As part of my 3 part blog series, I am writing about the GoldenGate Stream Analytics custom stage functionality, how it has been used in one of the Customer’s organization scenarios with examples, and what the architecture was. In this final blog, I will show you how to write the JAVA program to convert the Stream of data into Avro Kafka Messages in Nested format using the “custom-stage” functionality in the GoldenGate Stream Analytics.
As discussed in previous blogs, Custom-stage types and functions are implemented in Java programming language using interfaces, classes, and annotations provided in the osa.spark-cql.extensibility.api.jar library. You can download this jar file from the installation folder: <OSA_INSTALL_DIR>/<OSA_Versions>/osa-base/extensibility-api/osa.spark-cql.extensibility.api.jar
To develop a Custom stage Java program, you must implement the EventProcessor interface, the processEvent() method, and apply the @OsaStage annotation to the class declaration.
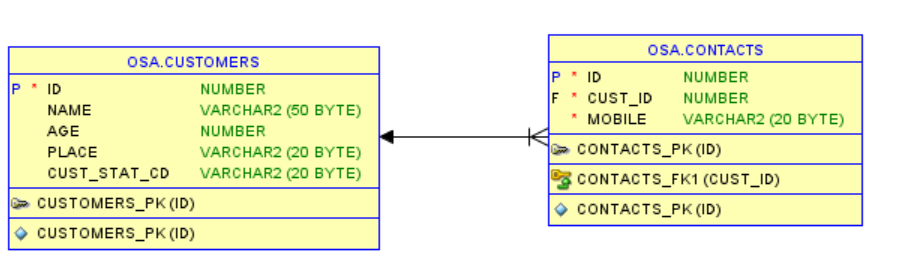
Let us refresh that the Stream of data is “OSA.Customers” table data(Customer’s basic information) fed by GoldenGate Oracle into OSA and OSA.Contacts(Customer’s contact details) are the reference data. We will build the required pipeline in OSA to generate AVRO Kafka messages. The Customer can have zero or more contacts. Please see the image for the structure of the Stream and reference data.
The outcome that the organization is expected from the GoldenGate Stream Analytics after processing data when the status in the CUST_STAT_CD column in the “Customers” data stream event value is equal to “Customer”, the AVRO Kafka message should be generated with the below schema. Since the Customer can have multiple contact mobile numbers, the mobile field is an Array of JSON objects.

Creating Custom Stage Java Program:
There are a lot of references available for Kafka AVRO producer in Java using schema registry. Here is the link for the confluent documentation on Avro Schema Serializer and Deserializer. The OSA Custom Stage Java program will get the data from the previous OSA stage called this Kafka AVRO producer Java program and returns the data as an output that can be used for the following OSA stages or targets.
CustomKafkaAvroProducer Java Program
package com.basha.osa; import org.apache.avro.Schema; import org.apache.avro.generic.GenericData; import org.apache.avro.generic.GenericRecord; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import org.json.simple.JSONArray; import org.json.simple.JSONObject; import org.json.simple.parser.JSONParser; import org.json.simple.parser.ParseException; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.io.IOException; import java.util.ArrayList; import java.util.Iterator; import java.util.Properties; import org.apache.commons.io.IOUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import com.basha.osa.Customer; public class CustomKafkaAvroProducer { private static final Logger log = LoggerFactory.getLogger(CustomKafkaAvroProducer.class); public void sendKafkaAvro(String topic,String hdfsHost,Customer customerRecord) throws IOException, ParseException { System.out.println("start"); log.info("I am a Kafka Producer"); Configuration configuration = new Configuration(); configuration.set("fs.defaultFS", "hdfs://"+hdfsHost+":8020"); FileSystem fileSystem = FileSystem.get(configuration); Path kafkaPropertiesPath = new Path("/osa/properties/kafka.properties"); FSDataInputStream kafkaPropertiesStream = fileSystem.open(kafkaPropertiesPath); Properties kafkaProperties = new Properties(); kafkaProperties.load(kafkaPropertiesStream); Path schemaPath = new Path("/osa/schemas/Customers.avsc"); FSDataInputStream schemaPathStream = fileSystem.open(schemaPath); String avroSchema = IOUtils.toString(schemaPathStream, "UTF-8"); // create Producer properties Properties props = new Properties(); props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaProperties.getProperty("bootstrapServers")); props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, org.apache.kafka.common.serialization.StringSerializer.class); props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, io.confluent.kafka.serializers.KafkaAvroSerializer.class); props.put("schema.registry.url", kafkaProperties.getProperty("SchemaRegistery")); //props.put("schema.registry.url", SchemaRegistery); System.out.println("Propetise set"); // create the producer KafkaProducer<Object, Object> producer = new KafkaProducer<>(props); // create generic Avro record String key = topic+"-key"; System.out.println(avroSchema); Schema.Parser parser = new Schema.Parser(); JSONParser jsonParser = new JSONParser(); Schema schema = parser.parse(avroSchema); //Schema schemaMobile = parser.parse(mobileSchema); Schema schemaMobile = schema.getField("mobiles").schema().getElementType(); GenericRecord avroRecord = new GenericData.Record(schema); ArrayList<GenericRecord> mobile = new ArrayList<GenericRecord>(); JSONArray jsonMobile = (JSONArray) jsonParser.parse(customerRecord.getMobile()); Iterator i = jsonMobile.iterator(); // take each value from the json array separately while (i.hasNext()) { GenericRecord avroMobileRecord = new GenericData.Record(schemaMobile); JSONObject innerObj = (JSONObject) i.next(); System.out.println(innerObj.toString()); System.out.println("mobile " + innerObj.get("mobile") + " id " + innerObj.get("id")); avroMobileRecord.put("id", innerObj.get("id")); avroMobileRecord.put("mobile", innerObj.get("mobile")); mobile.add(avroMobileRecord); //System.out.println(mobile.toString()); } avroRecord.put("id",customerRecord.getId()); avroRecord.put("name",customerRecord.getName()); avroRecord.put("age",customerRecord.getAge()); avroRecord.put("place",customerRecord.getPlace()); avroRecord.put("mobiles",mobile); //avroRecord.put("mobiles",jsonMobile); System.out.println("avro generic record created"); // create a producer record ProducerRecord<Object, Object> record = new ProducerRecord<>(topic, key, avroRecord); try { System.out.println(record.toString()); producer.send(record); System.out.println("producer send"); } catch(Exception e) { System.out.println("exception:"+e.getStackTrace()); e.printStackTrace(); } // When you're finished producing records, you can flush the producer to ensure it has all been written to Kafka and // then close the producer to free its resources. finally { producer.flush(); producer.close(); } } }
SendAvroMessage Java Program
package com.oracle.osacs; import com.oracle.cep.api.event.*; import com.oracle.cep.api.annotations.OsaStage; import com.oracle.cep.api.stage.EventProcessor; import com.oracle.cep.api.stage.ProcessorContext; import java.io.IOException; import java.util.HashMap; import java.util.Map; import org.json.simple.parser.ParseException; import com.basha.osa.Customer; import com.basha.osa.CustomKafkaAvroProducer; @SuppressWarnings("serial") @OsaStage(name = "SendAvroMessage", description = "Procedure to send AVRO messahe", inputSpec = "input, id:int,name:string, age:int, place:string, mobiles:string, avroTopic:string, hdfsHost:string", outputSpec = "output,id:int, name:string, age:int, place:string, mobiles:string") public class SendAvroMessage implements EventProcessor { EventFactory eventFactory; EventSpec outputSpec; @SuppressWarnings("deprecation") @Override public void init(ProcessorContext ctx, Map<String, String> config) { eventFactory = ctx.getEventFactory(); OsaStage meta = SendAvroMessage.class.getAnnotation(OsaStage.class); String spec = meta.outputSpec(); outputSpec = TupleEventSpec.fromAnnotation(spec); } @Override public void close() { } @Override public Event processEvent(Event event) { Attr idAttr = event.getAttr("id"); Attr nameAttr = event.getAttr("name"); Attr ageAttr = event.getAttr("age"); Attr placeAttr = event.getAttr("place"); Attr mobileAttr = event.getAttr("mobiles"); Attr avroTopic = event.getAttr("avroTopic"); Attr hdfsHost = event.getAttr("hdfsHost"); Customer customer = new Customer(); CustomKafkaAvroProducer kafkaAvroProducer = new CustomKafkaAvroProducer(); Map<String, Object> values = new HashMap<String, Object>(); if (!idAttr.isNull()) { // Collect the data from previous stage in a Customer class customer.setId((int) idAttr.getObjectValue()); customer.setName((String) nameAttr.getObjectValue()); customer.setAge((int) ageAttr.getObjectValue()); customer.setPlace((String) placeAttr.getObjectValue()); customer.setMobile((String) mobileAttr.getObjectValue()); values.put("id", customer.getId()); values.put("name", customer.getName()); values.put("age", customer.getAge()); values.put("place", customer.getPlace()); values.put("mobiles", customer.getMobile()); System.out.println(customer.getMobile()); try { // Call the Kafka AVRO producer with Topic, HDFS host and Customer class kafkaAvroProducer.sendKafkaAvro((String)avroTopic.getObjectValue(),(String)hdfsHost.getObjectValue(), customer); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (ParseException e) { // TODO Auto-generated catch block e.printStackTrace(); } } Event outputEvent = eventFactory.createEvent(outputSpec, values, event.getTime()); return outputEvent; }
The pipeline in the OSA looks like the following, where we have 5 stages.
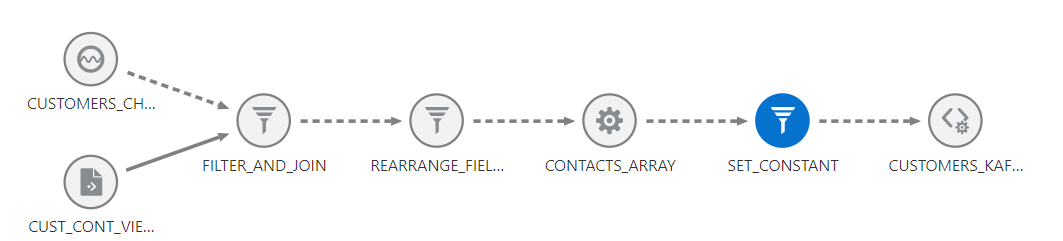
Stage-1, Filtering and Joining:
We are filtering and joining the Customer Change data Capture Stream with Reference data and filters using the condition on the CUST_STAT_CD column equals “Customer”, so that all other records are not considered in the pipeline.
Stage 2, Query Stage – Rearrange Fields:
The transformation that we are going to use in the next stage to merge multiple contact mobile numbers for the Customer is Continuous Merge Transformation. To use this transformation, we need to rearrange the fields in the proper sequence.
Stage-3, Continuous Merge – Contacts Array:
This transformation will merge the multiple contacts into a JSON array. There is no data type in OSA to support JSON array, so the generated JSON array will be in the String format, which we have to parse as JSON in our custom program. Except for the contact id, mobile fields, we have to select all the fields as key fields and name the merge field as mobiles per AVRO schema.
Stage-4, Query Stage – Set Constant:
In this stage, set the constant for avroTopic and hdfsHost name, and rename the fields per AVRO schema.
Stage-5, Custom Stage – Customers Kafka Message:
This is the target stage that receives the data from the previous stage and produces the Kafka AVRO message as per the schema in the schema registry. See the outcome shown below on the screen.

I have worked with Hyseyin Celebi & Abdulhameed Basha on this use case, and special thanks to them for providing the valuable support.
