Here you’ll see how with some small surgical extensions we can use ODI to generate complex integration models in Hive for modelling all kinds of challenges;
- integrate data from Cassandra, or any arbitrary SerDe
- use Hive Parquet or ORC storage formats
- create partitioned, clustered tables
- define arbitrarily complex attributes on tables
I’m very interested in hearing what you think of this, and what is needed/useful over and above (RKMs etc)
When you use this technique to generate your models you can benefit from one of ODI’s lesser known but very powerful features – the Common Format Designer (see here for nice write up). With this capability you can build models from other models, generate the DDL and generate the mappings or interfaces to integrate the data from the source model to the target. This gets VERY interesting in the Big Data space since many customers want to get up and running with data they already know and love.
What do you need to get there? The following basic pieces;
- a Hive custom create table action here.
- flex fields for external table indicator, table data format, attribute type metadata get groovy script here
Pretty simple right? If you take the simple example on the Confluence wiki;
- CREATE TABLE parquet_test (
- id INT,
- str STRING,
- mp MAP<STRING,STRING>,
- lst ARRAY<STRING>,
- strct STRUCT<A:STRING,B:STRING>)
- PARTITIONED BY (part STRING)
- STORED AS PARQUET;
…and think about how to model this in ODI, you’ll think – how do I define the Parquet storage? How can the complex types be defined? That’s where the flex fields come in, you can define any of the custom storage properties you wish in the datastore’s Data Format flex field, then define the complex type formats.
In ODI the Parquet table above can be defined with the Hive datatypes as below, we don’t capture the complex fields within attributes mp, 1st or stct. The partitioned column ‘part’ is added in to the regular list of datastore attributes (like Oracle, unlike Hive DDL today);
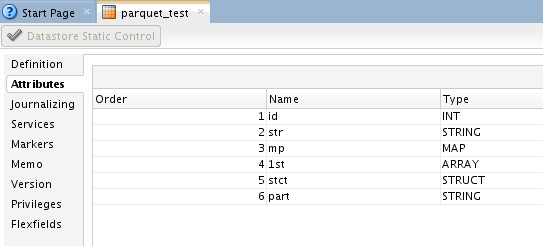
Using the flex field Data Format we can specify the STORED AS PARQUET info, the table is not external to Hive so we do not specify EXTERNAL in the external data field;
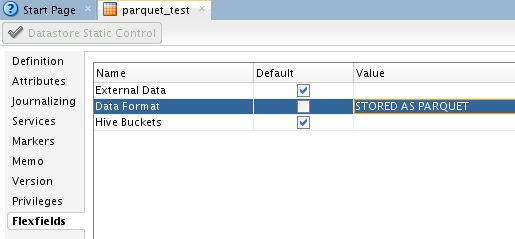
This value can have lots of ODI goodies in it which makes it very versatile – you can use variables, these will be resolved when the generated procedure containing the DDL is executed, plus you can use <% style code substitution.
The partitioning information is defined for the part attribute, the ‘Used for Partitioning’ field is checked below;
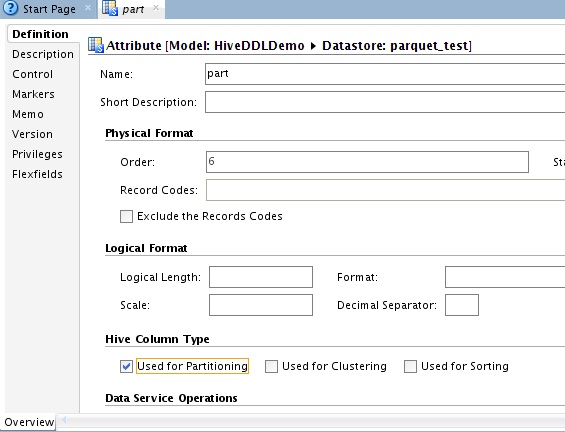
Let’s take stock, we have our table defined as Parquet and we have the partitioning info defined. Now we have to define the complex types. This is done on attributes mp, 1st and stct using the creatively named Metadata field – below I have fully defined the MAP, STRUCT and ARRAY for the respective attributes;

Note the struct example escapes the : as the code is executed via the JDBC driver when executing via the agent and ‘:’ is the way of binding information to a statement execution (you can see the generated DDL further below with the ‘:’ escaped).
With that we are complete, we can now generate DDL for our model;

This brings up a dialog with options for where to store the procedure with the generated DDL – this has actually done a base compare against the Hive system and allowed me to selected which datastores to create DDL for or which DDL to create, I have checked the parquet_test datastore;

Upon completion, we can see the procedure which was created. We can chose to further edit and customize this if so desired. We can schedule it anytime we want or execute.
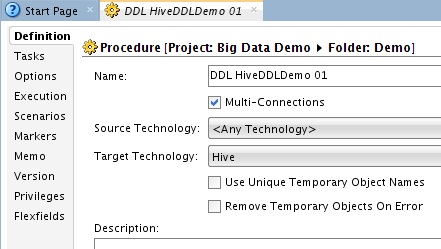
Inspecting the Create Hive Table action, the DDL looks exactly as we were after when we first started – the datastore schema / name will be resolved upon execution using ODI’s runtime context – which raised another interesting point! We could have used some ODI substitution code <% when defining the storage format for example;
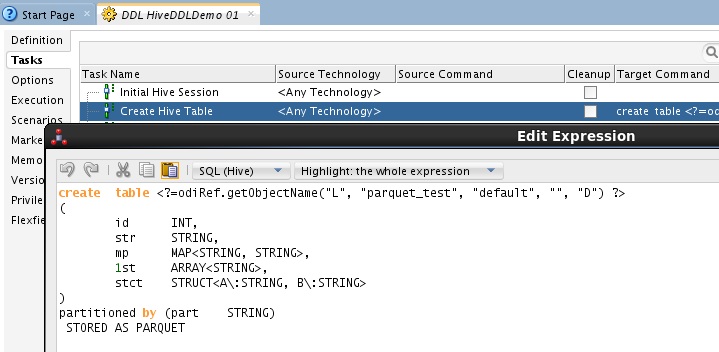
As I mentioned earlier you can take this approach to capture all sorts of table definitions for integrating. If you want to look on the inside of how this is done, check the content of the Hive action in image below (I linked the code of the action above), it should look very familiar if you have seen any KM code and uses the flex fields to inject the relevant information in the DDL;
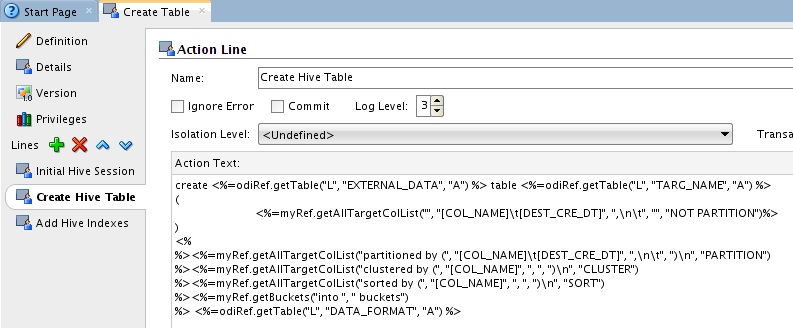
This is a great example of what you can do with ODI and how to leverage it to work efficiently.
There is a lot more that can be illustrated here including what the RKM Hive can do or be modified to do. Perhaps creating the datastore and complex type information from JSON, JSON schema, AVRO schema or Parquet is very useful? I’d be very interested to hear your comments and thoughts. So let me know….
