Oracle Database Release 21 offers many new many and major JSON enhancement and improvements. This blog will give you an overview – with screenshots and examples that you can try out immediately in an always free Autonomous Database like the new Autonomous JSON database (AJD). If you don’t have an Oracle Cloud Infrastructure account, yet then consider singing up now to complete below examples.
Intro on how to run the examples
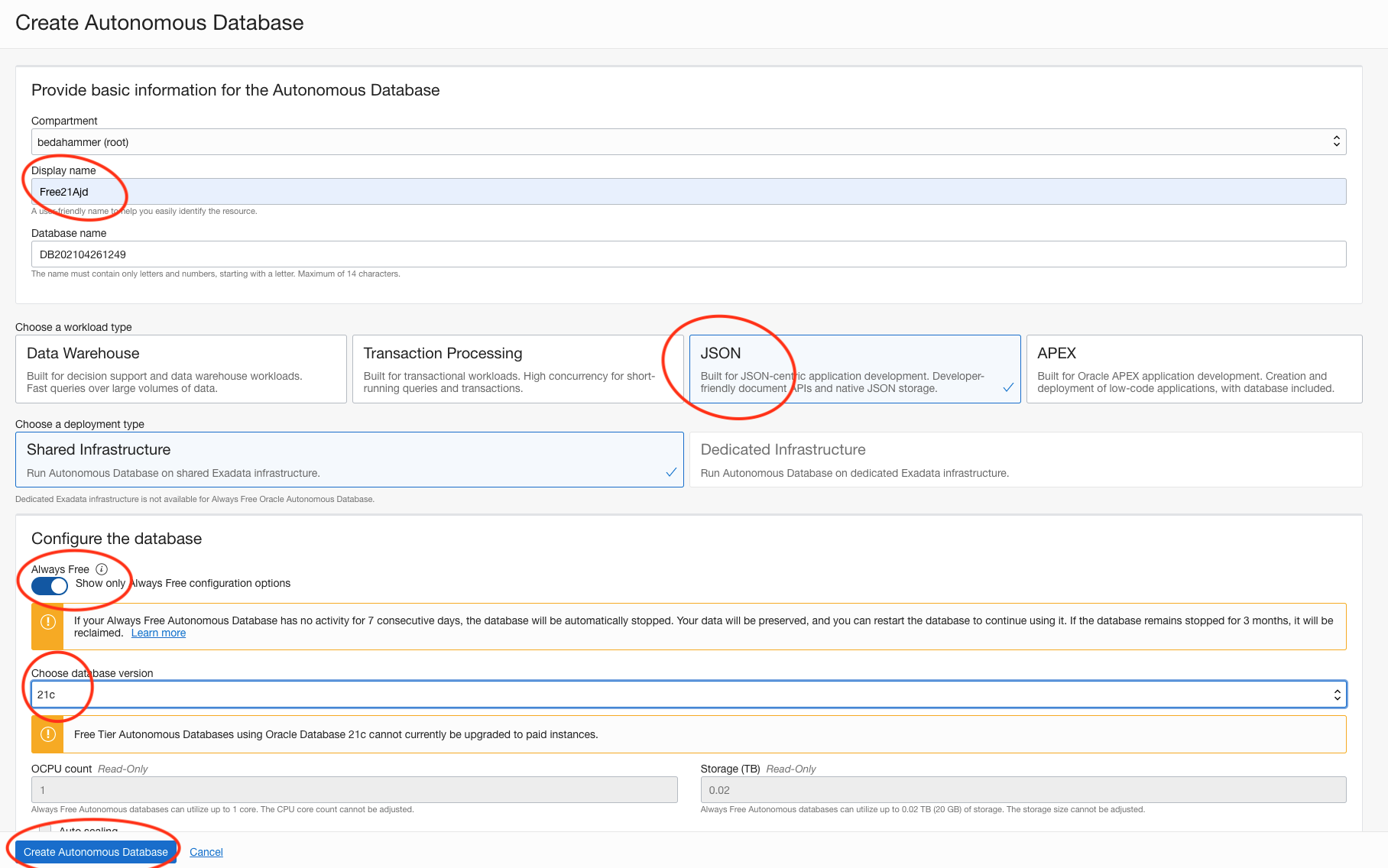
To deploy an always free Autonomous JSON database follow the steps described by the screenshots. You can pick an Autonomous JSON or Autonomous Transaction Processing database. Note: as of now always free Autonomous JSON is only available in the four home region Phoenix, Ashburn, Frankfurt, and London. Pick Autonomous Transaction Processing if you’re in a different region.
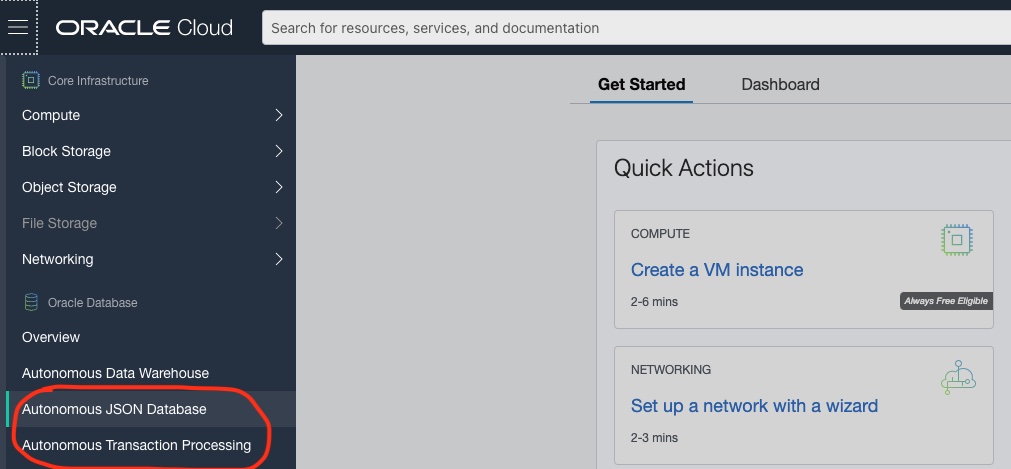
Then click on ‘Create Autonomous Database’. On the next page (screenshot below) give your service a name, pick JSON (or Transaction Processing), make sure to select ‘always free’ and ’21c’ and choose your password (and remember it) – for the rest keep the default.
After some time (minutes) your database is ready. Go to ‘Tool’, select ‘Open Database Action’ , login with ‘ADMIN’ and the password you have chosen. Click on the ‘SQL’ tile – now you can run the following examples:
SQL data type ‘JSON’
The most important and visible extension is likely a new data type ‘JSON’ (another hint showing Oracle’s overall commitment to JSON). This new data type not only allows the user to identify table and view columns and PL/SQL arguments as JSON but also yields performance improvements as the data gets encoded into a binary format. It took us a while to find the best format, we looked at all existing binary formats like BSON, AVRO, Protobufs, etc but found none to be a good match for a database: some needed serial reads (not allowing to ‘jump’ to a selected value), are inefficient on updates (requiring too much data to be written) or required schema management – nullifying some benefits of JSON. So we had to develop a new format, OSON which not only allows fast (hash and offset based) navigation to relevant values but also to minimize the amount of data that needs to be written when performing piece-wise updates (e.g. change a field value) – this greatly improves update performance as fewer data needs to be written to disk or undo/replication logs.
‘JSON’ can be used like any other data type. If you insert textual JSON into a JSON type column then the encoding to the binary format happens implicitly – there is no need to call a JSON constructor (although still possible, see below). Any SQL/JSON operator like JSON_VALUE, JSON_QUERY, JSON_EXISTS, JSON_TABLE, JSON_DATAGUIDE, etc accepts a JSON type as input. Also the simple dot notation can be used; please note that a trailing item method such as number() or string() is needed to convert the selected JSON value to a SQL scalar value. Without such trailing function the simple dot notation returns a JSON type instead. The function JSON_Serialize converts a JSON type instance to a JSON string (serialization); it allows optional pretty printing which makes JSON data easier to read.
Examples:
| create table customers(id number, created timestamp, cdata JSON); insert into customers values (1, systimestamp, ‘{“name”:”Atif”, “address”:{“city”:”San Mateo”}}’); desc customers; — simple dot notation — SQL/JSON operator — Convert the JSON type to a JSON string (binary to text conversion) { |
JSON type can also be used directly as argument type in PL/SQL:
| create or replace function upgradeCustomer(customer JSON) return JSON as select JSON_Serialize(upgradeCustomer(cdata)) {“name”:”Atif”,”address”:{“city”:”San Mateo”},”status”:”silver”} |
Using the ‘returning clause’ it is also possible to generate a JSON type result (example uses Scott.Emp). Please note that a JSON type is printed as [object Object] in the Sql Developer Web interface.
| select JSON_OBJECT(* returning JSON) from emp; |
Note: SODA uses JSON as default data type starting in 21c.
Note: The SQL type JSON is also supported in JDBC so that applications can directly work with the binary format: package oracle.sql.json, JDBC/JSON examples.
Extended data types
Everyone sooner or later finds out that JSON lacks important types like ‘date’ or ‘timestamp’. Sure, it is possible to convert such values to strings (hopefully ISO 8601 formatted) but from a strict point of view the type information is lost. Therefore, the new Oracle JSON type supports additional data types like date, timestamp, double, float, raw, etc. An application (e.g. Java with JDBC driver supporting JSON type) can therefore map programming language values to JSON without any lossy conversion. Also when generating JSON type from relational tables the column’s data types are preserved. No more “this string is really a timestamp”!.
You can find out the type of a JSON value using the type() method at the end of a path expression. The following example uses a WITH clause to create a new JSON object from all columns in the ‘customers’ table. In the following select clause we extract the ‘CREATED’ field but instead if its value we select the type using the type() function. As you see the JSON objects created in the WITH clause subquery preserved that it is a timestamp field.
Example:
| with subQuery as ( timestamp |
JSON_SERIALIZE converts a JSON type instance to textual JSON. It allows pretty printing to make the output easier to read.
An extended data type needs to undergo conversion at this point. Numerical values (integer, float, double) are converted to JSON numbers. Temporal values like date or timestamp are converted to ISO-8601 formatted string.
Example, the WITH clause is the same but now we convert the generated JSON object to a string, the CREATED field becomes a JSON string.
| with subQuery as ( {“ID”:1,”CREATED”:”2021-03-03T14:58:31.465300″,”CDATA”:{“name”:”Atif”,”address”:{“city”:”San Mateo”}}} |
JSON Transform
We already offered multiple ways to update JSON documents, staring from trivial full document replacement, to JSON_Mergepatch or the Pl/SQL JSON api. We added an additional operator ‘JSON_Transform‘ that uses the same path expressions, filter expression, etc as the existing SQL/JSON operators JSON_Value or JSON_Table. JSON_TRANSFORM allows the user to perform multiple modifying operations like setting or removing field values or appending to an array. The operations are executed in the order they’re provided by the user. Optional handlers allow to specify what to do if a field already exists (error, ignore, replace) or is missing in a ‘remove’ operation. A special operation is ‘KEEP’ which accepts a list of path expressions to be preserved in the JSON with all others being removed. This allows for example to only ship a subset of the data to a client if JSON_TRANSFORM is used in the SELECT (not updating the data on disk but creating a transient output). With optional handlers the user can specify what to do if a value is missing: options are to raise an error, ignore it or to create it (see APPEND in the next example).
Example
| update customers select JSON_Serialize(cdata PRETTY) from customers; |
Multi-Value index for JSON arrays
JSON arrays have always been a bit ‘odd’ in a relational database as they highlight the differences between the data models: JSON is a hierarchical (tree) data model where entities are embedded in each other (using nested arrays or objects) whereas tables are flat with just one value per columns and entities connected by relationships (same column value in different tables). Function based indexes used to be limited to one value per column and therefore could not support JSON arrays (We had good ‘workarounds’ like JSON Search index, materialized views, etc). But now in 21c we added a true multi-value functional index allowing to index specific values in JSON arrays.
Example:
| –insert a new customer with multiple addresses insert into customers values (2, systimestamp,
create multivalue index cust_zip_idx
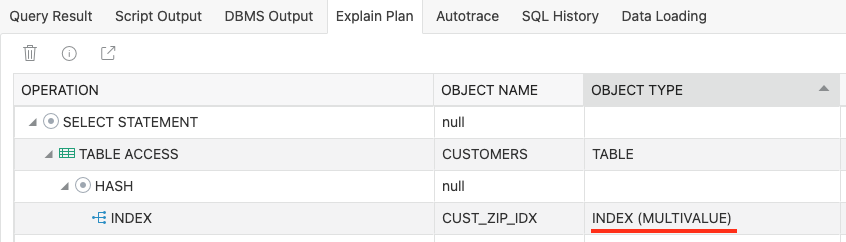
— this will use the multi-value index (see plan)
— Note to always use JSON_EXISTS to use the multi-value index. select JSON_serialize(cdata) ORA-40470: JSON_VALUE evaluated to multiple values |
Simplified JSON constructor syntax
A simpler syntax to generate JSON is being provided that makes the queries shorter and more readable. These are shortcuts for SQL/JSON operators JSON_Object and JSON_Array.
Examples:
| select JSON{*} from emp; select JSON[1,2,’cat’] from emp; are equivalent to select JSON_Object(*) from emp; |
Note: In SQL Dev Web above syntax is not supported yet. As a temporary workaround you need to provide JDBC escaping as follow: select {\ JSON_Serialize(JSON {*} ) \} from dual;
Trailing item methods in path expressions
Everyone who has used the SQL/JSON functions JSON_VALUE or JSON_TABLE has encountered JSON path expressions like ‘$.customer.address.city’ to navigate inside the JSON data. Less known is that these path expressions can end with a method like number() and count(). These methods allow to perform an operation on the selected values(s), for example to convert them to another type, get their type or perform a filter or aggregate. Item methods were already present in previous releases but 21c adds a few more.
Examples:
| with jtab as (select JSON_Array(1,2,3,4,5,6) jcol from dual) 6 with jtab as (select JSON_Array(1,2,3,4,5,6) jcol from dual) 21 with jtab as (select JSON_Array(1,2,3,4,5,6) jcol from dual) 3.5 |
Trailing functions are also relevant when working with (scalar) JSON Types because they are not directly comparable, indexable or usable in GROUP/ORDER BY expression. For these cases a trailing item method is used to ‘tell the database’ how the scalar JSON value is to be treated.
Example:
| — the following 2 queries raise an error as select count(1)from customers c select count(1)from customers c — works with trailing item method to convert JSON type |
Support of new JSON RFC (allowing scalar values)
At the development time of our initial JSON database release the then current JSON RFC (4627) prescribed that JSON is either an Object or Array. Since then this RFC has been obsoleted multiple times (the current RFC is 8259). Most importantly, scalar values are now also considered JSON. This means a JSON document can now consist of just one scalar value like 1, false or “dog”.
Hence, these values now need to pass the IS JSON operator. We have therefore extended the IS JSON SQL operator to conditionally accept or reject scalar values. The default changes after setting compatibility to 21 to accept scalar values! This way we are compliant with the current JSON RFC 8259.
Examples:
| create table whatsJson (val varchar2(30)); select val from whatsJson where val is NOT json; — enforce old RFC: ‘disallow scalars’ |
Programing Language (client) Drivers:
To get the most out of the JSON type we strongly recommend you use the latest client drivers which understand the new SQL data type ‘JSON’. Older drivers (pre-21c) will work but the JSON type will be converted automatically to textual JSON (so that you lose advanced type information for timestamps, dates, etc). Thus it is highly recommended you upgrade to a 21c client driver to get both JSON type functionality and best performance .
You find Java JDBC examples here: https://github.com/oracle/json-in-db/tree/master/JdbcExamples.
For Python and NodeJS use the latest cx_oracle drivers: https://oracle.github.io/python-cx_Oracle
Summary
Oracle’s 21c database release added a lot of new and exciting JSON features – making your live as developer easier and more productive. The 21c JSON Developer Guide and the documentation for the Autonomous JSON Database are great way to get started.
