“I don’t know what’s in my data lake!” By now, this occurrence has become an age-old problem. Data lakes provide an excellent way to store data at large scale. The volume and variety of data in a data lake can provide a trove of information for your analytics needs. But it’s easy to drown in data if you don’t know what’s in the lake. For that, you need a simple way to find the data and understand it before your data lake turns into a data swamp.
The problem: Too many files that aren’t different
Data in a data lake can come from different sources, such as IoT devices, service logs, transactional systems, or telemetry data. You can get data from different geographies at different frequencies, which are then hopefully neatly stored in many files. It’s fine to organize files and optimize storage and collate them at a single place, but for analyzing, some files need to appear as part of a single partitioned table. Typically, these files have the same schema or structure. They follow a specific file naming convention, and that’s how readers of these files know they represent a single data set.
A data catalog that’s collecting technical information from your data lake can give you details of all your files in an object store. But they’re all treated as independent entities, even though they belong together.
Don’t know what a data catalog is? Check out What is a Data Catalog and What is Oracle Cloud Infrastructure Data Catalog.
The solution: Logical entities
It seems obvious that the data catalog should also represent all these files as a single logical entity. With logical entities, the catalog is organized more efficiently, avoiding an explosion of redundant metadata corresponding to each file. Data consumers can get a clearer idea of the large volume of data aided by this logical grouping. They can use metadata of a logical entity as a basis to create an external table, allowing data analysts or applications to work directly with data in the data lake.
Logical entities in Oracle Cloud Infrastructure Data Catalog
In the latest release of Oracle Cloud Infrastructure (OCI) Data Catalog, we’ve introduced two new constructs that make it easy to harvest related files at scale from Oracle Object Storage. The new constructs are filename patterns and logical entities. Expert users like data catalog admins and data providers can define filename patterns by which to group files. During metadata harvesting, Data Catalog matches the file names with the file name patterns to derive logical entities. Logical entities resulting from the patterns provide a logical representation of data across a set of matching files.
A logical entity behaves like any other data entity in Data Catalog. You can view the summary of its metadata, enrich the metadata by linking it to glossary terms, or create customer properties to provide a business context to them. You can search and discover logical entities like you would any other data entity and you can also filter based on the specific data entity type logical.
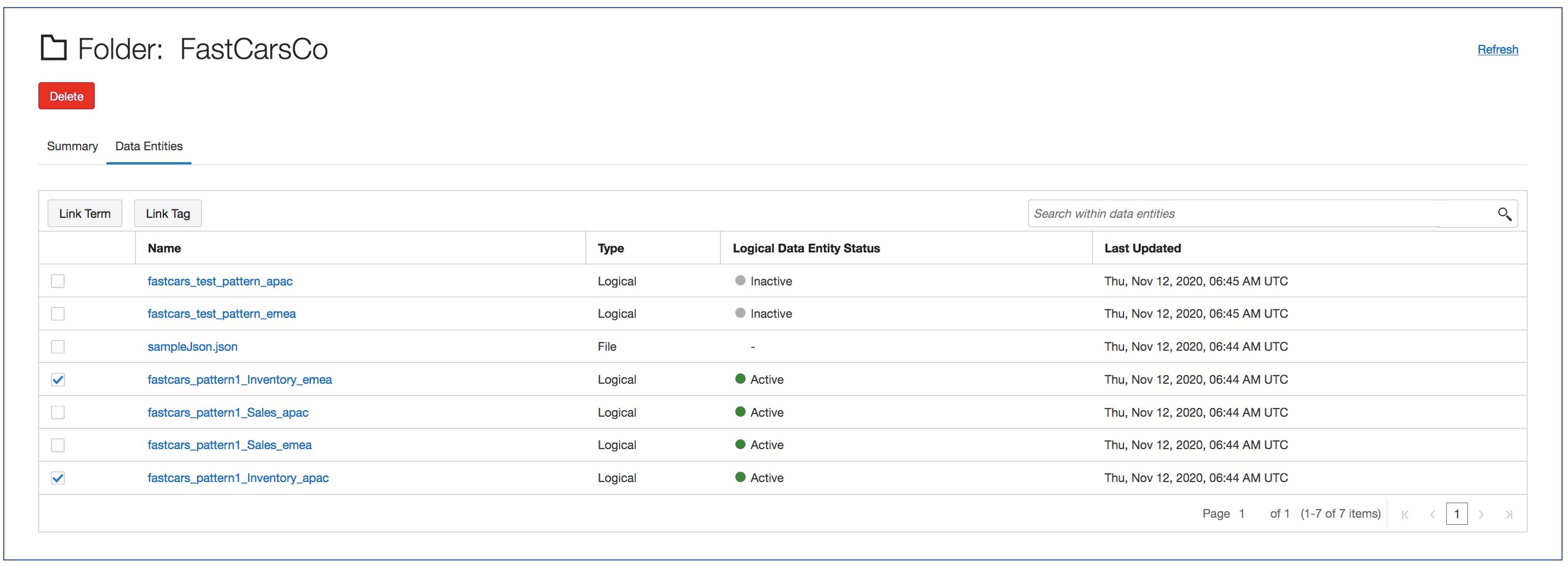
Figure 1. List of data entities in a bucket, includes regular entities and logical entities
How do you go about creating the logical entities in Data Catalog?
How to create logical entities in Data Catalog
Creating logical entities is a multi-step process and uses the following steps:
- Create file name patterns.
- Assign file name patterns to the data asset for an Oracle Object Storage.
- Harvest the data asset.
- Inspect and browse details of the logical entities and enrich them.
An expert user familiar with files in the object store bucket should create the file name patterns to match the names of files in the buckets.
File name pattern
What is a file name pattern? This new object type in Data Catalog consists of a name, description, and the most important part, a Java style regular expression. This expression is used to define the patterns of file names based on which files in a bucket are grouped into a single logical entity. Creating file name patterns is the most important step in the process. A typical pattern expression looks like the following string:
{bucketName:myBucketName}/[0-9]*_[a-z]*_{logicalEntity:[a-z]*}_[0-9a-zA-Z]*.json
Use the following rules to define the pattern expression:
- The expression consists of the following constant string qualifiers:
- bucketName: This qualifier is mandatory. It identifies name of the bucket where the files reside.
- logicalEntity: This qualifier is used with part of the file name to derive the name of the logical entity. We recommend this optional qualifier for better naming of the resulting logical entities.
- The expression can be composed of one or more occurrences of the following regex:
- [0-9] to represent numbers
- [a-z] and [A-Z] to represent alphabets
- . (dot) to represent any character, alphanumeric, and otherwise
- Use an * (asterisk) after the previous options to indicate more than one occurrence of the regex.
The name of the resulting logical entity is derived from the file name pattern. Ideally, it’s a combination of the pattern name and logicalEntity fragment in the expression. If you don’t specify the logicalEntity qualifier, the pattern name itself is used to form the name of the logical entity.
Let’s take a use case to understand expressions better. Consider an enterprise that sends telemetry data from applications running in different data centers to a central data lake. This data is partitioned based on the business units. Because it’s telemetry data, it’s chronological, so a timestamp is associated with each file being sent. All partitioning factors are represented in the following filename path:
FastCarsCo/Inventory/20200101_apac_basic_telemetry.json
FastCarsCo/Inventory/20200201_apac_basic_telemetry.json
FastCarsCo/Inventory/20200101_emea_basic_telemetry.json
FastCarsCo/Inventory/20200201_emea_basic_telemetry.json
FastCarsCo/Sales/20200430_apac_adv_telemetry.json
FastCarsCo/Sales/20200531_apac_adv_telemetry.json
FastCarsCo/Sales/20200630_emea_adv_telemetry.json
FastCarsCo/Sales/20200731_emea_adv_telemetry.json
The file names follow a pattern that varies in some key aspects of business unit and region. If we want to group them in a logical entity based on business unit and region, we use the following expression and get the following logical entities:
Pattern1:
{bucketName:FastCarsCo}/{logicalEntity:[A-Za-z]*}/[0-9]*_{logicalEntity:[a-z]*}_.*_telemetry.json
Logical entities:
Pattern1_FastCarsCo_Inventory_apac
Pattern1_FastCarsCo_Inventory_emea
Pattern1_FastCarsCo_Sales_apac
Pattern1_FastCarsCo_Sales_emea
If we want to group the files based on only the region but combine all business units together under the same logical entity, we use the following expression:
Pattern2:
{bucketName:FastCarsCo}/ [A-Za-z]*/[0-9]*_{logicalEntity:[a-z]*}_.*_telemetry.json
Logical entities:
Pattern2_FastCarsCo_ apac
Pattern2_FastCarsCo_ emea
You can use an ‘OR’ operator (a pipe symbol |) to specify a list of constant strings within the logiclaEntity fragment to help group files containing these constant strings. You can also specify a meaningful alias to collectively refer to this group of strings. The format to use is {logicalEntity:<alias_name>:<list of OR separated strings>}. In the example below the constant strings ‘Inventory’ and ‘Sales’ are OR-ed and the alias ‘alldepartments’ is used to refer to them in the resulting logical entities.
Pattern3:
{bucketName:FastCarsCo}/{logicalEntity:alldepartments:Inventory|Sales}/[0-9]*_{logicalEntity:[a-z]*}_.*_telemetry.json
Logical entities:
Pattern3_FastCarsCo_alldepartments_apac
Pattern3_FastCarsCo_alldepartments_emea
To create filename patterns, you can click Manage Filename Patterns in the Quick Actions panel on the Oracle Cloud Data Catalog home page.
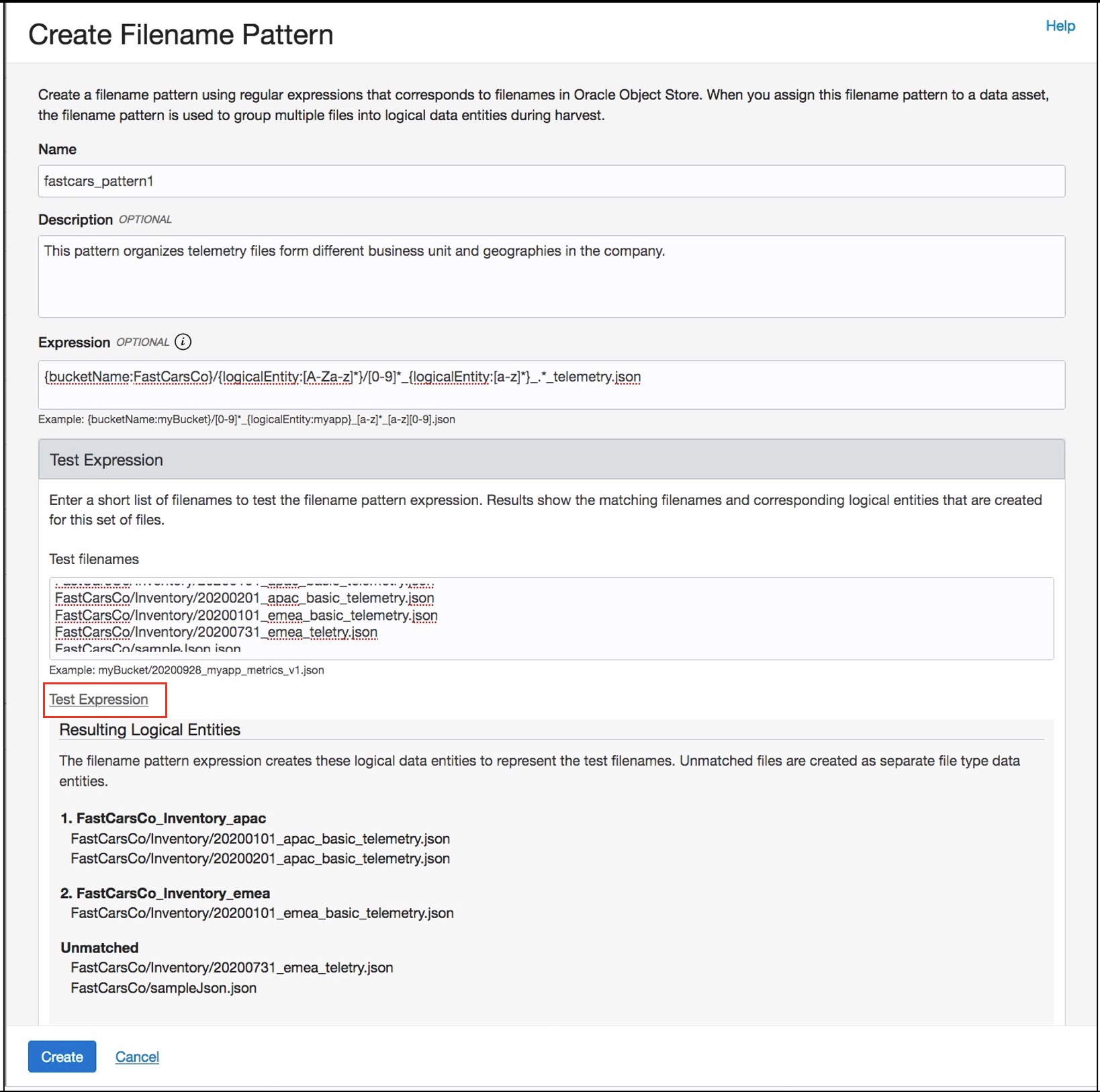
Figure 2. Create file name pattern.
While creating a pattern, you can test the pattern expression against a sample set of file names and decide if the logical entities shown in the result are what you expected. If not, you can tweak the expression and test again. Any files that don’t match the pattern expression show up as Unmatched and are not part of any logical entity. The unmatched files are harvested as independent and regular data entities in the catalog. When you’ve arrived at the right expression that results in the right grouping of files, you can click Create.
You can create any number of patterns you need. You can define multiple patterns based on files in the bucket and how you want to organize them. Based on the patterns you choose to use during harvesting, the same file can be part of multiple logical entities.
Logical entities
After you’ve created all the required patterns, you can assign them to the Oracle Object Storage data asset. The assignment of patterns implies that on subsequent harvests all files matching a pattern expression belong to a derived logical entity. Other than assignment of pattern to the data asset, no additional steps are required before harvesting. The Data Catalog harvester process assumes that all the files within the same logical entity have the same structure, so it picks one file from the matched set of files to obtain the file format and its metadata.
Logical entities show up in the same list in the Entities tab of the harvested data asset, along with other regular data entities.
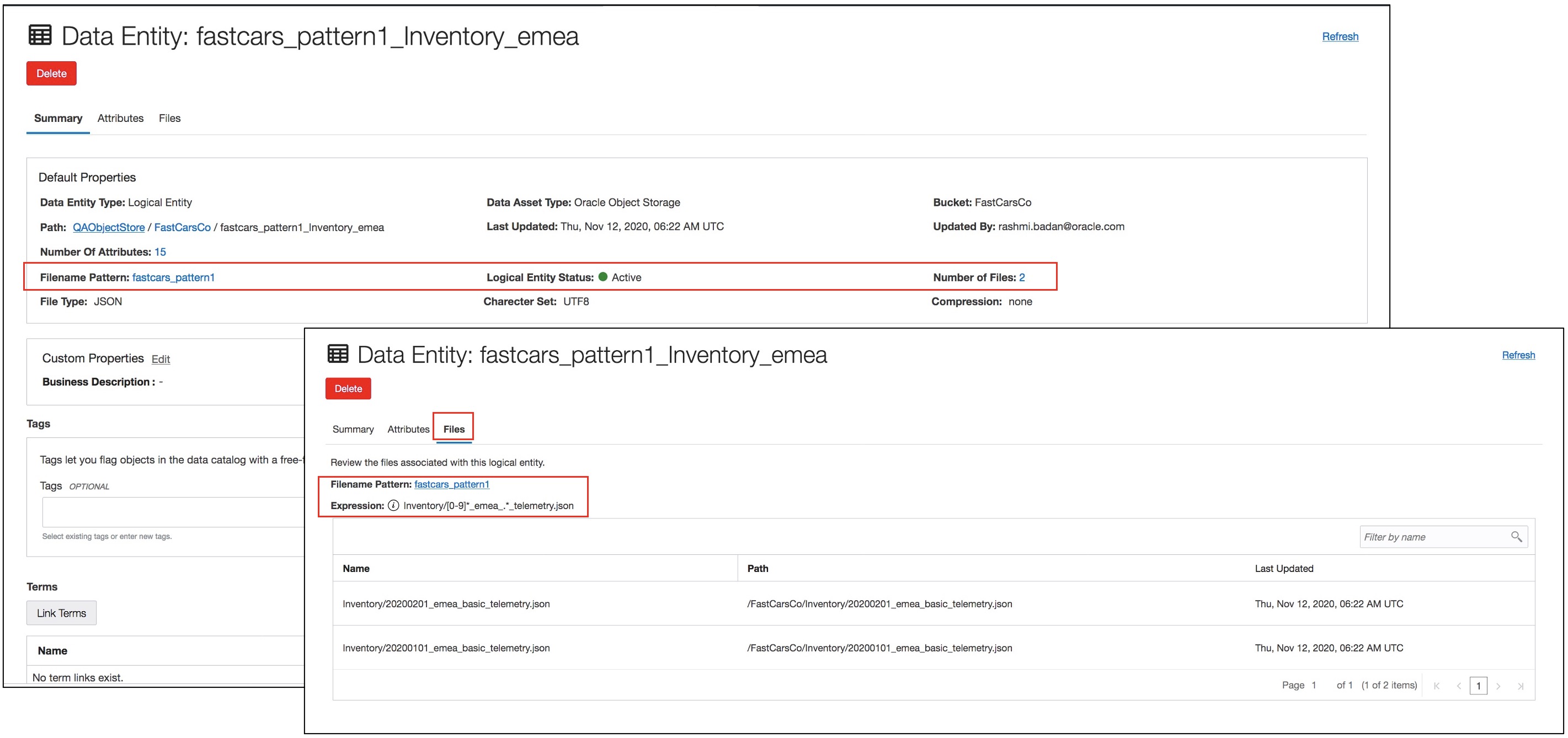
Figure 3. Details of a logical entity
A logical entity’s details page gives you more information than the default properties. You can see the pattern used to derive this logical entity, the number of physical files it contains, file type, and some other details, such as encoding and compression. You can see the list of all files that are part of the logical entity in the Files tab. The expression in the Files tab is a realized expression, which is a normalized form of the file name pattern expression for this particular logical entity.
Lifecycle of a logical entity
Figure 1 shows most logical entities in an active state and two inactive. What does that mean? Logical entities are tightly coupled to file name patterns because they’re derived based on the pattern expressions. A logical entity is in active state when it’s harvested. But it can become inactive because of the following reasons:
- You modify the expression in an assigned file name pattern responsible for the logical entity. The state changes to inactive because the expression might no longer match the names of files in the logical entity.
- You unassign a pattern from the data asset.
You can undo the changes and reharvest to restore the inactive logical entities to an active state. But if the expression is changed or a different pattern is assigned to the data asset, new logical entities are created only after a reharvest.
The catalog instance retains all inactive logical entities until you delete them manually. Incremental harvest involving logical entities is possible only when the patterns remain assigned and unmodified across the harvests.
Conclusion
Oracle Cloud Infrastructure (OCI) Data Catalog helps you better understand data in data lakes, specifically in Oracle Object Storage, with the help of logical entities. You can harvest many related files faster than before, search and explore similar files without having to go through each of them and organize metadata for data lakes more efficiently. Other services can use logically grouping related files to derive a single table from those files for upstream analytics applications to work with.
Check out some of our other blogs:
- What Is Oracle Cloud Infrastructure Data Catalog?
- Better Collaboration Using Improved Metadata Curation, Search, and Discovery for Data Lakes with Oracle Cloud Infrastructure Data Catalog’s New Release
- Enrich Metadata with Oracle Cloud Infrastructure Data Catalog
- Harvest Metadata from On-Premise and Cloud Sources with a Data Catalog
