
Oracle Database 23ai
Oracle’s converged database strategy is an outcome of the impact of AI Large Language Models (LLM), exemplified by offerings such as ChatGPT, Cohere, Google Gemini and Meta LLaMA. These engines are restricted to answering questions in the specific time window of their training. They lack the correlation with the data held within the organization. These LLMs can be augmented with the organizational data along with their existing understanding to the questions we ask about the data held within the database.
With the release of Oracle Database 23ai (henceforth will be referred as 23ai), the need for having a dedicated vector database (e.g., mongo Atlas DB) is eliminated for all mission-critical enterprise workloads that supports machine learning models enabling AI vector search. These vectors are referred as embeddings, are multi-dimensional representation of documents, videos, images, natural language texts. This strategy avoids fragmentation of data across multiple systems avoiding complex pipelines and provides the ability to access data with native SQL without any need for intermediate transformations.
ONNX
Open Neural Network Exchange (ONNX) is an open format built to represent machine learning models. For instance, pre-trained transformer models from Hugging Face can be converted to ONNX format that can be imported into 23ai and enable vector searches using standard DB native PLSQL functions without the need for calling LLM APIs over HTTPS and avoiding the overhead of managing keys of ML models just for API invokes.
A new VECTOR datatype-based column can be created in tables in 23ai to store the user text or RAG-based document chunks as embeddings into the VECTOR column enabling semantic text and document searches.
In this blog, we will see how to import a pre-trained augmented LLM from Hugging Face into the Oracle 23ai DB and try creating the embeddings into a VECTOR column of a table.
Setting up 23ai for ONNX
Installing 23ai requires the following steps.
1. Create a cloud compute instance.For this article, a Linux 8 image instance was created. Standard steps of VCN creation, Subnet creation etc. were followed.
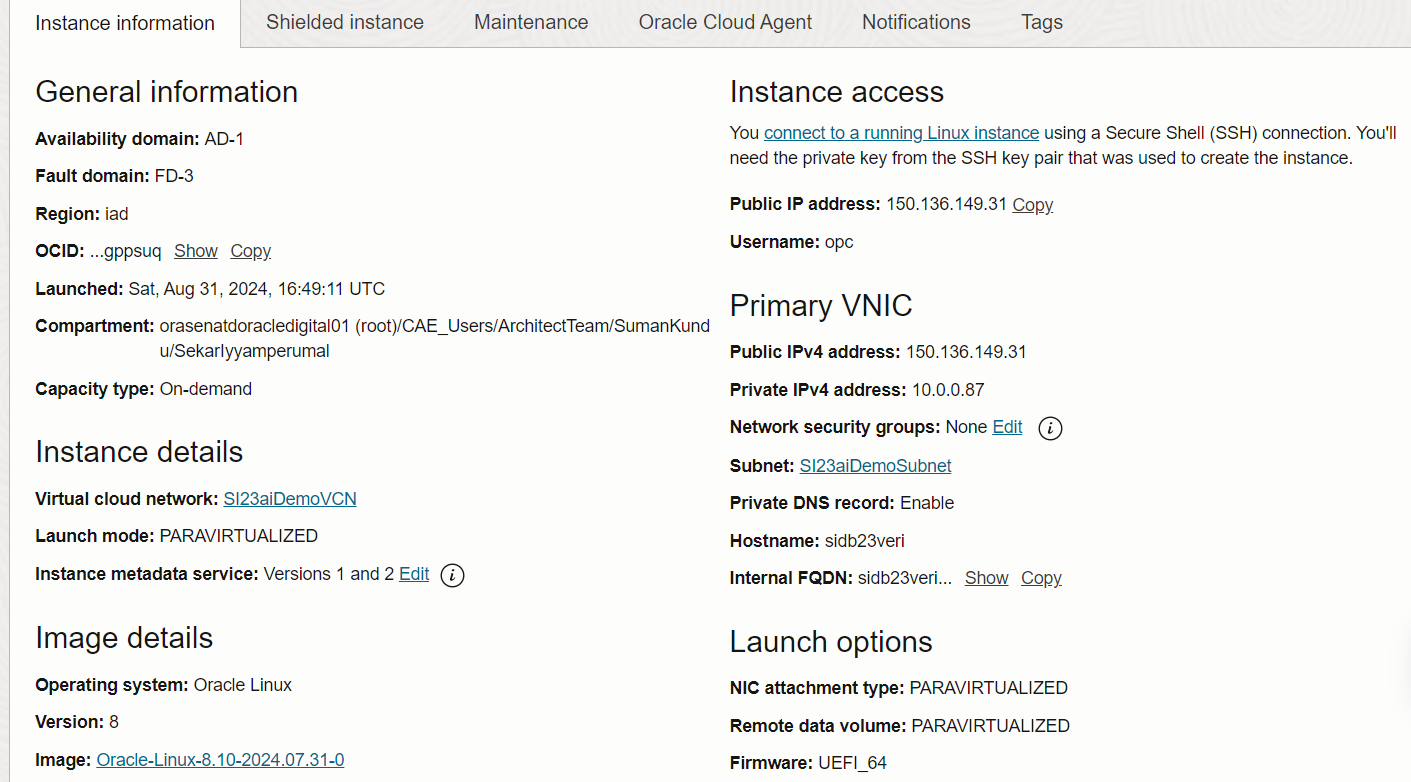
2. SSH into the created compute instance with the user’s private key. Install the 23ai version that can be downloaded from here. The actual full list of DB installation steps are not covered here and is out of scope for this blog.
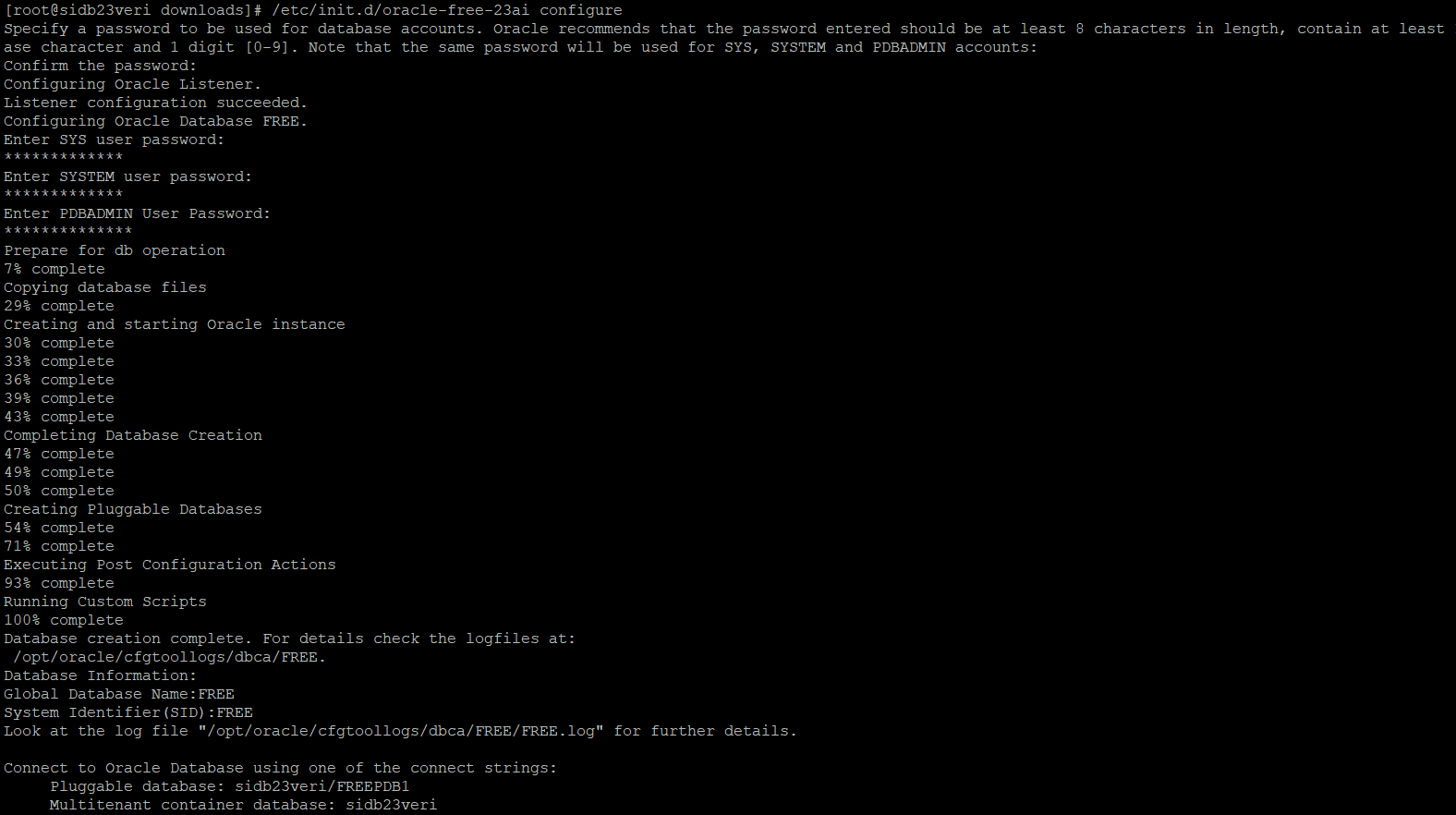
3. After successful installation, below message is displayed.

4. Database configuration and SYS password. Note down the SYS user password for future login.
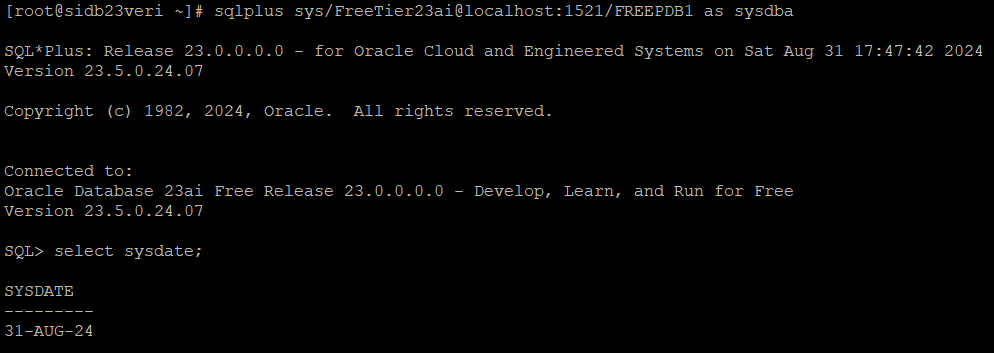
5. Connect to SQLPLUS as SYS user and verify.
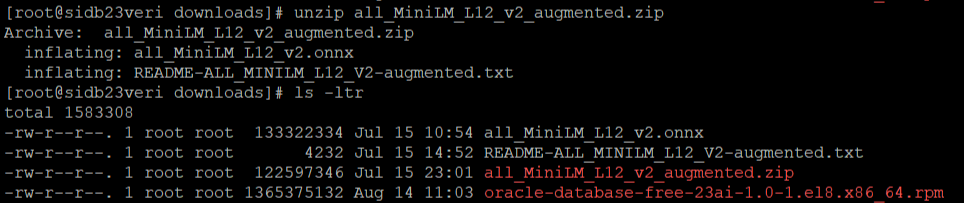
6. Switch to the ‘/root/downloads’ path. Note, ‘downloads’ is the folder I created under /root to download the 23ai installation package.
7. Download the Hugging Face sentence transformer model ‘all-MiniLM-L12_v2’ from here. A quick note on ‘all-MiniLM-L6-v2’ – It maps sentences & paragraphs to a 384-dimensional dense vector space and can be used for tasks like clustering or semantic search.
8. Now download the LLM ZIP format file.

9. Unzip the file in the same location. Note, a file with ONNX extension present in the path.
10. Login to SQLPLUS as SYSDBA
11. Apply grants and define the data dump directory as the path where the ONNX model was unzipped. In this example, OMLUSER is the schema.
12. Login to the OMLUSER schema and load the ONNX model. Optionally drop the model first if a model with the same name already exists in the database.

13. Validate that the model was imported to the database.

14. Generate embedding vectors using the VECTOR_EMBEDDING SQL scoring function. Partial output is shown below.

15. We can connect to the installed 23ai instance using SQL developer desktop client by creating a SSH connection with the public and private IP address of the compute instance.


16. A demo table ‘MY_TABLE’ is created with a column name ‘VEC_EMBEDDINGS’ of VECTOR data type.
17. Insert statement to insert a new record for a sample text along with its vector embeddings.

18. Verifying inserted data. Partial embeddings are shown here. When expanded, all 386 vector embeddings will be visible.

The vector embedded data can be extracted and integrated via OCI-DI as part of the ELT job load process or as ORDS REST APIs. One another way to access this data will be through out-of-the-box ADW Adapter connections in Oracle Integration Cloud.
Likewise, any ONNX compatible models can be imported into 23ai to enable vector creation and search.
Related References:
Overview of Oracle AI Vector Search
Open Neural Network Exchange Specification
https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
