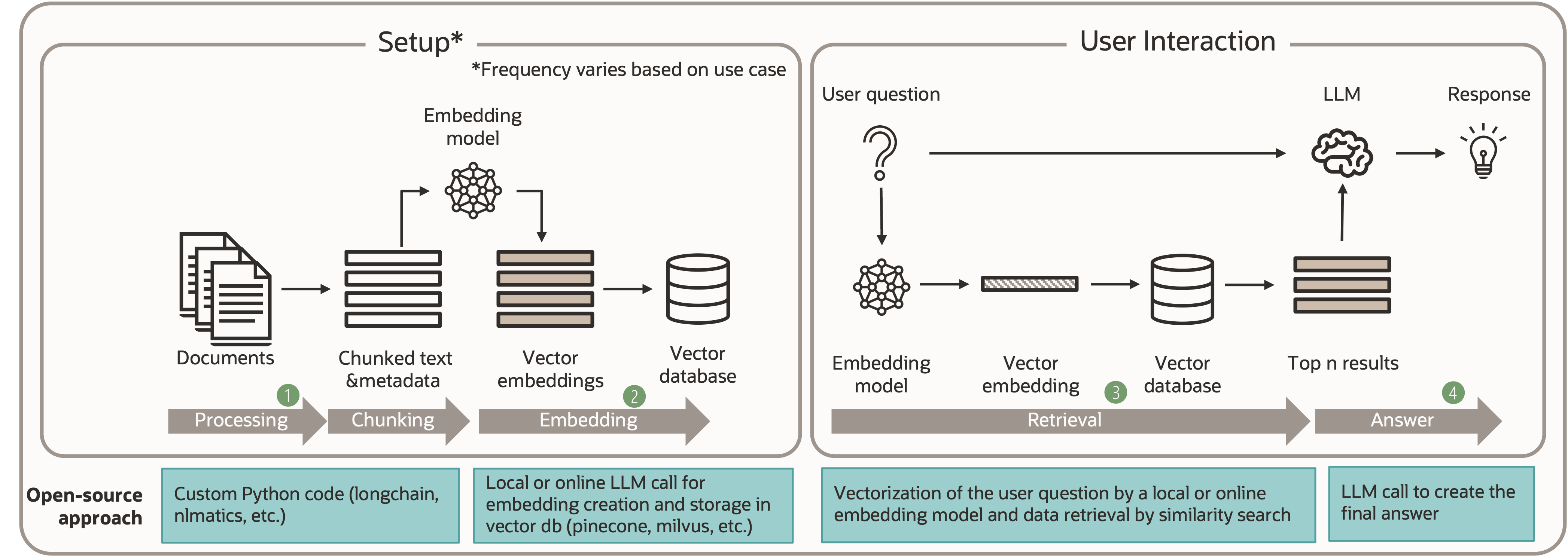
In Figure 2 we see a typical workflow broken into two parts. First, the setup ingests, processes and stores domain-specific content as vector embeddings. Then, the user interaction leverages that local knowledge – finding relevant content to help the generative AI model produce more informed and contextually-relevant results.
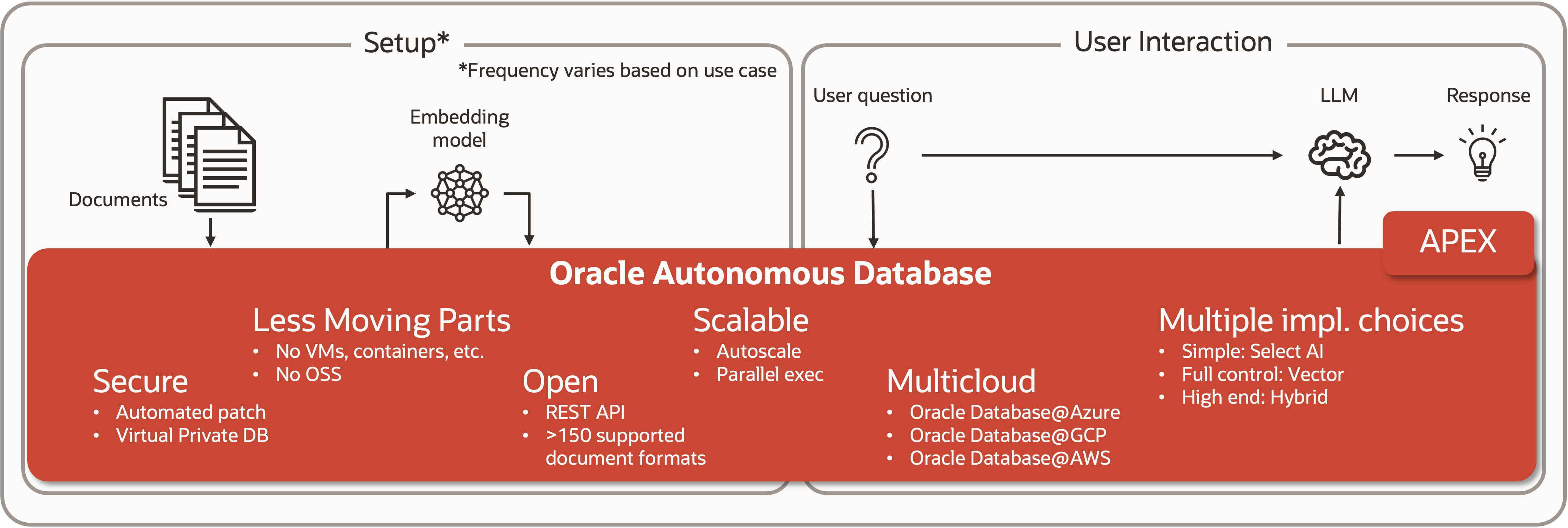
When it comes to implementing RAG, one may start by searching the wisdom on the internet: scanning the web for code examples will deliver an endless amount of “ready to cut and paste” material, mostly based on a vast range of open-source components. These examples are fully-functional, and the quality of the open-source libraries and components are generally good; the real issue is the complex architecture introduced when using different products and libraries (open source and not), as moving that into production can potentially introduce significant technical debt. On the other hand, using a single component like Oracle Autonomous Database for the RAG pipeline can be a huge advantage: it greatly simplifies the RAG architecture, especially in environments where Oracle Database is already deployed, potentially producing no additional technical debt.
To prove this point, we developed three “RAG in a Box” packages to showcase how Autonomous Database can address all the typical requirements of a RAG use case through multiple implementation choices, allowing for different needs of complexity vs. flexibility. Each package is available as a downloadable and ready-to-deploy code example with manual or Terraform automated installation (see links at the end of the blog).
”RAG in a Box” use case assumptions
Let us start first by clearly defining the basic requirements and assumptions of the RAG use case implemented in three demonstrations:
- Our local knowledge base consists of documents in multiple formats (e.g., Microsoft Office, PDF, text, etc.) hosted on an object store bucket. The content of the documents can be anything and everything: price lists, catalogs, industry presentations with footnotes, etc. However, for this particular use case, we will focus only on the text part of the content.
- Our users want to ask questions using natural language against source information from our domain-specific knowledge base.
- There should be an end-user GUI for ease of use. However, the implementation code should be decoupled from the GUI, allowing it to be reused or embedded in other applications.
- The implementation should use sensible defaults and allow further fine-tuning of the system if so desired.
Now that we have identified the requirements, let us go back to the workflow introduced in Figure 2 and dig a little deeper to better understand the tasks needed to build a RAG system:
- Documents need to be split into manageable chunks of text
- These chunks will be enriched with vector embeddings by using an embedding model. The results will be stored in a vector-capable database
- When a natural language query is submitted, the query text will be transformed into embeddings and passed to the vector database to perform a similarity search that returns text chunks that are the best fit for the given query
- Finally, the query text and the selected text chunks will be handed over to a large language model to create a natural language answer to be presented back to the user
Figure 3 below shows how implementing the RAG pipeline with Autonomous Database would simplify the whole architecture compared to an open-source based method (e.g., no Virtual Machines needed, no requirement for multiple open source software (OSS) stacks to maintain, support for various data ingestions and movement, built-in backup & recovery integration, etc.). On top of that, Autonomous Database provides additional significant enterprise-scale advantages, such as:
- Automatic scalability and performance tuning
- Best of breed security
- Automated software patching and updates
- Vector data co-location with other enterprise-relevant data, e.g. graph, geospatial, json, and relational content
- Multi-cloud deployment, available on Oracle Cloud Infrastructure (OCI), Microsoft Azure, Google Cloud, and soon AWS
- Sophisticated app development via built-in Oracle APEX
”RAG in a Box” implementation choices
Using Autonomous Database, you can choose from three “RAG in a Box” strategies to program a RAG pipeline. There is nothing you need to install or configure – the capabilities are built into Autonomous Database:
- Select AI framework
- Direct Vector index usage
- Direct Hybrid Vector index usage
Since these three implementation strategies are quite different, let us walk through their most salient points:
Select AI
The Select AI framework simplifies building AI pipelines using the built-in Oracle Database 23ai capabilities. Select AI will take care of the necessary file scanning, text chunking, creation of the necessary embeddings, and storage of such information automatically. If absolute ease of use is your goal, the Select AI framework allows for a simple and short coding cycle with only three major steps:
- Create a profile (see Figure 4) containing all the necessary information and credentials to define and access the embedding model (task 2 in Figure 2).

Figure 4 – Select AI profile creation exampleCaption - Create the Select AI vector index (Figure 5) providing the credentials and the path for the domain-specific content (the object store bucket hosting the files) and linking it to the profile created in the previous step. This call implements tasks 1 and 2 in Figure 2.

Figure 5 – Select AI index creation example
Once creation of the vector index is completed, users can start asking questions using the “Select AI …” SQL query syntax. The query example in Figure 6 shows the integration into the SQL language of a natural language question. Any SQL-based tool can ask this question and get results. This maps to tasks 4 and 5, enabling an easy integration of RAG within any application that’s capable of processing SQL statements.

Direct Vector Implementation
Another way to implement a RAG pipeline using Autonomous Database is to use direct calls for each of the needed steps. Although the coding complexity is higher than the Select AI option, one gains freedom of choice in multiple aspects of the implementation: processing options for chunking, embedding, and selection phases; creation and maintenance option for the session history and context, and how the prompting to the final LLM transformation, which will shape the way the answer is formulated, is implemented:
- Packages like dbms_vector_chain.utl_to_chunks() and dbms_vector_chain.utl_to_text() are used for text chunking (task 1 in Figure 2). Once the text is chunked, calling dbms_vector.utl_to_embedding() will create the embeddings (maps to task 2).
- A query to the system will need to go through the same embedding process as above and then use a vector_distance() call to produce a result set that includes the most fitting pieces of the domain knowledge base (task 3).
- Finally, the result set, along with the question and optionally an additional context (the session “memory”), will be passed to an LLM service along with a prompt to produce the final answer (task 4).
Direct Hybrid Vector implementation
Hybrid vector indexes, is a new 23ai feature that bridges two distinct areas of information retrieval: semantic-based queries based on similarity searches through vector distances (“which text is semantically closer to the query?”) and a classic keyword-based file scanning (“which text contains these keywords?”). Oracle Text, the keyword searching capabilities in Oracle Database, has been available for decades and allows you to create keyword indexes on more than 150 different file formats and access them using the CONTAINS syntax.
In the context of RAG implementations, it is not unusual to see two different queries directed at two different technology stacks – one for similarity searches using vectors and another for keyword-based ones – being subsequentially joined through a reranking phase as the final result set. With Oracle Database 23ai, you can now create a hybrid vector index, which combines the semantic and keyword searches, eliminating the need for the expensive merge/reranking phase.
From a code complexity point of view, the hybrid implementation is in between the two previously outlined coding strategies:
- The source and chunking parameters are bound together in two preference sets (dbms_vector_chain.create_preference() and ctx_ddl.create_preference()) after which the create index statement will be invoked (see Figure 7, mapping to tasks 1 and 2).

Figure 7 – Hybrid Vector index creation example - Completely transparent to the user, two different indexes (text and vector) will be automatically created and maintained, while a single query interface (dbms_hybrid_vector.search()) allows for combined searches (task 3). The user can assign different weights to the vector and text results, allowing for the fine-tuning of the result set based on the attributes of the particular domain-specific knowledge base.
How to implement “RAG in a Box”
All three “RAG-in-a-Box” packages implement the same RAG requirements described above with fully functional code, giving you a running start in implementing RAG. They are available on our GitHub repository with instructions for manual installation as well as fast and simple installation via Terraform.
- Select AI RAG-in-a-Box on GitHub
- Direct Vector Index RAG-in-a-Box on GitHub
- Direct Hybrid Index RAG-in-a-Box on GitHub
The code has been written for reuse and is decoupled from the corresponding APEX GUI. You can use it with any application that’s capable of calling PLSQL procedures, including headless ones.
The supplied GUI has two modes: default and expert. Default setting gives you access to a basic RAG system, while the expert setting provides a way to allow fine-tuning and experimentation with various parameters.
For more information on AI Vector Search and RAG, check out our documentation:
