In order to meet the increasing requirements of running more analytical jobs to get more insights into my organization’s data and reap benefits from it, it makes more sense to move Big Data pipelines to the cloud, as this meets requirements of building and deploying clusters within minutes with simplified user experience, scalability, and reliability. You can custom configure the environment, administer through multiple interfaces, and more importantly, scale on demand. This blog is authored by Rachit Arora from the OCI engineering organization.
There are many advantages to running Big Data and AI pipelines on the cloud, BUT — What about the security?

Let’s understand the different rings (layers) of security that are there to protect my data, my application, and my organization on the cloud and how to make the best use of them.
In this story, we will understand the following:
- Overview of Big Data and AI Pipeline: This will help us understand the different surface areas where we can expect to get attacked.
- Common Threats: to know what the common means of attack are,
- Rings of security: to know what protection layers are available and why we should not disable them
- Continuous security pipeline — What is it and why is it important?
- Shared responsibility — Not everything is cloud vendor responsibility.
Overview of Big Data and AI Pipelines
There are 5 main stages of a typical Big Data/AI pipeline.
- Capture — This stage is to get data from internal & external sources.
- Data sources (mobile apps, websites, web apps, microservices, IoT devices, etc.) are instrumented to capture data.
- Ingest — This stage is to get data through batch jobs or streams.
- The instrumented sources pump the data into various inlet points (HTTP, MQTT, message queue, etc.). There can also be jobs to import data from services like Google Analytics. The data can be in two forms: batch blobs and streams.
- Store — This stage of data persists in a data lake or data warehouse.
- Often, raw data and events are stored in data lakes, where they are cleaned, duplicates, and anomalies removed and transformed to conform to the schema. Finally, this ready-to-consume data is stored in a data warehouse.
- Analyze — In this stage, data is processed using aggregations and/or ML features.
- This is where analytics, data science, and machine learning happen. Computation can be a combination of batch and stream processing. Models and insights (both structured data and streams) are stored back in the data warehouse.
- Visualize This stage is to use dashboards, data science, and ML.
- The insights are delivered through dashboards, emails, SMSs, push notifications, and microservices. The ML model inferences are exposed as microservices.

With the growth of many open source components, it is very difficult to generalize and map the different options available for each stage, but for reference, we can use the following diagram to understand the most commonly used components for each stage of the Big Data and AI pipeline.
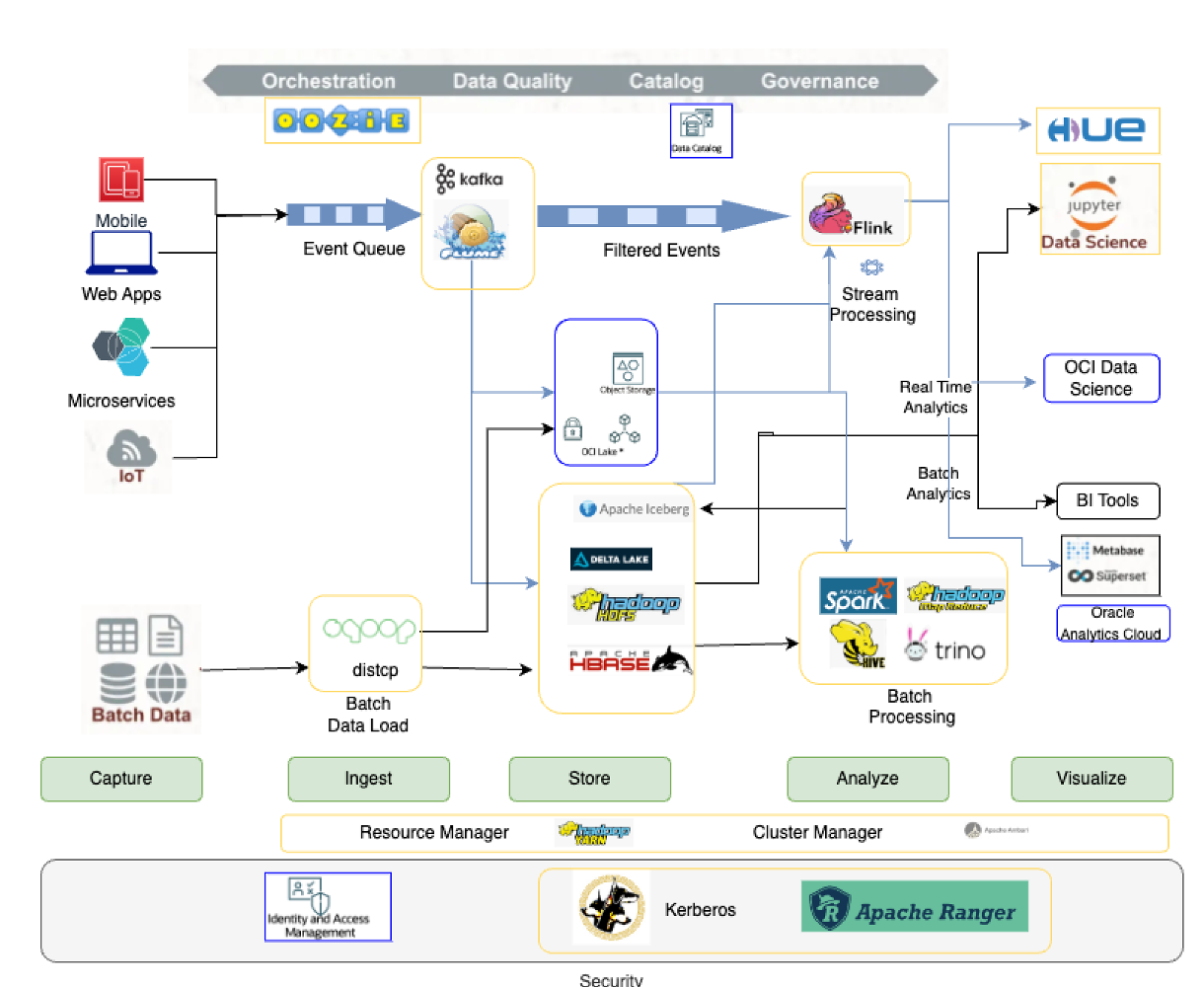
The following table shows a list of open source components widely used in each stage. Please note it is not an exhaustive list but a reference list from popular components.
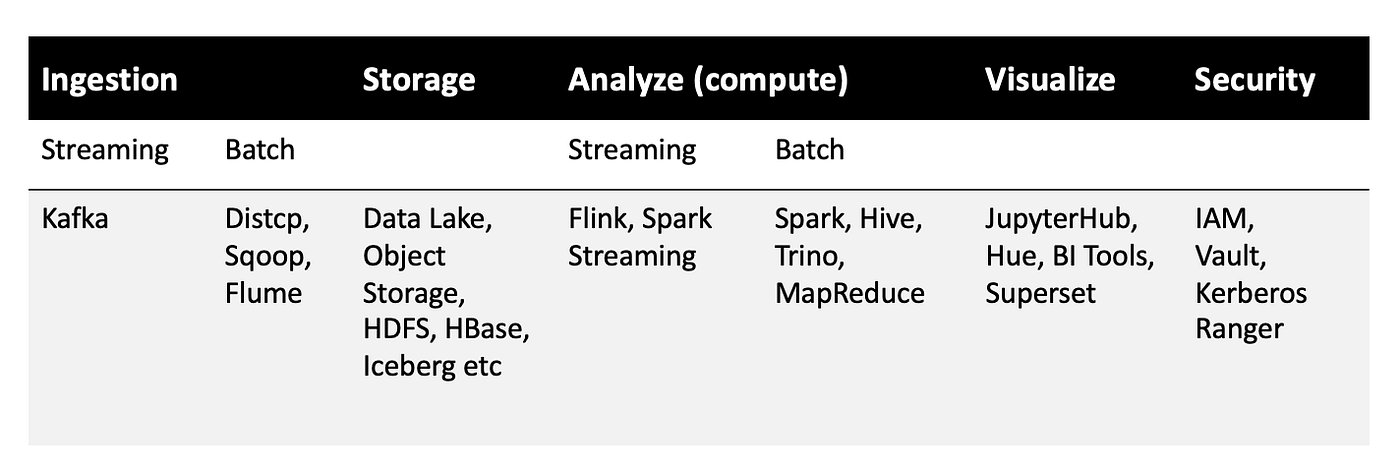
So now you will understand that a typical Big Data and AI pipeline involves a large number of components, which increases the surface area of attacks.
Each of these components, no matter how mature, is vulnerable to new attacks, new security issues (also known as CVEs), and vulnerabilities. It becomes very critical to adopt the best security measures to protect against security attacks.
Common Threats
There are hundreds and hundreds of threats that are applicable to any Big Data and AI pipeline, but just to give a reference, here are a few common ones that one should be aware of.
- DDoS — a distributed denial-of-service attack — occurs when multiple systems flood the bandwidth or resources of a targeted system, usually one or more web servers.
- Data Theft — When data is taken by someone without the owner’s consent or authority.
- SQL Injection — is a code injection technique used to attack data-driven applications in which malicious SQL statements are inserted into an entry field for execution.
- Cryptojacking — is the act of exploiting a computer to mine cryptocurrencies, often through websites, against the user’s will or while the user is unaware.
- MITM and Session Hijacking: A man-in-the-middle attack is a general term for when a perpetrator positions himself in a conversation between a user and an application.
- XSS — Cross-site Scripting — attacks are a type of injection in which malicious scripts are injected into otherwise benign and trusted websites.
- Unauthorized data access — when some regular user gets access to the data, knowingly or unknowingly, that this user is not supposed to view or use.
- Malware attacks- Opening tunnels to access the VMs in the cloud is a requirement sometimes, as the hosts are accessed for malware attacks.
Rings of security
There are many security measures that can be taken to protect your Big Data and AI pipelines from security attacks, and we can classify these protections into five different layers referred to as the Rings of Security.
Ring 1 — Network Security
Ring 2 — Perimeter Security
Ring 3 — Authentication
Ring 4 — Authorization
Ring 5 — OS/Storage Security
Let’s try to understand these Rings a little more.
Ring 1 — Network Security
One of the key ways to protect your Big Data and AI pipelines is by protecting the compute runtimes. Many cloud vendors provide the option of creating the runtime on a private network or in a designated VCN (virtual cloud network), which prevents anyone from reaching out to your cluster until you open up the firewall, usually done using security lists (again a feature provided by cloud vendors). If you need more details, here is the link to one of the cloud vendors (OCI) offering a security list.
You also get the option to control both inbound and outbound network traffic. This is coupled with the option to use an external load balancer (a managed service) to access the cluster endpoints instead of directly opening up the endpoints to add protection against DDoS attacks and other attacks, which these managed load balancer services are designed to mitigate and provide protection against.
One should also have Bastion node creation to provide terminal access to the cluster instead of allowing users to directly login to the cluster.
Ring 2 — Perimeter Security
The next level of security is provided by securing access to the Big Data and AI pipeline communication engines over secure access, both for accessing them outside a cluster as well as for intra-cluster communication. You should always select the option to enable TLS/SSL for all the compute engines running your big data and AI workloads. You should avoid using wildcard certificates when configuring TLS, use more bits in certificates, and Rotate certificates and keys at regular intervals (do not go for very long rotations lasting more than 180 days). Make sure you are selecting strong ciphers while communicating with different server components in your Big Data and AI pipeline. You can refer to this link if more information is required.
One should also consider adding a layer of reverse proxy, which can be co-located with your cluster. You will have the option of using either Nginx or Apace Knox for this. The Knox Gateway provides a single access point for all REST and HTTP interactions with Apache Hadoop clusters.
One should keep a regular monitoring of the process running on one machine. We need to have alarms in place to observe the unwanted processes & high/CPU or memory usage.
Ring 3 — Authentication
One of the most common ways to authenticate Big Data components and services is using Kerberos. This is one of the supported means of authentication for many cloud vendors. Kerberos is a network authentication protocol developed by the Massachusetts Institute of Technology (MIT). The Kerberos protocol uses secret-key cryptography to provide secure communications over a non-secure network. The primary benefits are strong encryption and single sign-on (SSO).
You can also consider integrating your cluster with an external Active Directory, or LDAP if you want to preserve your existing identities from your organization.
One of the other means of authenticating the usage of the Big Data cluster service by various cloud vendors in IAM is to provide fine-grained and service-level ACLs (access control lists).
Ring 4 — Authorization
You should control access to data and other resources and give very fine-grained access to only the very particular resources that are required.
You should review who is accessing what resource.
Apache Ranger is a framework to enable, monitor, and manage comprehensive data security across the Big Data and AI pipelines. It provides fine-grained authorization to do a specific action and/or operation with a Hadoop component or tool and is managed through a central administration tool. It provides enhanced support for different authorization methods — role-based access control, attribute-based access control, etc.
You should also consider centralizing auditing of user access and administrative actions (security-related) within all the components of the big data and AI pipeline.
Many cloud vendors also provide centralized governance, auditing, and ways to define policies to control access to resources via their Data Lake or equivalent offerings, which provide you with control and monitoring not just for a single instance of your pipeline but across different pipelines.
Many vendors have a lot of ways of alerting if there is a breach, and you can automate the actions if there is a breach or unauthorized access is attempted.
You can also use the cloud vendor’s services to build a catalog of their data assets, classify and govern these assets, and provide collaboration capabilities around these data assets for data scientists, analysts, and the data governance team.
Ring 5 — OS/Storage Security
You should consider securing your data by encrypting it. You will have a choice of either using the key provided by your vendor or many vendors supporting Bring your keys for the encryption.
If data persists in HDFS, HDFS implements transparent, end-to-endencryption. Once configured, data read from and written to special HDFS directories is transparently encrypted and decrypted without requiring changes to user application code. This encryption is also end-to-end, which means the data can only be encrypted and decrypted by the client. HDFS never stores or has access to unencrypted data or unencrypted data encryption keys.
If data persists in object storage, With the bucket encryption capability, you can use server-side encryption with customer-provided keys (SSE-C) or a custom master encryption key from KMS. Bring Your Own Key (BYOK) allows you to use your own keys as master encryption keys stored in the vault for encrypting objects in a bucket. You can also create security zones that have recipes to ensure that no public buckets are created, buckets have a customer-supplied vault key for encryption, and so on to enforce your enterprise security policies.
Continuous security pipeline
You should not be complacent that once you have all the best practices in place, you are done. Security is a continuous process of improving systems. One of your plans is a continuous pipeline, which should be followed.
- Monitor the big data and AI pipelines for potential vulnerabilities by scanning your pipelines continuously.
- Use different security tools offered by cloud vendors to scan your pipelines for any possible vulnerabilities that are capable of detecting vulnerabilities in OS packages, jars, Python packages, open ports, common attacks, etc., and have alerts in place to get notifications from these scan tools.
- Once a security issue is detected, you should also have a mitigation plan in place to take corrective action.
- You should plan to have multiple environments for your big data and AI pipelines, which can be used to apply security patches in your development to test and move them to production.
Shared Responsibility
Even though cloud vendors provide you with the best solutions and platforms, which are built to very high-security standards, you also have a very key role to play when it comes to security. Here is the link to Oracle’s shared responsibility notes.
Following are the key responsibilities that you should always keep in mind.
- Define the right policies to secure access to data.
- Do not open unwanted ports on your network.
- Use stronger encryption algorithms to protect your data.
- Do not print passwords in logs.
- Do not persist confidential information in plain text.
- Use services like Vault to persist the confidential information.
- Rotate your certificates in a timely manner.
- Patch or apply patches provided by the cloud vendor to fix the security vulnerabilities.
- Build security-related alerts and monitoring capabilities.
- Keep upgrading your components to the latest versions to adopt security enhancements.
Give it a try
If you are looking for a cloud service that provides secure, highly available big data clusters for your Big Data and AI pipelines, please try out the OCI Big Data Service. The OCI Big Data Service provisions fully configured, secure, highly available, and dedicated Hadoop and Spark clusters on demand. Scale the cluster to fit your big data and analytics workloads by using a range of Oracle Cloud Infrastructure compute shapes that support small test and development clusters to large production clusters!
This story is co-authored with my friends Vijay and Kanaka.
Please comment and give your feedback on this article in a comment below or reach out to Rachit Arora. Thank you for reading.
References
Big Data Service – link
Tutorials – link
Get Started with Oracle Big Data Service – link
Build a Data Pipeline with Big Data Service and Oracle Analytics Cloud – link
