The Oracle Cloud Infrastructure Streaming service provides a fully managed, scalable, and durable solution for ingesting and consuming high-volume data streams in real-time.
In this article, I will show how to configure OCI GoldenGate to run an initial load followed by a CDC replication.
As you can see in the below topology diagram, source is Oracle DB and target is OCI Streaming.
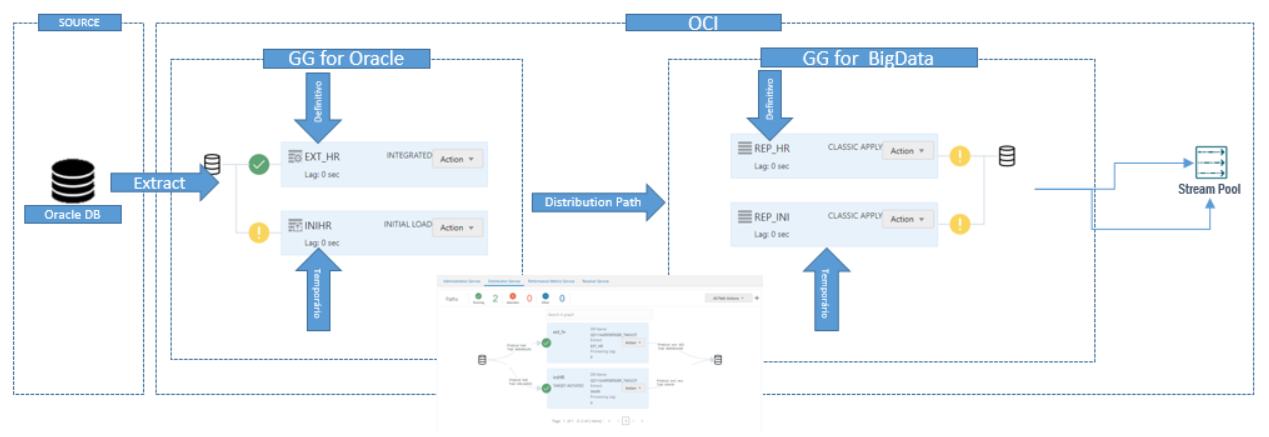
The steps that we need to follow are:
- Configure credentials in source and target OCI Goldengate deployments
- Create one CDC Extract (EXT_HR in our case)
- Create and run an Initial Load Extract (INIHR in our case)
- From OCI GoldenGate Big Data Deployment, setup a Receiver service reading INIHR trail file
- From OCI GoldenGate Oracle Deployment, setup one Distribution Serivce sending the EXT_HR trail to OCI GoldenGate Big Data Deployment
- In OCI GoldenGate Big Data Deployment, configure a replicat reading the EXT_HR; but, don’t start it yet!
- In OCI GoldenGate Big Data Deplyment, configure a Replicat reading INIHR trail
- In OCI GoldenGate Big Data Deployment, start the EXT_HR Replicat using ATCSN parameter
Connections
The Connections in OCI GoldenGate hold the connection string, username and password of Sources and targets, for this scenario you need at least two connections: One pointing to the source Oracle Database and other for target OCI Streaming.
If you are using private deployments, you must create a third connection with GoldenGate connection type. To create a GoldenGate connection, select Enter Golden Gate information and provide the endpoint (deployment URL), port (443) and the private IP. After that, assign the GoldenGate connection to both source (Oracle) and target (Big Data) OCI GoldenGate deployments
Create a Goldengate Connection pointing to OCI Goldengate Big Data deployment and assign to OCI GoldenGate for Oracle deployment.
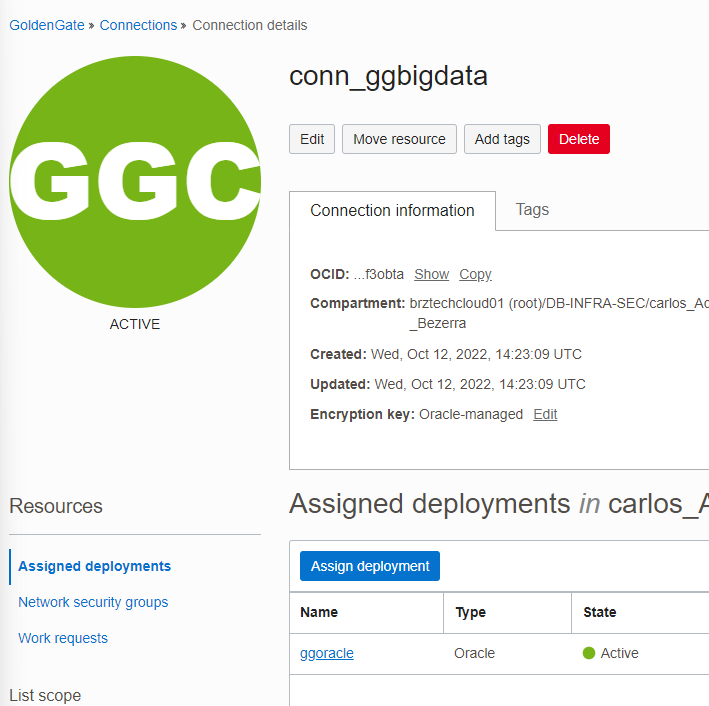
Do the same for OCI Goldengate for Oracle deployment but assign to OCI Goldengate Bigdata deployment.
Streaming Service connection
In this case, I’m using a private Stream Pool to receive my messages, to connect to it, publish and consume messages you must have a user with stream-push and stream-pull use permissions and if you want to OCI GoldenGate to create Streams automatically(by default, each table becomes a Stream), will be good to have stream-pools manage permission.

We will authenticate against the Stream Pool, so go to Analytics & AI -> Messaging Streaming and create a Private Stream Pool, choose one network that you OCI GoldenGate Big Data deployment have access:
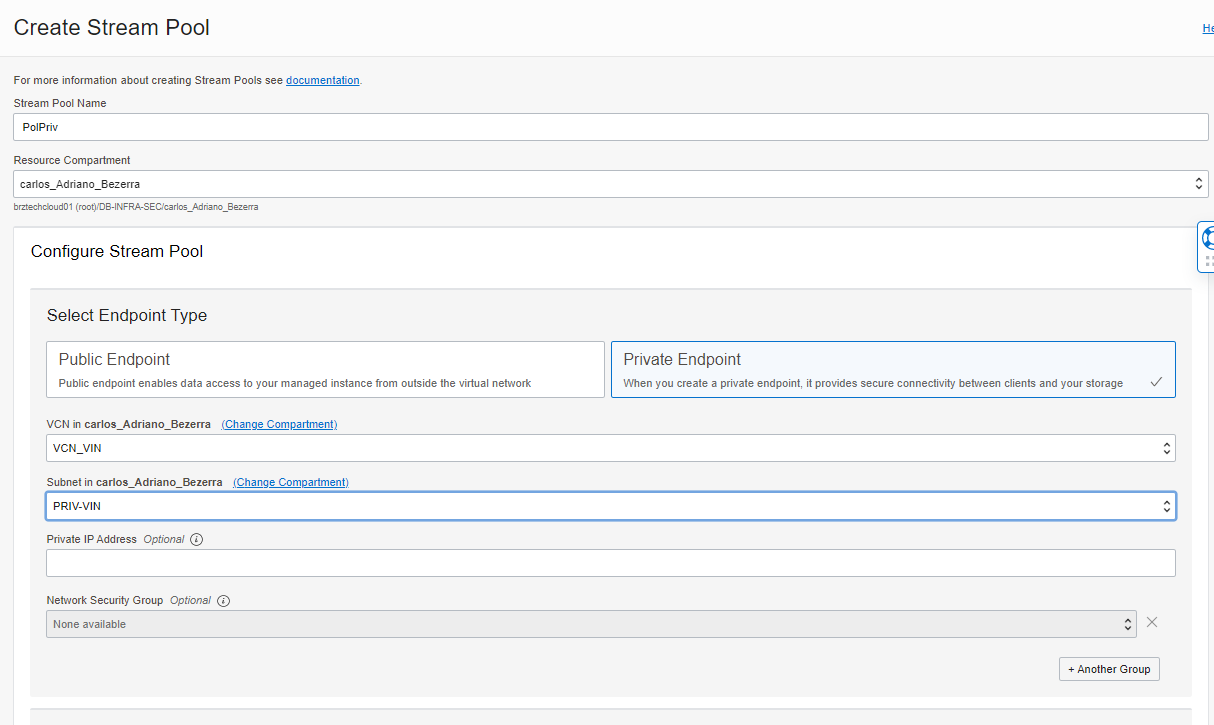
After the creation of the Stream Pool, you can get the connection parameters at Kafka Connection Settings in Stream Pool page:
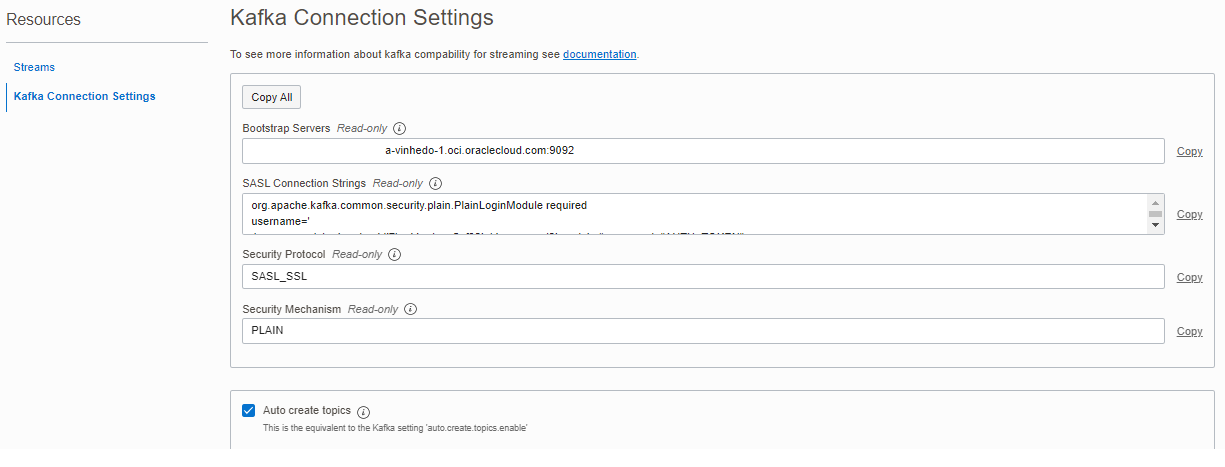
One tip here: Mark the Auto Create Topics options, so in this case OCI GoldenGate will create a new topic for new extracted tables.
In this screen you need to take note of BootStrap Server and username in SASL Connection Strings, as you can see, this user have a specific format:
Tenancy/identityProvider/username/ocid_of_stream_pool
And for password you will need an AUTH_TOKEN, this can be generated at OCI user details page:
This token is shown only once, so take care of this information.
Credentials
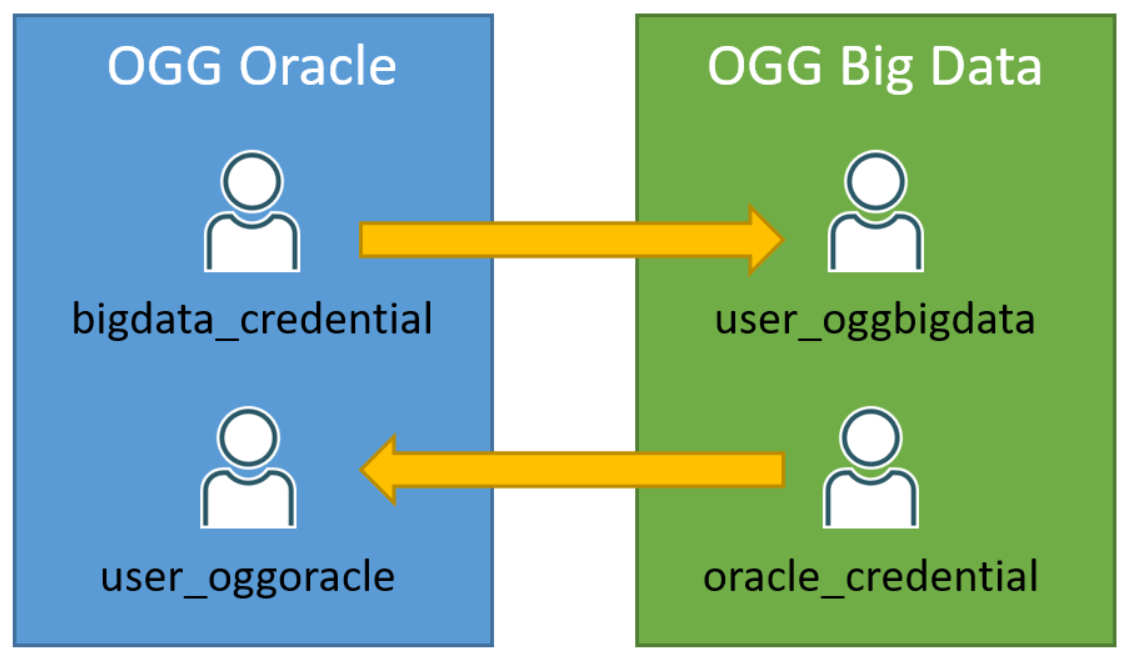
In target OCI GoldenGate Big Data deployment, go to Administration Service -> Administrator -> Users and create a user with at Operator Role and take note of username and password.
After that, in source OCI GoldenGate Oracle deployment, go to Administration Service -> Configuration -> Credentials and add a credential with the username and password noted from the previous step.
Repeat the process in the opposite order: Create a user in OCI GoldenGate Oracle deployment and credential in OCI GoldenGate Big Data deployment.
Extract, Distributions and Replicat
After creating connections and credentials, you have to create a CDC extract in OCI GoldenGate Oracle deployment and start it. A sample CDC extract parameter would look like this:
EXTRACT ext_hr
USERIDALIAS atp_vcp DOMAIN OracleGoldenGate
EXTTRAIL definitivo/hr
TRANLOGOPTIONS SOURCE_OS_TIMEZONE GMT-3
TABLE TNK_SRC.*;
In short:
- USERIDALIAS references the credentials of the source Oracle Database
- EXTTRAIL: Is used to specify the directory and trail file name (directory/trail), use the first part of parameter to organize the trails.
- SOURCE_OS_TIMEZINE: You have to use this parameter when the source database timezone is different of Extract timezone.
- TABLE: Specify what Goldengate will extract, in this case I’m extracting all tables of TNK_SRC schema.
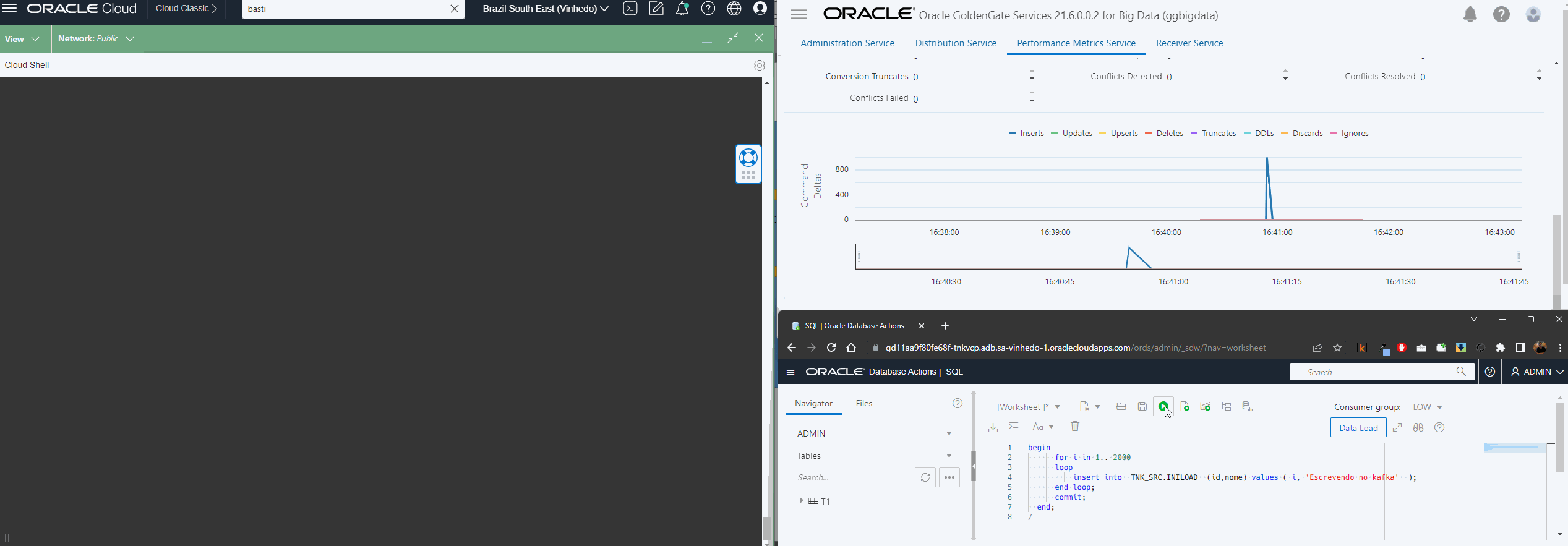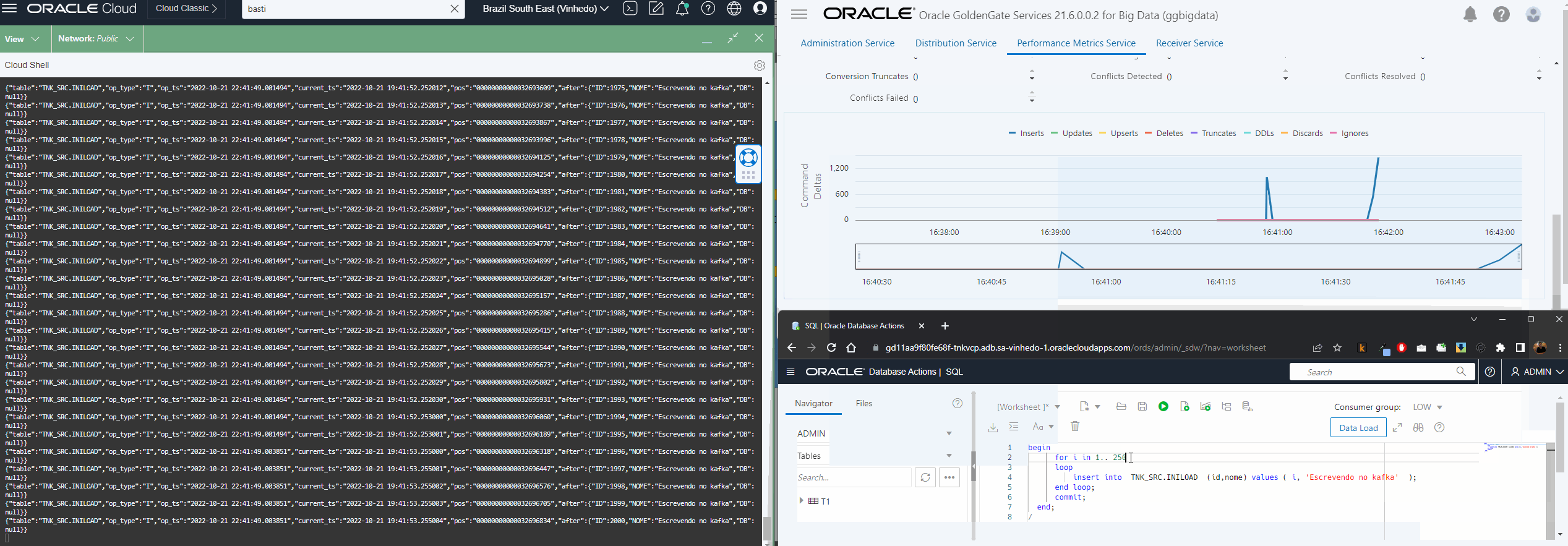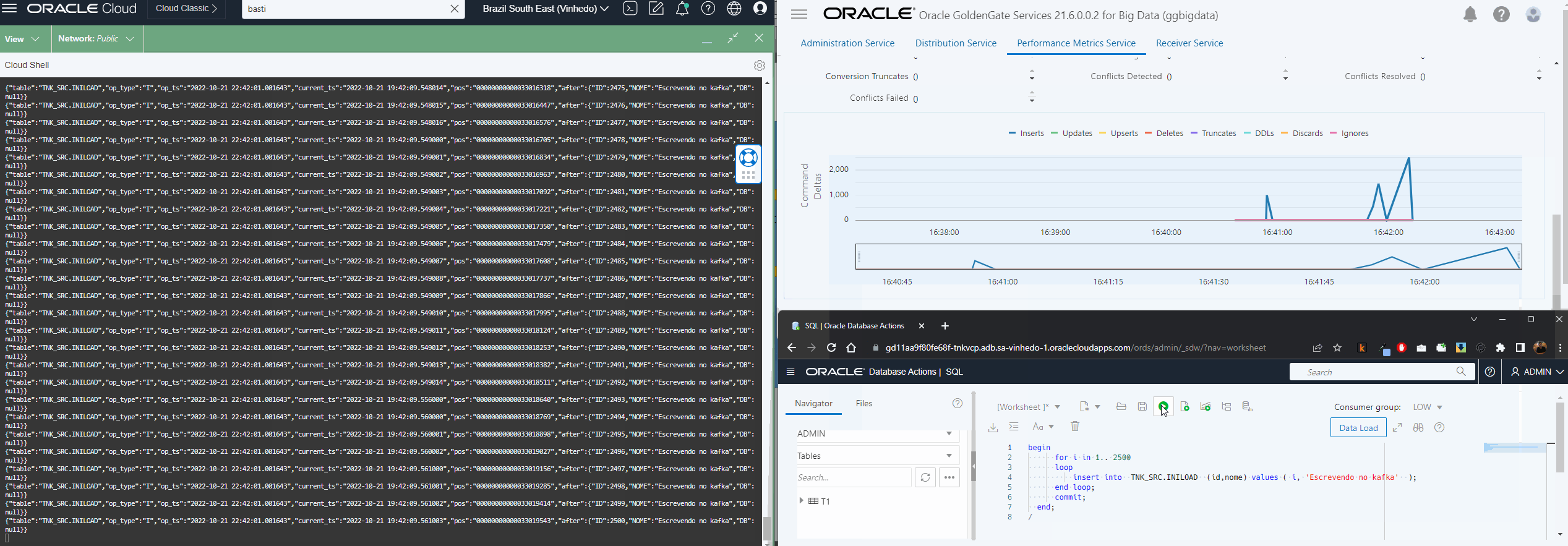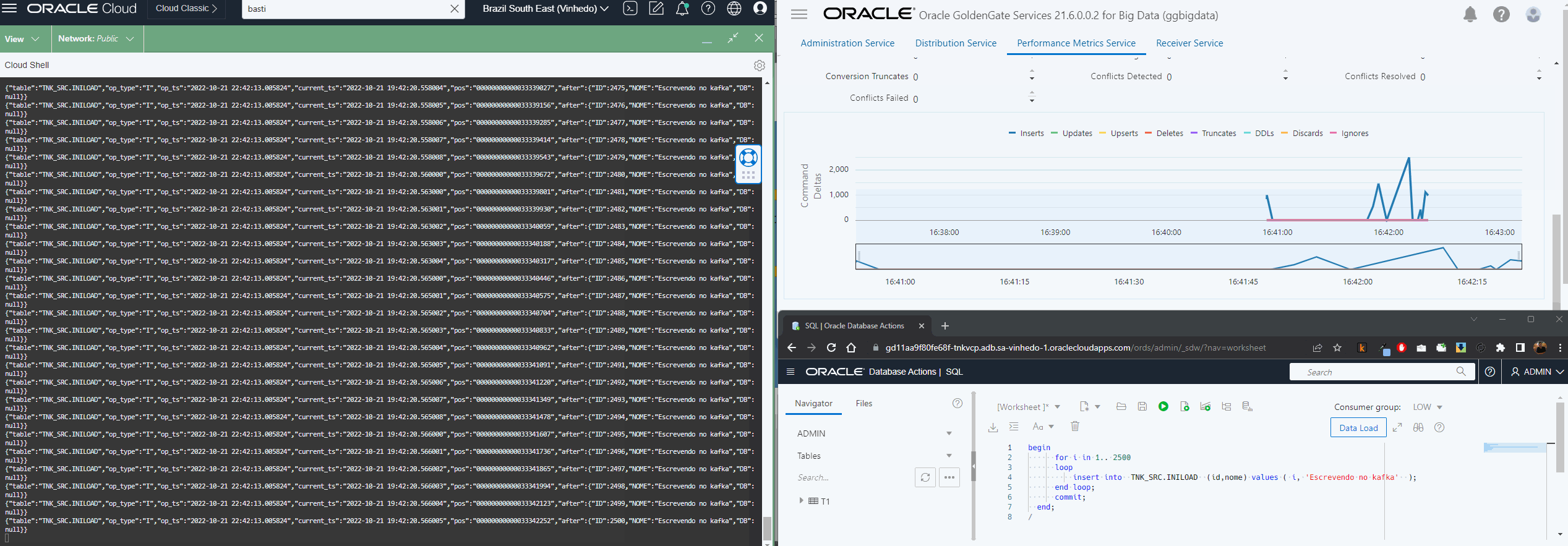
After creating the CDC extract, create an Initial Load Extract, in initial load extract, you need to pass the SQLPREDICATE parameter with a SCN captured after the first CDC Extract (EXT_HR) has started, the SQLPREDICATE parameter tells to OCI Goldengate to capture transactions in this specific SCN.
EXTRACT iniHR
USERIDALIAS atp_vcp DOMAIN OracleGoldenGate
extfile initLoad3/ii megabytes 2000 purge
TABLE TNK_SRC.*, SQLPREDICATE ‘AS OF SCN 39083101740223’;
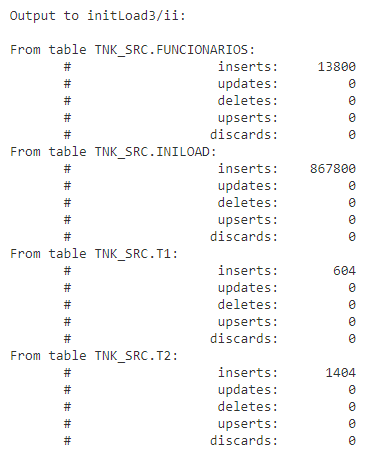
Initial Load Extracts rans only once and stop when completed, you can monitor the status/progress in Extract -> Details -> Report
Or using APIs:
curl -u oggadmin:"password" \ -H "Content-Type: application/json" \ -H "Accept: application/json" \ -H 'cache-control: no-cache' \ -X GET https://endpoint.oci.oraclecloud.com/services/adminsrvr/v2/extracts/YOUREXTRACT/info/reports/YOUREXTRACT.rpt | jq -r
After the initial load extract is completed, we can go to OCI Goldengate Bigdata Deployment and setup a Receiver Path to get trail file from source deployment and the previously created credential (in this case oracle_credential), point the Intial Load trail file and create a new target trail.
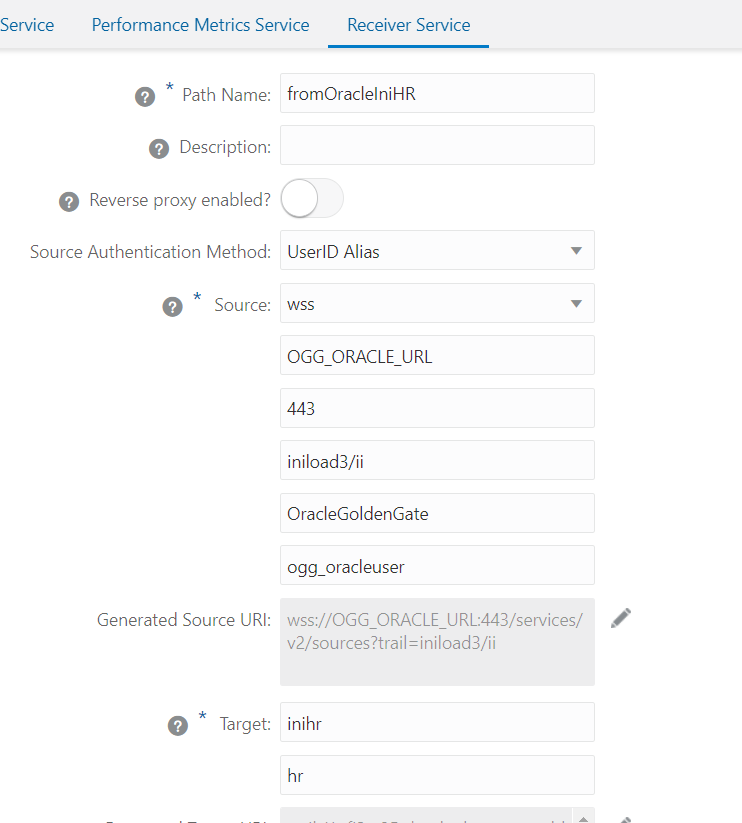
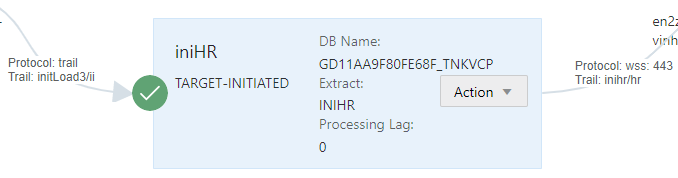
If everything is right, you will see something the receiver path status in green:
Now, create a Distribution path from source OCI GoldenGate Oracle deployment to OCI GoldenGate Big Data deployment to send the trail file created EXT_HR (CDC extract). The procedure is like the previous one but you need to select the extract and input the target information, one important thing here is to use the trail from the CDC extract.
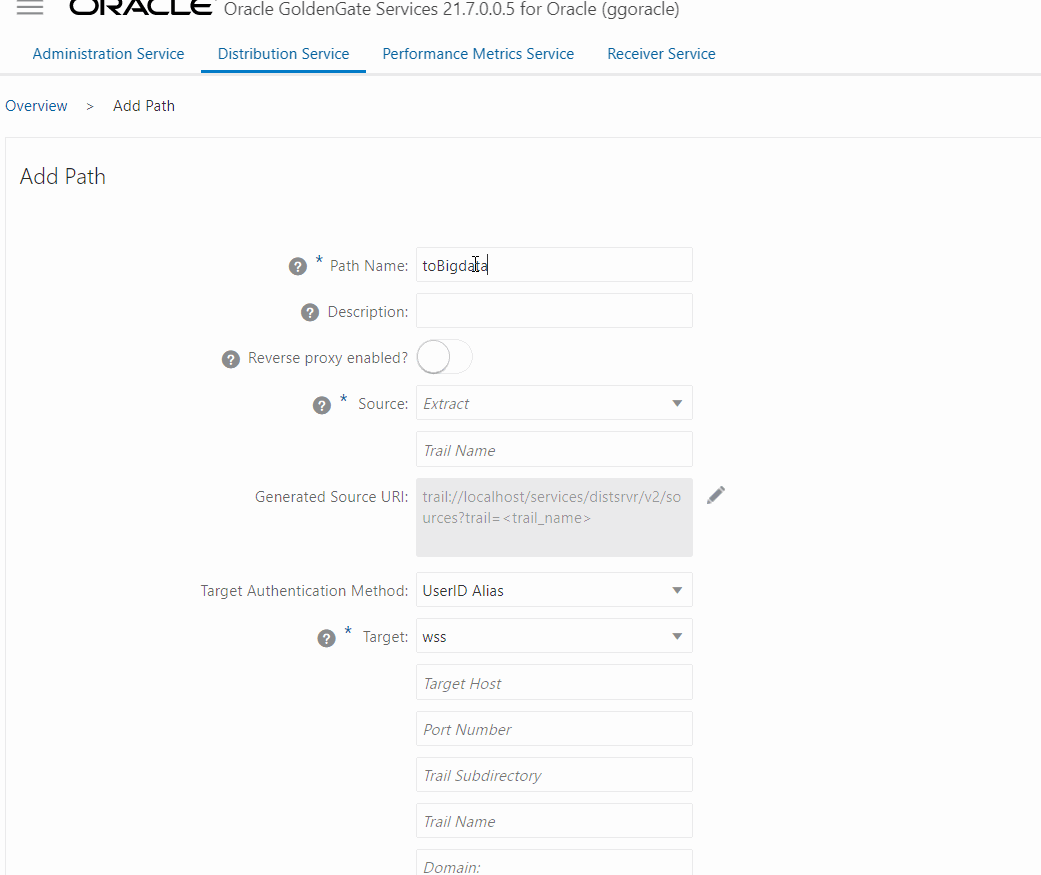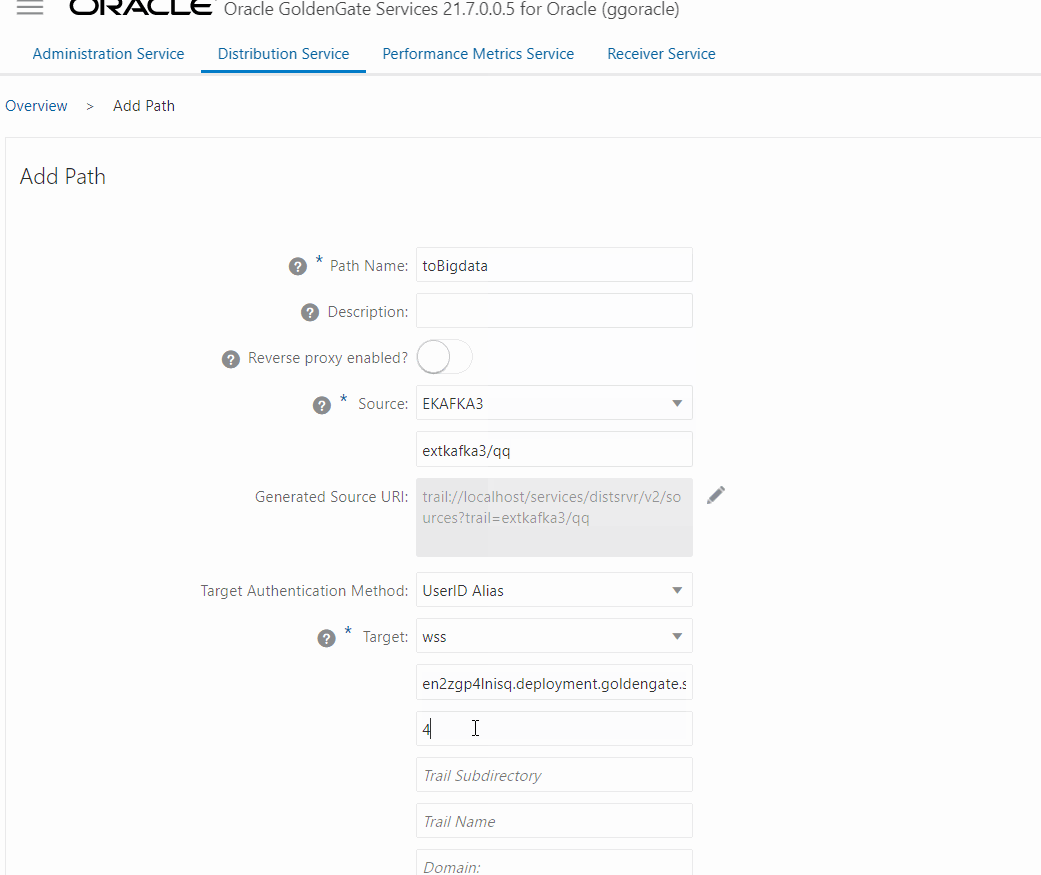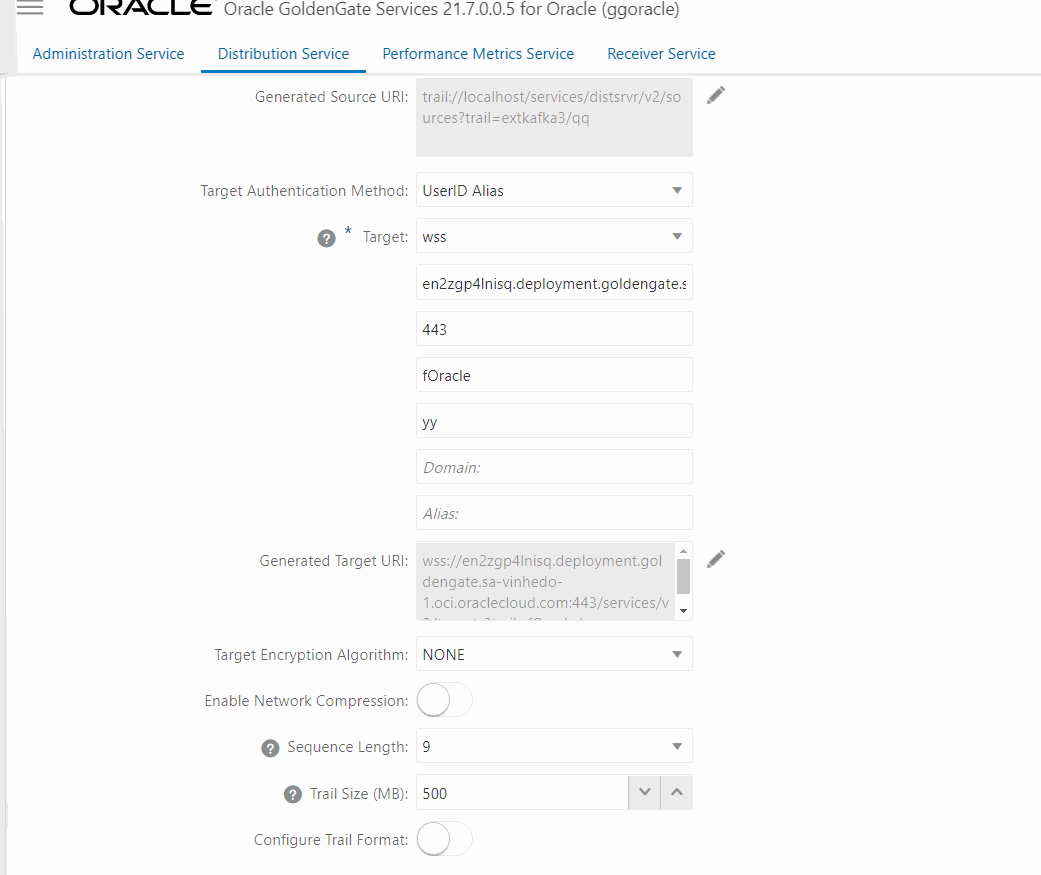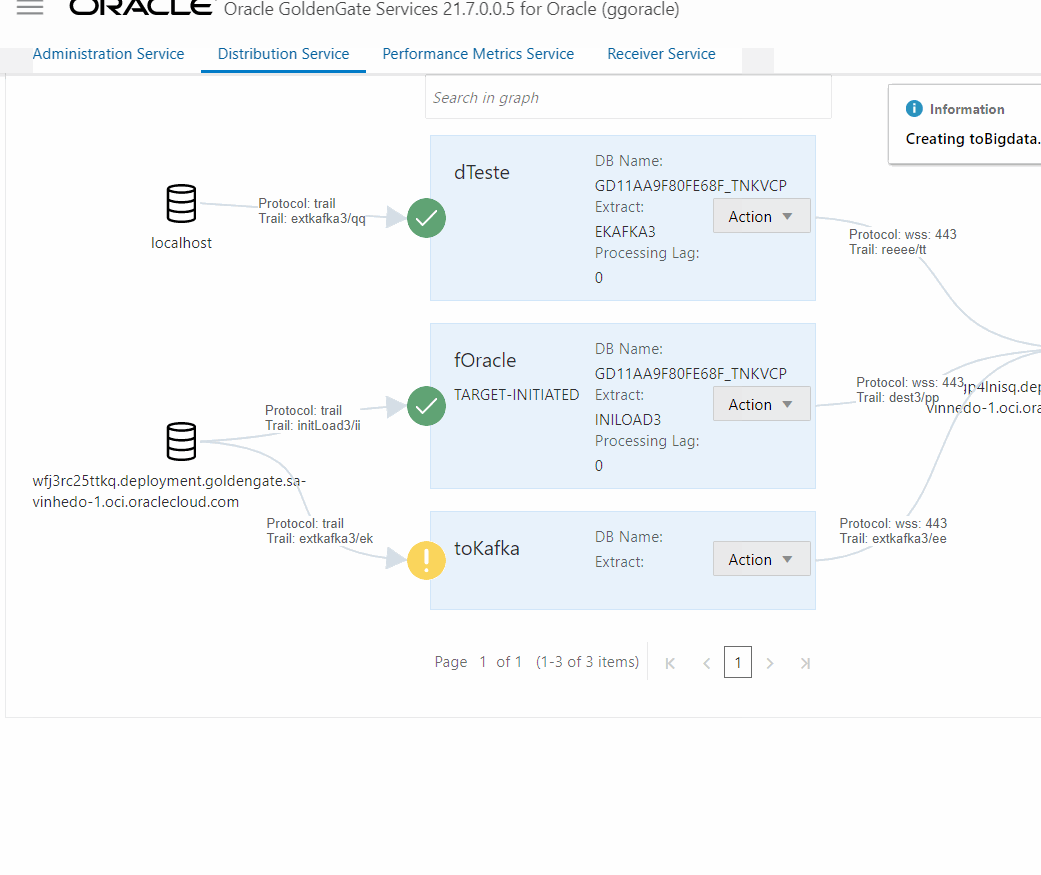
Now that we have all trails in Big DataOCI GoldenGate Big Data deployment, we can configure the replicats, first we will create a replicat for the Initial Load trail file with OSS as a target targeting OCI Streaming.
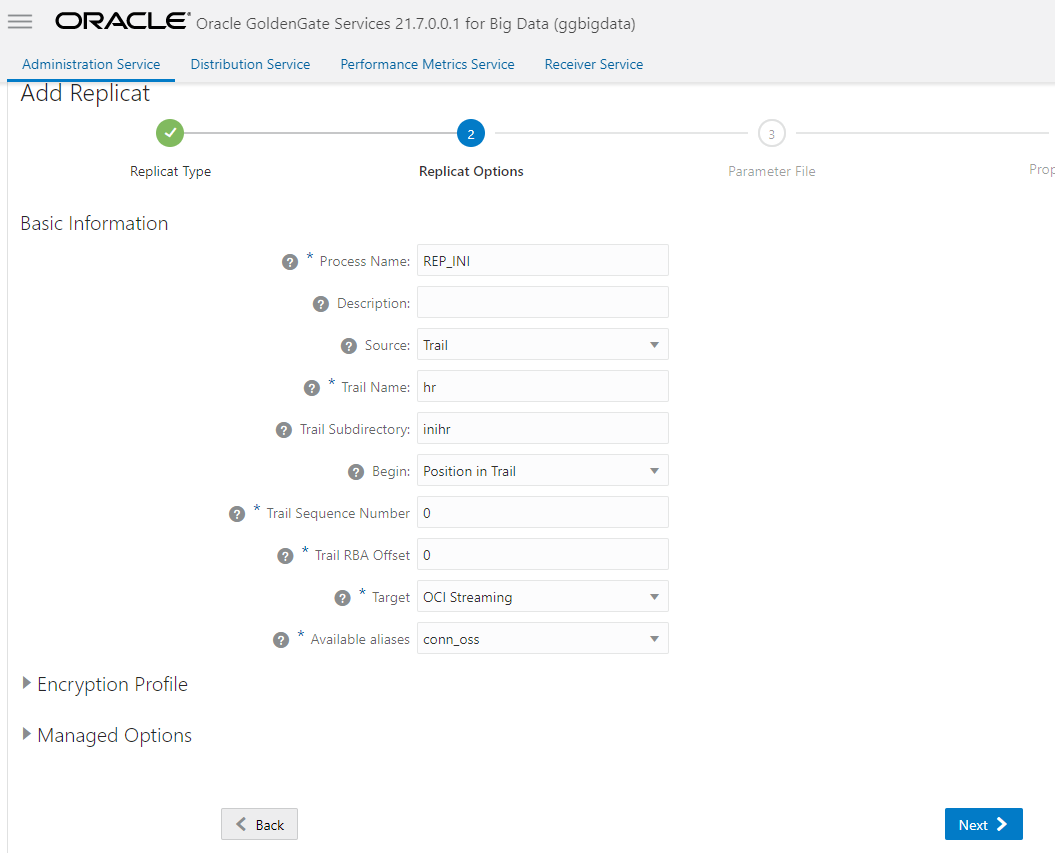
In the Properties File screen, you have to adjust the gg.handler.oss.topicMappingTemplate parameter, here I’m using ${fullyQualifiedTableName} as value, this will control the topic name in OSS and is important to keep the same in both replicats.
Create and run this replicat, you can track the sync within the Statistics screen, here you have to get the same quantity of lines extracted in Initial Load Extract:
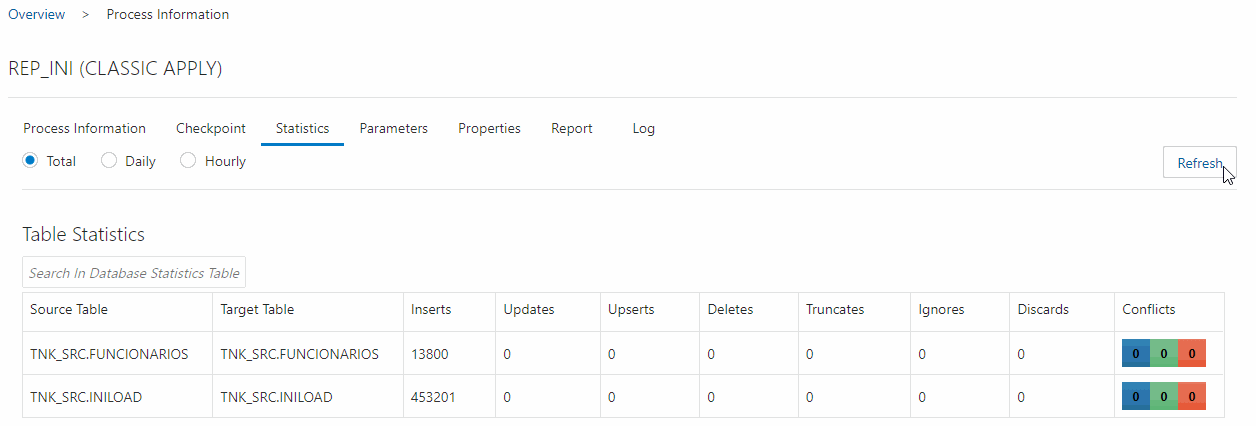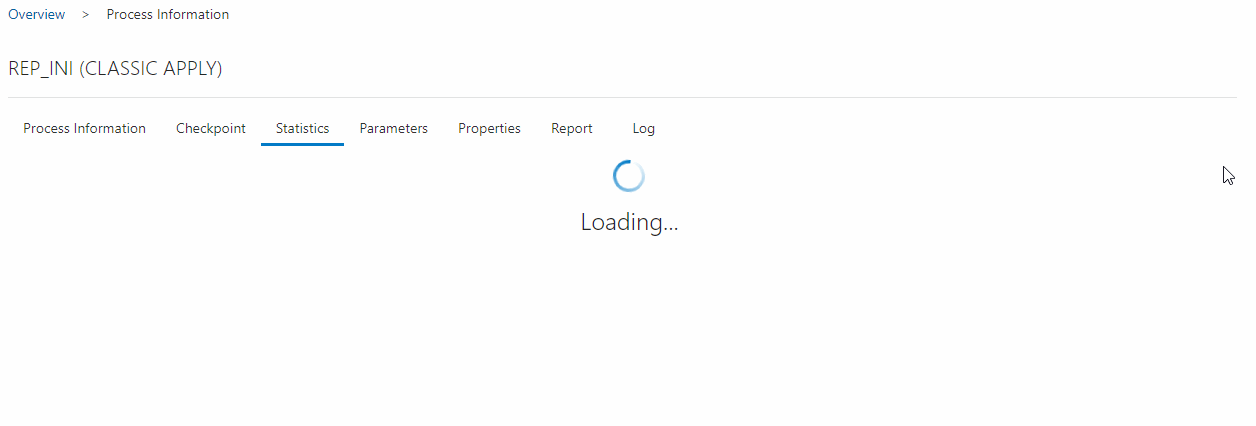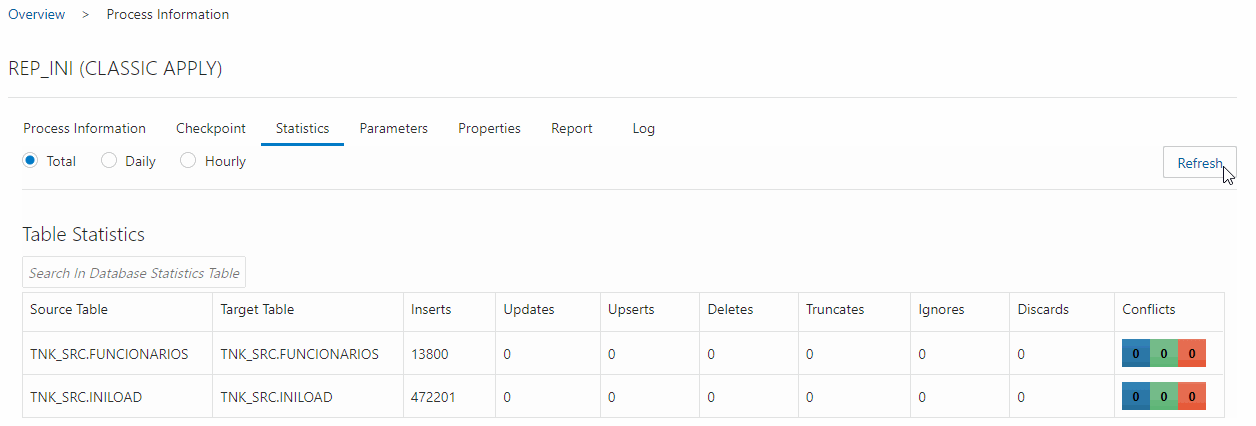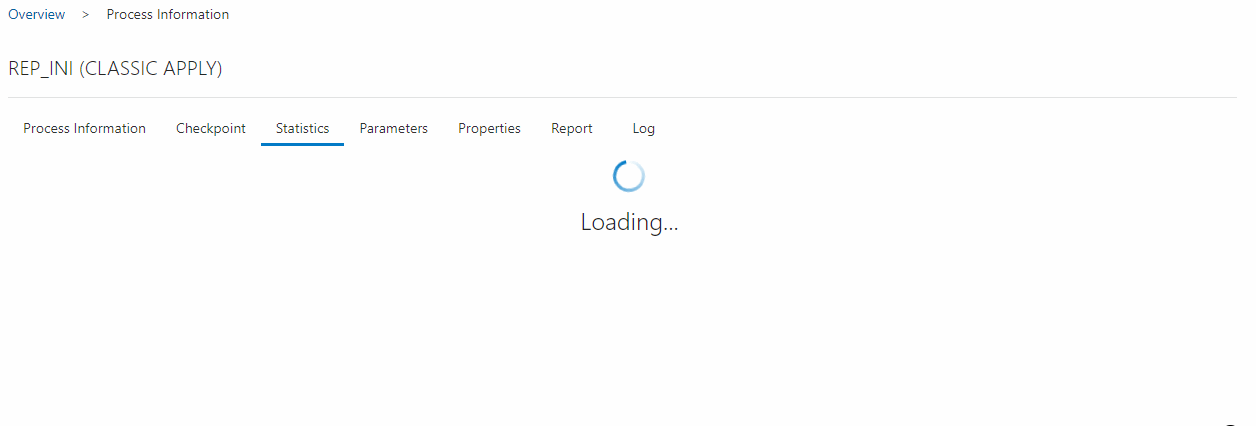
After initial load replicat is completed, you can create the CDC replicat to sync the replication process. Create the CDC replicat and don’t start it yet.
The procedure to create this replicat is the same as before, but you will point the EXT_HR trail file as source and put the same value in gg.handler.oss.topicMappingTemplate.
After CDC replicat is created, go to Administration service Screen-> Click on Action and choose “Start with options” and use the Start point: At CSN and put the captured CSN from beginning, in this way we are telling to OGG to skip transactions after that specific SCN/CSN.
After that you can see in the topic the messages: