Today we have a guest blogger, Dominic Giles, Master Product Manager from Oracle Database providing us with insights into what to expect from Oracle Database 18c.
Oracle Database 18c’s arrival marks a change in the way the world’s most popular database is released. It brings new functionality and improvements to features already available in Oracle Database 12c. In this blog, I’ll highlight what you can expect from this new release and where you can get additional information but first let me address the new release model that the Database team has adopted.
Release schedule
Oracle Database 18c is the first version of the product to follow a yearly release pattern. From here onwards the Oracle Database will be released every year along with quarterly updates. You can find more details on this change by visiting Oracle Support and taking a look at the support Document 2285040.1 or on Mike Dietrich’s blog. If you’re confused as to why we’ve apparently skipped 6 releases of Oracle it may be simpler to regard “Oracle Database 18c” as “Oracle Database 12c Release 2 12.2.0.2”, where we’ve simply changed the naming to reflect the year in which the product is released.
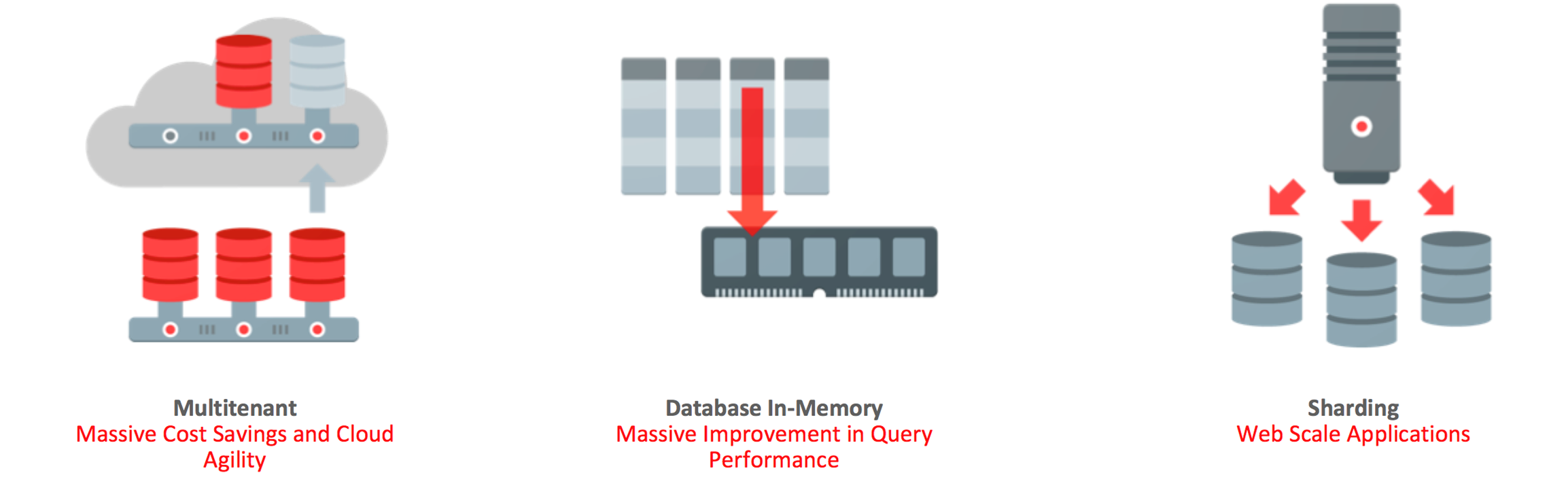
The release itself focused on 3 major areas:
Multitenant is Oracle’s strategic container architecture for the Oracle Database. It introduced the concept of a pluggable database (PDB) enabling users to plug and unplug their databases and move them to other containers either locally or in the cloud. The architecture enables massive consolidation and the ability to manage/patch/backup many databases as one. We introduced this architecture in Oracle Database 12c and extended it capabilities in Oracle Database 12c Release 2 with the ability to hot clone, online relocate and provide resource controls for IO, CPU and Memory on a PDB basis. We also ensured that all of the features available in a non-container are available for a PDB (Flashback Database, Continuous Query etc.).
Database In-Memory enables users to perform lightning fast analytics against their operational databases without being forced to acquire new hardware or make compromises in the way they process their data. The Oracle Database enables users to do this by adopting a dual in-memory model where OLTP data is held both as rows, enabling it to be efficiently updated, and in a columnar form enabling it to be scanned and aggregated much faster. This columnar in-memory format then leverages compression and software in silicon to analyze billions of rows a second, meaning reports that used to take hours can now be executed in seconds. In Oracle Database 12c Release 2 we introduced many new performance enhancements and extended this capability with new features that enabled us to perform in In-Memory analytics on JSON documents as well as significantly improving the speed at which the In-Memory column store is available to run queries after at startup.
Oracle Database Sharding, released in Oracle Database 12c Release 2, provides OLTP scalability and fault isolation for users that want to scale outside of the usual confines of a typical SMP server. It also supports use cases where data needs to be placed in geographic location because of performance or regulatory reasons. Oracle Sharding provides superior run-time performance and simpler life-cycle management compared to home-grown deployments that use a similar approach to scalability. Users can automatically scale up the shards to reflect increases in workload making Oracle one of the most capable and flexible approaches to web scale workloads for the enterprise today.
Oracle 12c Release 2 also included over 600 new features ranging from syntax improvements to features like improved Index Compression, Real Time Materialized views, Index Usage Statistics, Improved JSON support, Enhancements to Real Application Clusters and many many more. I’d strongly recommend taking a look at the “New Features guide for Oracle Database 12c Release 2” available here
Incremental improvements across the board
As you’d expect from a yearly release Oracle Database 18c doesn’t contain any seismic changes in functionality but there are lots of incremental improvements. These range from syntax enhancements to improvements in performance, some will require that you explicitly enable them whilst others will happen out of the box. Whilst I’m not going to be able to cover all of the many enhancements in detail I’ll do my best to give you a flavor of some of these changes. To do this I’ll break the improvements into 6 main areas : Performance, High Availability, Multitenant, Security, Data Warehousing and Development.
Performance
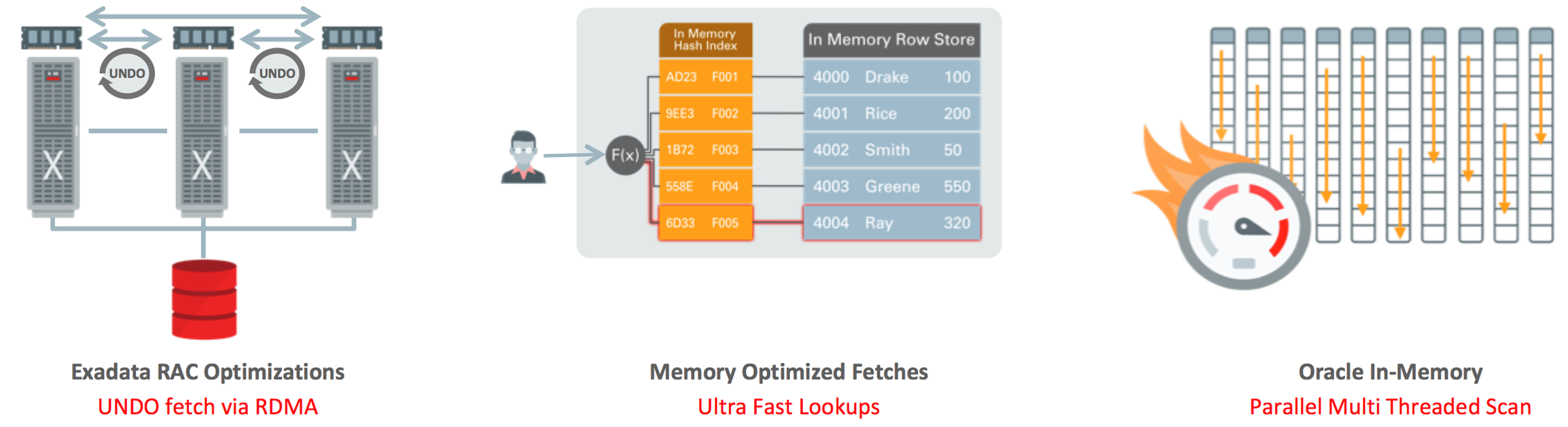
For users of Exadata and Real Application Clusters (RAC), Oracle Database 18c brings changes that will enable a significant reduction in the amount of undo that needs to be transferred across the interconnect. It achieves this my using RDMA, over the Infiniband connection, to access the undo blocks in the remote instance. This feature combined with a local commit cache significantly improves the throughput of some OLTP workloads when running on top of RAC. This combined with all of the performance optimization that Exadata brings to the table, cements its position as the highest performance Database Engineered System for both OLTP and Data Warehouse Workloads.
To support applications that fetch data primarily via a single unique key Oracle Database 18c provides a memory optimized lookup capability. Users simply need to allocate a portion of Oracle’s Memory (SGA) and identify which tables they want to benefit from this functionality, the database takes care of the rest. SQL fetches are significantly faster as they bypass the SQL layer and utilize an in-memory hash index to reduce the number or operations that need to be performed to get the row. For some classes of application this functionality can result in upwards of 4 times increase in throughput with a halving of their response times.
To ease the maintenance work for In-Memory it’s also now possible to have tables and partitions automatically populated into and aged out of the column store. It does this by utilizing the Heat Map such that when the Column Store is under memory pressure it evicts inactive segments if more frequently accessed segments would benefit from population.
Oracle Database In-Memory gets a number of improvements as well. It now uses parallel light weight threads to scan its compression units rather than a process driven serial scans. This is available for both serial and parallel scans of data and it can double the speed at which data is read. This improves the already exceptional scan performance of Oracle Database In-Memory. Alongside this feature, Oracle Database In-Memory also enables Oracle Number types to be held in their native binary representation (int, float etc). This enables the data to be processed by the vector processing units on processors like Intel’s Xenon CPU much faster than previously. For some aggregation and arithmetic operations this can result in a staggering 40 times improvement in performance.
Finally, In-Memory in Oracle Database 18c also allows you to place data from external tables in the column store, enabling you to execute high performance analytics on data outside of the database.
High Availability
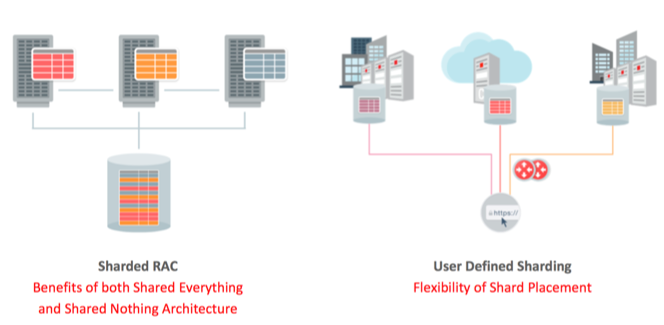
Whether you are using Oracle Real Application Clusters or Oracle DataGuard we continue to look for ways to improve on the Oracle Database’s high availability functionality. With Oracle Database 18c we’re rolling out a few significant upgrades.
Oracle Real Application Clusters also gets a hybrid sharding model. With this technology you can enjoy all of the benefits that a shared disk architecture provides whilst leverage some of the benefits that Sharding offers. The Oracle Database will affinitize table partitions/shards to nodes in the cluster and route connections using the Oracle Database Sharding API based on a shard key. The benefit of this approach is that it formalizes a technique often taken by application developers to improve buffer cache utilization and reduce the number of cross shard pings between instances. It also has the advantage of removing the punitive cost of cross shard queries simply by leveraging RAC’s shared disk architecture.
Sharding also gets some improvements in Oracle Database 18c in the form of “User Defined Sharding” and “Swim Lanes”. Users can now specify how shards are to be defined using either the system managed approach, “Hashing”, or by using an explicit user defined model of “Range” and “List” sharding. Using either of these last two approaches gives users the ability to ensure that data is placed in a location appropriate for its access. This might be to reduce the latency between the application and the database or to simply ensure that data is placed in a specific data center to conform to geographical or regulatory requirements. Sharded swim lanes also makes it possible to route requests through sharded application servers all the way to a sharded Oracle Database. Users do this by having their routing layer call a simple REST API. The real benefit of this approach is that it can improve throughput and reduce latency whilst minimizing the number of possible connections the Oracle Database needs to manage.
For the users of Java in the Database we’re rolling out a welcome fix that will make it possible to perform rolling patching of the database.
Multitenant
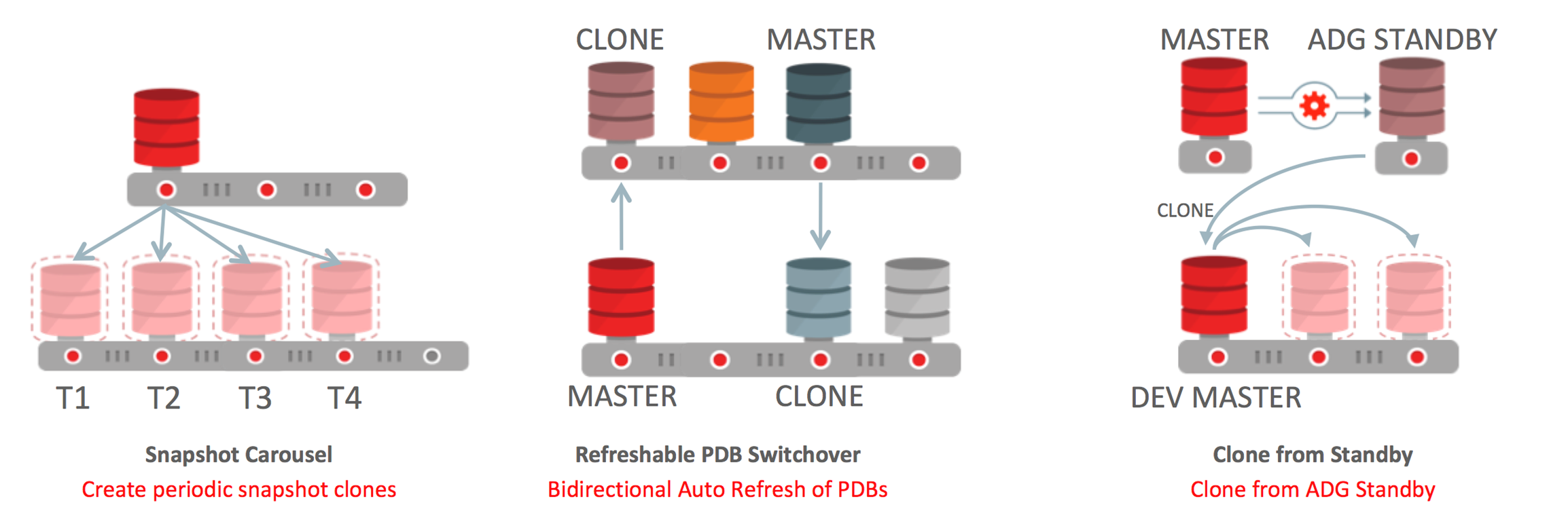
Multitenant in Oracle Database 18c got a number of updates to continue to round out the overall architecture. We’re introducing the concept of a Snapshot Carousel. This enables you to define regular snapshots of PDBs. You can then use these snapshots as a source for PDB clones from various points of time, rather than simply the most current one. The Snapshot Carousel might be ideal for a development environment or to augment a non-mission critical backup and recovery process.
I’m regularly asked if we support Multitenant container to container active/active Data Guard Standbys. This is where some of the primary PDBs in one container have standby PDBs in an opposing container and vice versa. We continue to move in that direction and in Oracle Database 18c we move a step closer with the introduction of “Refreshable PDB Switchover”. This enables users to create a PDB which is an incrementally updated copy of a “master” PDB. Users may then perform a planned switchover between the PDBs inside of the container. When this happens the master PDB becomes the clone and the old clone the master. It’s important to point out that this feature is not using Data Guard; rather it extends the incremental cloning functionality we introduced in Oracle Database 12c Release 2.
In Oracle Database 18c Multitenant also got some Data Guard Improvements. You can now automatically maintain standby databases when you clone a PDB on the primary. This operation will ensure that the PDB including all of its data files are created on the standby database. This significantly simplifies the process needed to provide disaster recovery for PDBs when running inside of a container database. We also have made it possible to clone a PDB from a Active Data Guard Standby. This feature dramatically simplifies the work needed to provide copies of production databases for development environments.
Multitenant also got a number of small improvements that are still worth mentioning. We now support the use of backups performed on a PDB prior to it being unplugged and plugged into a new container. You can also expect upgrades to be quicker under Multitenant in Oracle Database 18c.
Security

The Oracle Database is widely regarded as the most secure database in the industry and we continue to innovate in this space. In Oracle Database 18c we have added a number or small but important updates. A simple change that could have a big impact for the security of some databases is the introduction of schema only accounts. This functionality allows schemas to act as the owners of objects but not allow clients to log in potentially reducing the attack surface of the database.
To improve the isolation of Pluggable Databases (PDBs) we are adding the ability for each PDB to have its own key store rather than having one for the entire container. This also simplifies the configuration of non-container databases by introducing explicit parameters and hence removing the requirement to edit the sqlnet.ora file
A welcome change for some Microsoft users is the integration of the Oracle Database with Active Directory. Oracle Database 18c allows Active Directory to authenticate and authorize users directly without the need to also use Oracle Internet Directory. In the future we hope to extend this functionality to include other third-party LDAP version 3–compliant directory services. This change significantly reduces the complexity needed to perform this task and as a result improves the overall security and availability of this critical component.
Data Warehousing

Oracle Database 18c’s support for data warehousing got a number of welcome improvements.
Whilst machine learning has gotten a lot of attention in the press and social media recently it’s important to remind ourselves that the Oracle Database has had a number of these algorithms since Oracle 9i. So, in this release we’ve improved upon our existing capability by implementing some of them directly inside of the database without the need for callouts, as well as added some more.
One of the compromises that data warehouse users have had to accept in the past was that if they wanted to use a standby database, they couldn’t use no-logging to rapidly load data into their tables. In Oracle Database 18c that no longer has to be the case. Users can make a choice between two modes whilst accommodating the loading of non-logged data. The first ensures that standbys receive non-logged data changes with minimum impact on loading speed at the primary but at the cost of allowing the standby to have transient non-logged blocks. These non-logged blocks are automatically resolved by managed standby recovery. And the the second ensures all standbys have the data when the primary load commits but at the cost of throttling the speed of loading data at the primary, which means the standbys never have any non-logged blocks.
One of the most interesting developments in Oracle Database 18c is the introduction of Polymorphic table functions. Table functions are a popular feature that enables a developer to encapsulate potentially complicate data transformations, aggregations, security rules etc. inside of a function that when selected from returns the data as if it was coming from a physical table. For very complicated ETL operations these table functions can be pipelined and even executed in parallel. The only downside of this approach was that you had to declare the shape of the data returned as part of the definition of the function i.e. the columns to be returned. With Polymorphic tables, the shape of the data to be returned is determined by the parameters passed to the table function. This provides the ability for polymorphic table functions to be more generic in nature at the cost of a little more code.
One of my personal favorite features of this release is the ability to merge partitions online. This is particularly useful if you partition your data by some unit of time e.g. minutes, hours, days weeks and at some stage as the data is less frequently updated you aggregate some of the partitions into larger partitions to simplify administration. This was possible in previous versions of the of the database, but the table was inaccessible whilst this took place. In Oracle Database 18c you merge your partitions online and maintain the indexes as well. This rounds out a whole list of online table and partition operations that we introduced in Oracle Database 12c Release 1 and Release 2 e.g. move table online, split partition online, convert table to partition online etc.
For some classes of queries getting a relatively accurate approximate answer fast is more useful than getting an exact answer slowly. In Oracle Database 12c we introduced the function APPROX_COUNT_DISTINCT which was typically 97% or greater but can provide the result orders of magnitudes faster. We added additional functions in Oracle Database 12c Release 2 and in 18c we provide some additional aggregation (on group) operations APPROX_COUNT(), APPROX_SUM() and APPROX_RANK().
Oracle Spatial and Graph also added some improvements in this release. We added support for Graphs in Oracle Database 12c Release 2. And now in Oracle Database 18c you can use Property Graph Query Language (PGL) to simplify the querying of the data held within them. Performance was also boosted with the introduction of support for Oracle In Memory and List Hash partitioning.
We also added a little bit of syntax sugar when using external tables. You can now specify the external table definition inline on an insert statement. So no need to create definitions that are used once and then dropped anymore.
Development
As you’d expect there were a number of Oracle Database 18c improvements for developers, but we are also updating to our tools and APIs.
JSON is rapidly becoming the preferred format for application developers to transfer data between the application tiers. In Oracle Database 12c we introduced support that enabled JSON to be persisted to the Oracle Database and queried using dot notation. This gave developers a no compromise platform for JSON persistence with the power and industry leading analytics of the Oracle Database. Developers could also treat the Oracle Database as if it was a NoSQL Database using the Simple Oracle Document Access (SODA) API. This meant that whilst some developers could work using REST or JAVA NoSQL APIs to build applications, others could build out analytical reports using SQL. In Oracle Database 18c we’ve also added a new SODA API for C and PL/SQL and included a number of improvements to functions to return or manipulate JSON in the database via SQL. We’ve also enhanced the support for Oracle Sharding and JSON.
Global Temporary Tables are an excellent way to hold transient data used in reporting or batch jobs within the Oracle Database. However, their shape, determined by their columns, is persisted across all sessions in the database. In Oracle Database 18c we’ve provide a more flexible approach with Private Temporary Tables. These allow uses to define the shape of the table that is only visible for a given session or even just a transaction. This approach provides more flexibility in the way developers write code and can ultimately lead to better code maintenance.
Oracle Application Express, Oracle SQL Developer, Oracle SCLCl, ORDS have all been tested with 18c and in some instance get small bumps in functionality such as support for Sharding.
We also plan to release an REST API for the Oracle Database. This will ship with ORDS 18.1 a little later this year.
And One Other Thing…
We’re also introducing a new mode for Connection Manager. If you’re not familiar with what Connection Manager (CMAN) does today, I’d recommend taking a look here. Basically, CMAN allows you to use it as a connection concentrator enabling you to funnel thousands of sessions into a single Oracle Database. With the new mode introduced in Oracle Database 18c, it’s able to do a lot more. It can now automatically route connections to surviving database resources in the advent of some outage. It can also redirect connections transparently if you re-locate a PDB. It can load-balance connections across databases and PDBs whilst also transparently enabling connection performance enhancements such as statement caching and pre-fetching. And it can now significantly improve the security of incoming connections to the database.
All in all, an exciting improvement to a great networking resource for the Oracle Database.
Where to get more information
We’ve covered some of the bigger changes in Oracle Database 18c but there are many more that we don’t have space to cover here. If you want a more comprehensive list take a look at the new features guide here.
https://docs.oracle.com/en/database/oracle/oracle-database/18/newft/new-features.html
You can also find more information on the application development tools here
http://www.oracle.com/technetwork/developer-tools/sql-developer/overview/index.html
http://www.oracle.com/technetwork/developer-tools/rest-data-services/overview/index.html
http://www.oracle.com/technetwork/developer-tools/sqlcl/overview/sqlcl-index-2994757.html
http://www.oracle.com/technetwork/developer-tools/apex/overview/index.html
If you’d like to try out Oracle Database 18c you can do it here with LiveSQL
https://livesql.oracle.com/apex/livesql/file/index.html
For More information on when Oracle Database 18c will be available on other platforms please refer to Oracle Support Document 742060.1
