In this post we will look at the architecture for orchestrating and scheduling OCI Data Science notebooks as part of other data pipelines in OCI Data Integration. The following diagram illustrates this architecture, it leverages the Oracle Accelerated Data Science SDK (see here) which is a python SDK for the many Data Science features, this SDK is used from a function that triggers the notebook in OCI Data Science, the REST task in OCI Data Integration executes the function and polls on the OCI Data Science job run to complete using the GetJobRun API.
Let’s see how this is actually done.
Using the Accelerated Data Science SDK
The function and supporting scripts are below (git link is https://github.com/davidallan/oci_fn_execute_notebook). You will need to download these and deploy the function to OCI.
We use OCI Functions to invoke the notebook, the func.yaml file is leveraging the Python language in functions.
|
|
The requirements.txt file depends on functions SDK and the Data Science ADS;
|
|
The python script is below, this has the notebook parameterized along with the OCI Data Science projects and other info. There are various properties parameterized for demonstration purposes, more could be done such as shape and subnet, but for a publicly available ipynb this is all that is needed;
- noteBook the Python notebook URL to use, for example you can use the sample provided here to test https://raw.githubusercontent.com/tensorflow/docs/master/site/en/tutorials/customization/basics.ipynb
- jobName provide the job name for the OCI Data Science job that will be launched
- logGroupId the log group Ocid to be used.
- projectId the OCI Data Science project Ocid – create a project to be used
- compartmentId the compartment Ocid where the job will be created
- outputFolder the output folder in OCI to write the results ie. oci://bucketName@namespace/objectFolderName
The function is based on the Python example in [https://accelerated-data-science.readthedocs.io/en/latest/user_guide/jobs/run_notebook.html#tensorflow-example] (TensorFlow example) the OCI Data Science accelerated data science documentation. Its using a small shape for demonstration, with OCI you can run notebooks and data science jobs on all kinds of shapes including GPUs!
|
|
Permissions
Example permissions to test OCI Functions and from OCI Data Integration.
Resource principal for testing from OCI Functions for example (replace with your information);
- allow any-user to manage data-science-family in compartment YOURCOMPARTMENT where ALL {request.principal.type=’fnfunc’}
- allow any-user to manage object-family in compartment YOURCOMPARTMENT where ALL {request.principal.type=’fnfunc’}
- allow any-user to manage log-groups in compartment YOURCOMPARTMENT where ALL {request.principal.type=’fnfunc’}
- allow any-user to manage log-content in compartment YOURCOMPARTMENT where ALL {request.principal.type=’fnfunc’}
Resource principal for testing from Workspaces for example (replace with your information);
- allow any-user to manage data-science-family in compartment YOURCOMPARTMENT where ALL {request.principal.type=’disworkspace’,request.principal.id=’YOURWORKSPACEID’}
- allow any-user to manage object-family in compartment YOURCOMPARTMENT where ALL {request.principal.type=’disworkspace’,request.principal.id=’YOURWORKSPACEID’}
- allow any-user to manage log-groups in compartment YOURCOMPARTMENT where ALL {request.principal.type=’disworkspace’,request.principal.id=’YOURWORKSPACEID’}
- allow any-user to manage log-content in compartment YOURCOMPARTMENT where ALL {request.principal.type=’disworkspace’,request.principal.id=’YOURWORKSPACEID’}
Function Deployment
Follow the regular function deployment pattern. I will not go through this here, there are tutorials on Functions here that are useful to go through;
[https://docs.oracle.com/en-us/iaas/Content/Functions/Tasks/functionsquickstartguidestop.htm] (OCI Functions Quickstart)
There is also a very convenient way to create functions from the OCI Console’s Cloud Editor, the function can be created directly from the git URL https://github.com/davidallan/oci_fn_execute_notebook and deployed.
Sample Execution
You should test the function from the command line first to ensure it is defined and created ok.
|
|
Orchestrating in OCI Data Integration
See the post here for creating REST tasks from a sample collection, the REST task calls the OCI function and then polls on the Data Science GetJobRun API [https://blogs.oracle.com/dataintegration/post/oci-rest-task-collection-for-oci-data-integration] (Invoking Data Science via REST Tasks)
The execution notebook can be orchestrated and scheduled from within OCI Data Integration. Use the Rest Task to execute the notebook. Here is a snippet of the Rest Task;
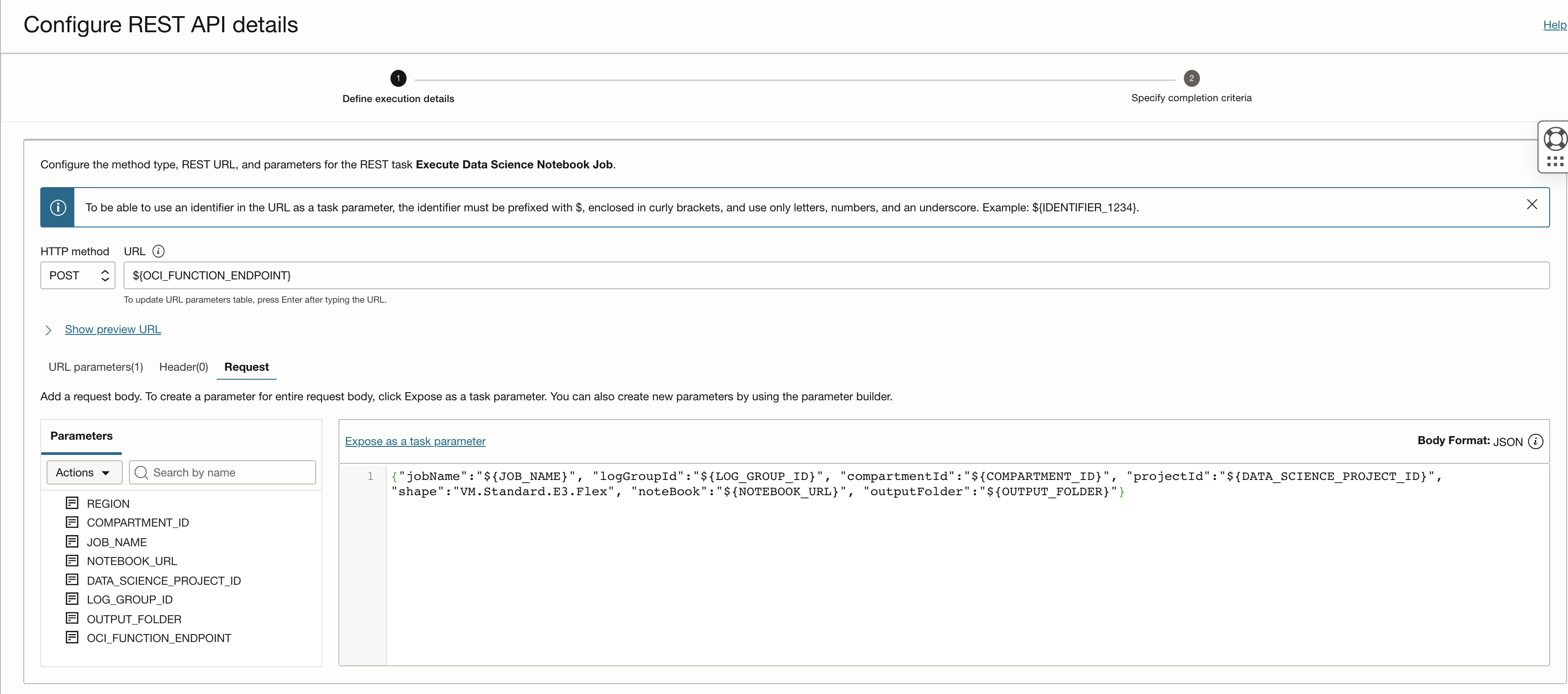
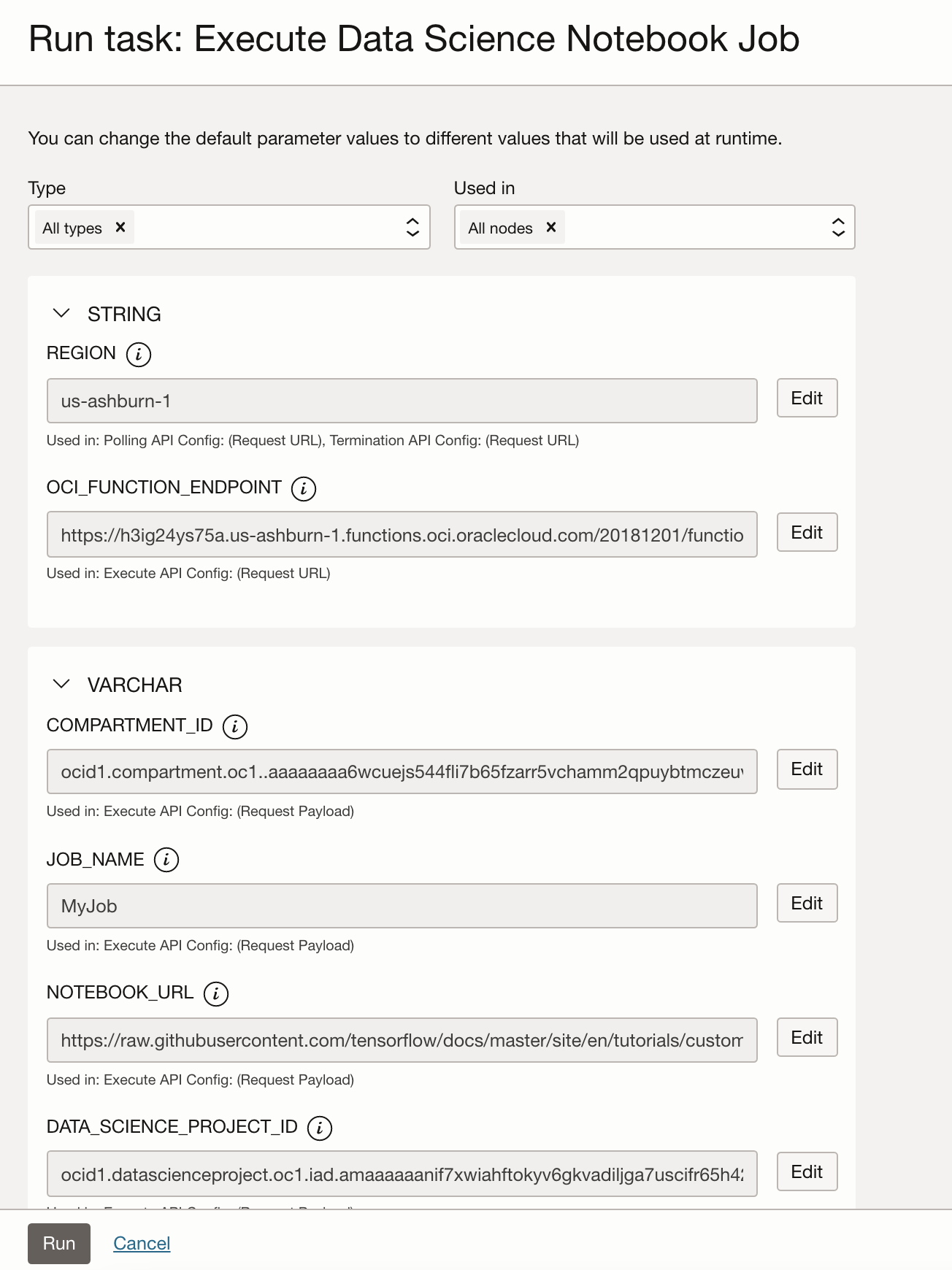
You can get this task using the postman collection from here. Below you can see the task being executed and the notebook specified along with other arguments;
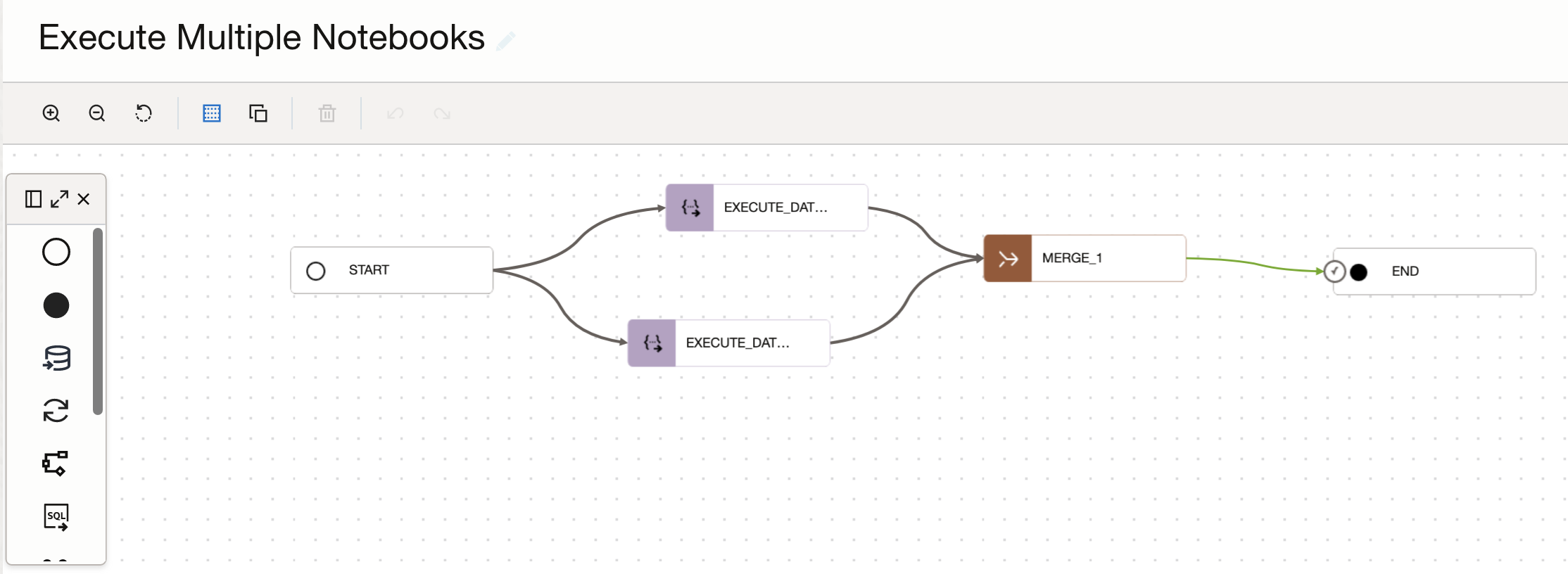
You can use this task in a data pipeline and run multiple notebooks in parallel and add in additional tasks before and after;
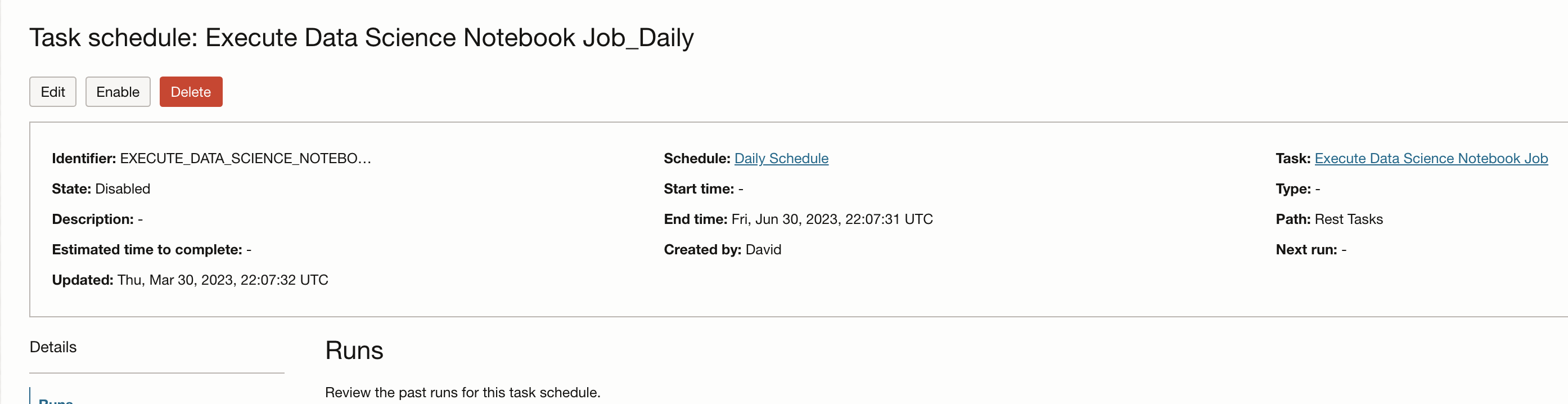
You can schedule this task to run on a recurring basis or execute this via any of the supported SDKs;
That’s a high level summary of the capabilities, see the documentation links in the conclusion for more detailed information. As you can see, we can leverage OCI functions to trigger the notebook execution and monitor from within OCI Data Integration.
Want to Know More?
For more information, review the Oracle Cloud Infrastructure Data Integration documentation, associated tutorials, and the Oracle Cloud Infrastructure Data Integration blogs.
Organizations are embarking on their next generation analytics journey with data lakes, autonomous databases, and advanced analytics with artificial intelligence and machine learning in the cloud. For this journey to succeed, they need to quickly and easily ingest, prepare, transform, and load their data into Oracle Cloud Infrastructure and schedule and orchestrate many otger types. oftasks including Data Science jobs. Oracle Cloud Infrastructure Data Integration’s Journey is just beginning! Try it out today!
