Back in January Anuj posted an article here on using Oracle NoSQL via the Oracle database Big Data SQL feature. In this post, I guess you could call it part 2 of Anuj’s I will follow up with how the Oracle external table is configured and how it all hangs together with manual code and via ODI. For this I used the Big Data Lite VM and also the newly released Oracle Data Integrator Big Data option. The BDA Lite VM 4.1 release uses version 3.2.5 of Oracle NoSQL – from this release I used the new declarative DDL for Oracle NoSQL to project the shape from NoSQL with some help from Anuj.
My goal for the integration design is to show a logical design in ODI and how KMs are used to realize the implementation and leverage Oracle Big Data SQL – this integration design supports predicate pushdown so I actually minimize data moved from my NoSQL store on Hadoop and the Oracle database – think speed and scalability! My NoSQL store contains user movie recommendations. I want to join this with reference data in Oracle which includes the customer information, movie and genre information and store in a summary table.
Here is the code to create and load the recommendation data in NoSQL – this would normally be computed by another piece of application logic in a real world scenario;
- export KVHOME=/u01/nosql/kv-3.2.5
- cd /u01/nosql/scripts
- ./admin.sh
- connect store -name kvstore
- EXEC “CREATE TABLE recommendation( \
- custid INTEGER, \
- sno INTEGER, \
- genreid INTEGER,\
- movieid INTEGER,\
- PRIMARY KEY (SHARD(custid), sno, genreid, movieid))”
- PUT TABLE -name RECOMMENDATION -file /home/oracle/movie/moviework/bigdatasql/nosqldb/user_movie.json
The Manual Approach
This example is using the new data definition language in NoSQL. To make this accessible via Hive, users can create Hive external tables that use the NoSQL Storage Handler provided by Oracle. If this were manually coded in Hive, we could define the table as follows;
- CREATE EXTERNAL TABLE IF NOT EXISTS recommendation(
- custid INT,
- sno INT,
- genreId INT,
- movieId INT)
- STORED BY ‘oracle.kv.hadoop.hive.table.TableStorageHandler’
- TBLPROPERTIES ( “oracle.kv.kvstore”=”kvstore”,
- “oracle.kv.hosts”=”localhost:5000”,
- “oracle.kv.hadoop.hosts”=”localhost”,
- “oracle.kv.tableName”=”recommendation”);
At this point we have made NoSQL accessible to many components in the Hadoop stack – pretty much every component in the hadoop ecosystem can leverage the HCatalog entries defined be they Hive, Pig, Spark and so on. We are looking at Oracle Big Data SQL tho, so let’s see how that is achieved. We must define an external table that uses either the SerDe or a Hive table, below you can see how the table has been defined in Oracle;
- CREATE TABLE recommendation(
- custid NUMBER,
- sno NUMBER,
- genreid NUMBER,
- movieid NUMBER
- )
- ORGANIZATION EXTERNAL
- (
- TYPE ORACLE_HIVE
- DEFAULT DIRECTORY DEFAULT_DIR
- ACCESS PARAMETERS (
- com.oracle.bigdata.tablename=default.recommendation
- )
- ) ;
Now we are ready to write SQL! Really!? Well let’s see, below we can see the type of query we can do to join the NoSQL data with our Oracle reference data;
- SELECT m.title, g.name, c.first_name
- FROM recommendation r, movie m, genre g, customer c
- WHERE r.movieid=m.movie_id and r.genreid=g.genre_id and r.custid=c.cust_id and r.custid=1255601 and r.sno=1
- ORDER by r.sno, r.genreid;
Great, we can now access the data from Oracle – we benefit from the scalability of the solution and minimal data movement! Let’s make it better, let’s make it more maintainable, flexibility to future changes and also accessible by more people by showing how it is done in ODI.
Oracle Data Integrator Approach
The data in NoSQL has a shape, we can capture that shape in ODI just as it is defined in NoSQL. We can then design mappings that manipulate the shape and load into whatever target we like. The SQL we saw above is represented in a logical mapping as below;
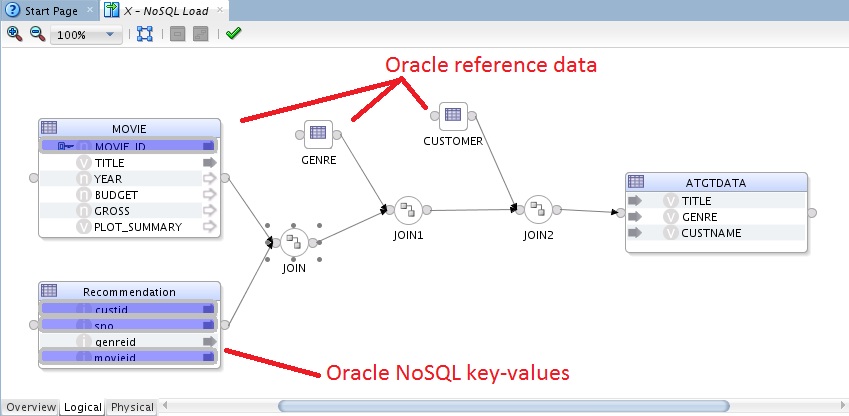
Users can use the same design experience as other data items and benefit from the mapping designer. They can join, map, transform just as normal. The ODI designer allows you to separate how you physically want this to happen from the logical semantics – this is all about giving you flexibility to change and adapt to new integration technologies and patterns.
In the physical design we can assign Knowledge Modules that take the responsibility of building the integration objects that we previously manually coded above. These KMs are generic so support all shapes and sizes of data items. Below you can see how the LKM is assigned for accessing Hive from Oracle;
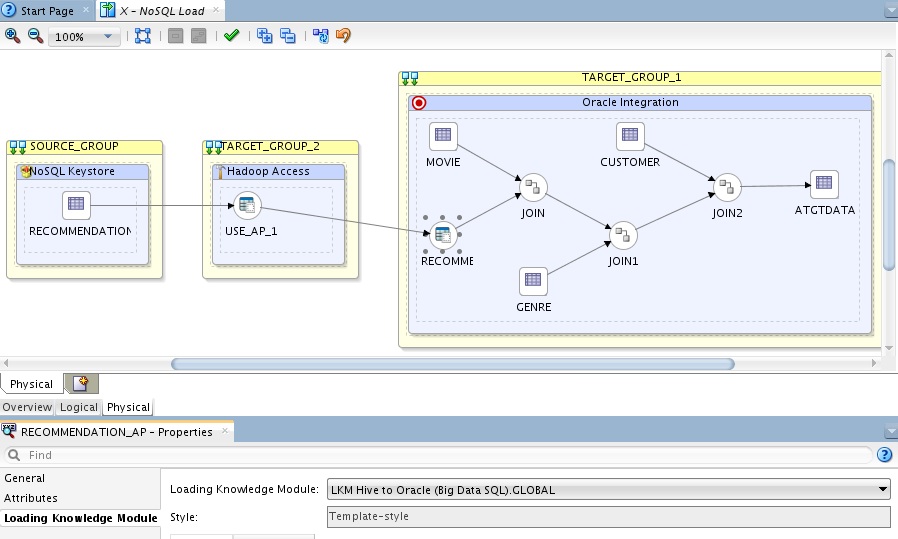
This KM takes the role of building the external table – you can take this use it, customize it and the logical design stays the same. Why is that important? Integration recipes CHANGE as we learn more and developers build newer and better mechanisms to integrate.
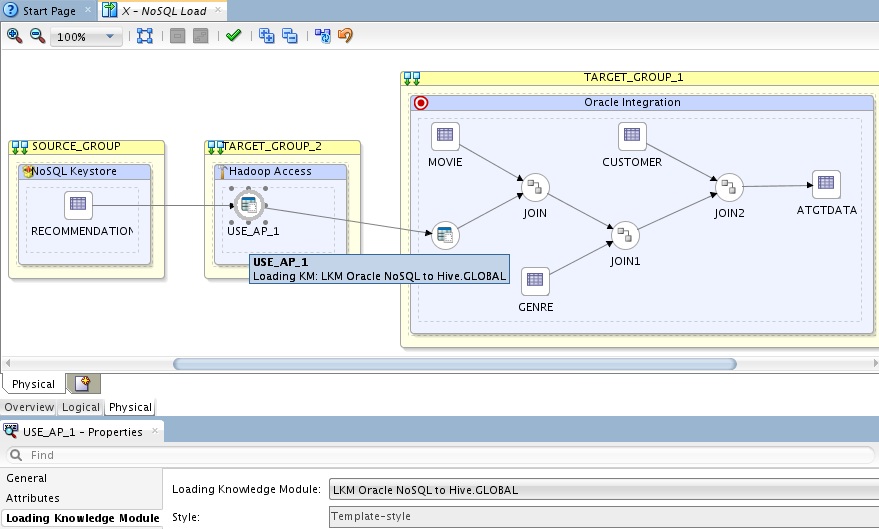
This KM takes care of creating the external table in Hive that access our NoSQL system. You could also have manually built the external table and imported this into ODI and used that as a source for the mapping, I want to show how the raw items can be integrated as the more metadata we have and you use to design the greater the flexibility in the future. The LKM Oracle NoSQL to Hive uses regular KM APIs to build the access object, here is a snippet from the KM;
- create table <%=odiRef.getObjectName(“L”, odiRef.getTableName(“COLL_SHORT_NAME”), “W”)%>
- <%=odiRef.getColList(“(“, “[COL_NAME] [DEST_CRE_DT]”, “, “, “)”, “”)%>
- STORED BY ‘oracle.kv.hadoop.hive.table.TableStorageHandler’
- TBLPROPERTIES ( “oracle.kv.kvstore”=”<%=odiRef.getInfo(“SRC_SCHEMA”)%>”,
- “oracle.kv.hosts”=”<%=odiRef.getInfo(“SRC_DSERV_NAME”)%>”,
- “oracle.kv.hadoop.hosts”=”localhost”,
- “oracle.kv.tableName”=”<%=odiRef.getSrcTablesList(“”, “[TABLE_NAME]”, “, “, “”)%>”);
You can see the templatized code versus literals, this still needs some work as you can see, can you spot some hard-wiring that needs fixed? 😉 This was using the 12.1.3.0.1 Big Data option of ODI so integration with Hive is much improved and it leverages the DataDirect driver which is also a big improvement. In this post I created a new technology for Oracle NoSQL in ODI, you can do this too for anything you want, I will post this technology on java.net and more so that as a community we can learn and share.
Summary
Here we have seen how we can make seemingly complex integration tasks quite simple and leverage the best of data integration technologies today and importantly in the future!
