The ongoing debate between SQL and NoSQL is as old as relational database systems. Since Edgar F. Codd introduced the relational database concept in 1970, there has been an ongoing deep tension between structure and flexibility in database systems. SQL databases claim superiority through decades of proven reliability, strong ACID guarantees, and powerful query capabilities ideal for complex, relational data models. In contrast, NoSQL databases argue that rigid schemas can’t keep pace with modern development, offering schema flexibility, simple application development, or better performance for high-velocity or unstructured data.
Each camp claims dominance—SQL for consistency and integrity, NoSQL for speed and agility—yet the real-world trend is convergence, as both camps increasingly work on borrowing features from the other.
SQL and NoSQL: Converging into Multimodel Databases
Multimodel databases like MySQL, PostgreSQL and Oracle are at the forefront of integrating non-relational capabilities into traditionally relational systems. Recent innovations include vector processing, document store features and support for collections of JSON documents. These new capabilities allow developers to:
- Work with JSON documents using familiar document APIs
- Query and process both structured and semi-structured data using SQL
- Combine relational normalization with document-centric development
Multimodel databases Support Native Document Store APIs
All these multi-model databases have introduced a binary format for storing JSON data natively and optimized. This includes Oracle’s OSON format, which has shown advantages over BSON in research for performance and efficiency of incremental updates.
For developers seeking a document-first experience, vendors offer APIs that expose native JSON stores, such as MySQL’s xDev API, PostgreSQL-based FerretDB, or Oracle’s Database API for MongoDB. These APIs provide the simplicity of NoSQL development on top of relational infrastructure. Developers enjoy the simplicity and agility of schema-flexible development without needing a special-purpose document store database.
However, unlike SQL, document store APIs are not standardized and remain vendor specific. Efforts to define a common standard are underway but are still in the early stages.
Querying JSON with SQL
With native JSON support, developers can treat document collections as first-class citizens in the database. Using ANSI SQL/JSON (introduced in SQL:2016), you can extract values, unnest arrays, filter documents and apply SQL functions to JSON content. This bridges relational and semistructured data through a unified language, opening the door to benefit from the power of SQL for analytics and reporting.
Here’s an example that queries a JSON collection of movies, extracts attributes, aggregates gross revenue by year and calculates each year’s revenue share:
WITH revenue AS (
SELECT
m.data.year
, round(sum(JSON_VALUE(data,'$.gross' RETURNING NUMBER NULL ON ERROR NULL ON EMPTY ))/1000000) as millions
FROM movies m
WHERE m.data.gross IS NOT NULL
GROUP BY m.data.year
)
SELECT year
, millions
, ROUND((RATIO_TO_REPORT(millions) OVER ())*100,2) pct_revenue
FROM revenue r
WHERE year > 2000
ORDER BY year DESC;
This example uses both the ANSI SQL/JSON operator JSON_VALUE and Oracle’s simplified dot notation, a straightforward SQL-style way to extract JSON scalar values from a JSON document (m.data.year).
Developers extract and “relationalize” attributes stored in JSON documents, join this information with relational tables, and use nested subqueries or other constructs — the same way they use any available SQL operator or function for relational objects.
Exposing Relational Data as JSON Documents
Conversely, relational data can be exposed as JSON documents using JSON collection views, making it accessible to document-centric applications. The following example creates a JSON collection view on top of Oracle’s EMP table, probably one of the first relational tables ever created for demonstration purposes:
CREATE OR REPLACE JSON COLLECTION VIEW emp_collection AS
SELECT
JSON{‘_id’ : empno,
’employeeName’ : ename,
‘jobRole’ : job}
FROM emp;
Using this collection view through a document store API would return data similar to
json> db.emp_collection.findOne()
{ _id: 7369, employeName: ‘SMITH’, jobRole: ‘CLERK’ }
This bidirectional flexibility blurs the boundaries between SQL and NoSQL and decouples how data is processed from how it is stored.
Beyond Dual Access: JSON Relational Duality
While native binary JSON storage, document APIs and SQL/JSON functionality represent strong progress, JSON Relational Duality takes things a step further. This new capability offers the best of both relational and JSON documents without the trade-offs of either model.
In short, duality views store the JSON documents internally in a highly efficient normalized format, using relational and JSON constructs. At the same time, developers interact with JSON documents.
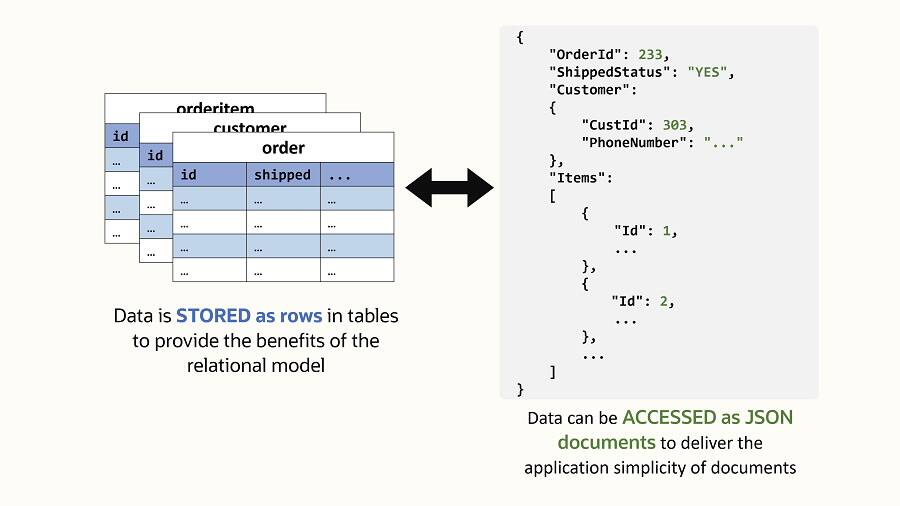
Duality Views – stored as rows, exposed as documents
Whether the application uses REST or document-centric APIs, developers benefit from the simplicity of retrieving and working with all the data needed for a single application-tier object: the JSON document. Creating a JSON duality view is pretty straightforward. Like a JSON collection view, developers define the Object Document Model for the business object as metadata in the database.
Here’s a simple example that defines a duality view to model a conference schedule using GraphQL. The schedule object is comprised of:
The schedule object comprises of:
- The attendee information
- The schedule for an individual attendee
- The schedule represents one or more sessions that an attendee is planning to attend
- The detailed information about a session, including the speaker information.
create or replace JSON Duality view ScheduleV
AS
attendee
{ _id : aid name : aname
schedule : schedule @insert @update @delete
{ scheduleId : schedule_id
sessions @unnest
{ sessionId : sid
name : name
location : room
speaker @unnest
{ speakerId : sid
speaker : name
}
}
}
} ;
JSON Relational Duality, therefore, provides the storage, consistency, and efficiency benefits of the relational model while applications retrieve and manipulate deeply nested JSON structures.
The Best of Both Worlds
The convergence of SQL and NoSQL enables developers to benefit from the simplicity of JSON document development and the power of relational databases with a single database. Multimodel databases eliminate the need to choose one paradigm over another, taking over the single-purpose NoSQL database systems market. Developers don’t have to face the choice between SQL and NoSQL systems and lock themselves into one programming paradigm. They enjoy the flexibility and freedom to pick the best approach for individual applications without sacrificing functionality.
Oracle’s JSON Relational Duality views go beyond coexistence by fusing the strengths of relational and document models into a unified architecture. As multimodel systems continue to evolve, this approach sets a compelling precedent — and others are likely to follow.
This blog post was originally published at https://thenewstack.io/to-sql-or-not-to-sql-that-is-not-the-question/
