As part of my 3-part blog series, I am writing about the GoldenGate Stream Analytics custom stage functionality, how it has been used in one of the customer scenarios with examples, what the architecture was, how the pipeline was built, and the Java program that creates the Kafka Avro Nested messages.
Let’s talk about how GoldenGate Stream Analytics works. Real-time data is processed and analyzed in Streaming Pipelines like the one you see on the screen. You process incoming real-time data from several possible sources, such as GoldenGate Extracts from transactional sources, event hubs such as OCI Streaming, Kafka, or JMS, or file sources. The pipeline can be built using an interactive editor, and you can enrich, filter, and aggregate the data and analyze it through predefined patterns, machine learning models, or rules. Finally, you can visualize the data or write it to several targets, such as streaming hubs, relational or no-SQL databases, big data targets, or object stores, and this from different clouds or on-premises.
GoldenGate Stream Analytics is built on the Spark Streaming architecture to provide unlimited horizontal scaling, but at the same time, combines this with our own CQL query engine to provide rich and flexible stream processing semantics.
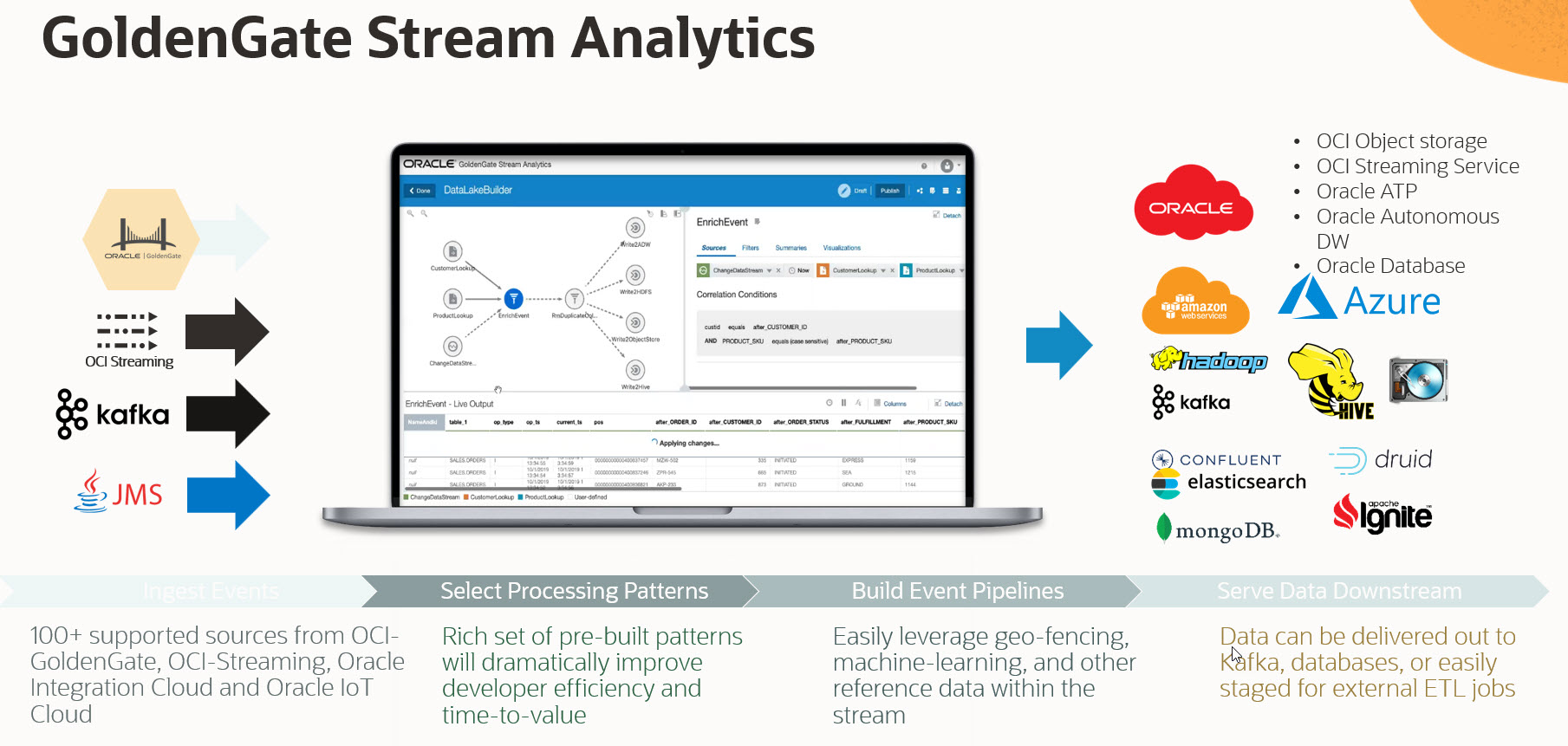
To summarize the key capabilities, GoldenGate Stream Analytics provides an interactive, self-service interface to create low-code ETL pipelines. You can do Time-Series Analytics through in-built patterns to detect trends, outliers, and other relevant occurrences in your data. You can visualize your data in real-time dashboards in the tool and outside using Oracle Analytics Cloud or third-party environments such as Grafana. We provide a rich library of patterns to make rule-based decisions, and you can interactively define geospatial analysis, such as geo-fences, to detect the location or proximity of objects on a map. Finally, a central point is the ability to perform predictive analytics based on machine learning models such as PMML, ONNX, or our own OML Oracle Machine Learning in autonomous databases.
However, suppose the abovementioned functionalities are insufficient, and you want to build your own custom logic while processing the data in the GoldenGate Stream Analytics. In that case, it is very much possible with the “Custom Stage” functionality. The custom stage types or functions allow you to develop business logic unavailable in common stages and functions. For example, uncommon calculations, conversions, or algorithms.
For example, calculate a message digest using the MD5 algorithm. This algorithm is not part of the in-built function library, and it is not practical to implement it as an expression. Or you want to convert the data into another format (AVRO Kafka Nested messages), which is not supported out of the box. There are such scenarios where you need to use a custom stage.
The custom stage types and functions are implemented in Java programming using interfaces, classes, and annotations provided in the osa.spark-cql.extensibility.api.jar library. You can download this jar file from the installation folder: osa-base/extensibility-api/osa.spark-cql.extensibility.api.jar. For more information, see Spark Extensibility for CQL in Oracle Stream Analytics.
For a custom stage type, you must implement the EventProcessor interface and apply the @OsaStage annotation to your class declaration. You must implement the processEvent() method that takes an input Event and returns an Output Event, which must be defined using the input and output spec, respectively.
As part of my future blogs, I will show you the example of custom stage programming and how it has been used in one of the use-cases and respective use-cases & architecture. Until then, stay tuned. For more information about the custom stage, the detailed documentation can be found at Developing Custom Stages and Custom Functions (oracle.com)
