In previous posts, we explored how similarity search works, the types of vector indexes available to speed up similarity searches, and a new LiveLabs workshop to let you try out AI Vector Search for yourself. Today, I want to take it a step further and show how Oracle AI Vector Search can play a pivotal role when interacting with Generative AI.
Retrieval Augmented Generation (RAG) not only retrieves relevant documents like similarity search but also uses Generative AI to interpret and synthesize information from those documents, producing more accurate, contextual, and user-friendly answers, especially for complex or nuanced queries where simple retrieval would fall short.
What is RAG?
Retrieval Augmented Generation (RAG) involves augmenting prompts to Large Language Models (LLMs) with additional data, thereby expanding the LLM’s knowledge beyond what it was trained on. This can be newer data that was not available when the LLM was trained, or it may be private, enterprise data that was never accessible to the LLM. LLMs are trained on patterns and data up to a point in time. After that, new data is not available to an LLM unless it is re-trained to incorporate that new data. This can lead to inaccurate answers or even made-up answers, also known as hallucinations, when the LLM is asked questions about information that it knows nothing about or only has partial knowledge of. The goal of RAG is to address this situation by supplying additional, relevant information about the questions being asked to enable the LLM to give more accurate answers. This is where AI Vector Search fits. AI Vector Search can be used to pass private business or database data to the LLM using SQL.
The RAG workflow or pipeline with AI Vector Search:
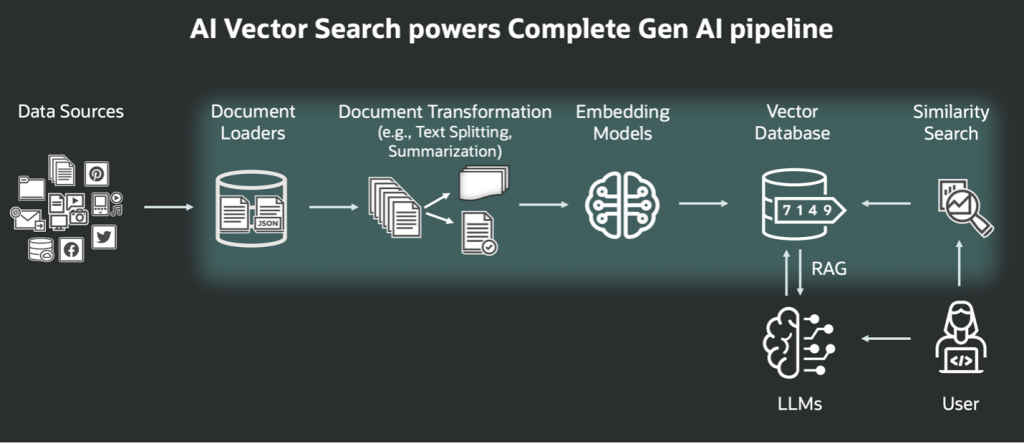
Overview
My purpose in this post is to show you how to construct a very simple RAG pipeline using Oracle AI Database 26ai Free, which has AI Vector Search built in, and a private LLM.
NOTE: The example in this post is intended to illustrate how the RAG workflow works with AI Vector Search. I purposely chose a very simple scenario that could easily be run on a laptop so that it would be easier to see how all the pieces fit together.
As a caveat, before we start. If you’re not interested in how all the pieces are installed and what it takes to set up and run RAG, that’s OK because I have put the actual setup details in another file in my Github repository. In this post, I will describe the setup at a high level and then walk you through three SQL queries, all using the same natural language question. First, a simple SQL query is used to send the natural language question to a private LLM from Oracle AI Database. Then we will run a second query, a similarity search using AI Vector Search, to find the private data relating to the natural language question we want to pass to the LLM to augment our query. Finally, we will run a third RAG based SQL query that will combine both our simple query from step 1 and our augmented data from step 2 to show how adding private data can really make a difference in how the LLM answers a question.
Setup
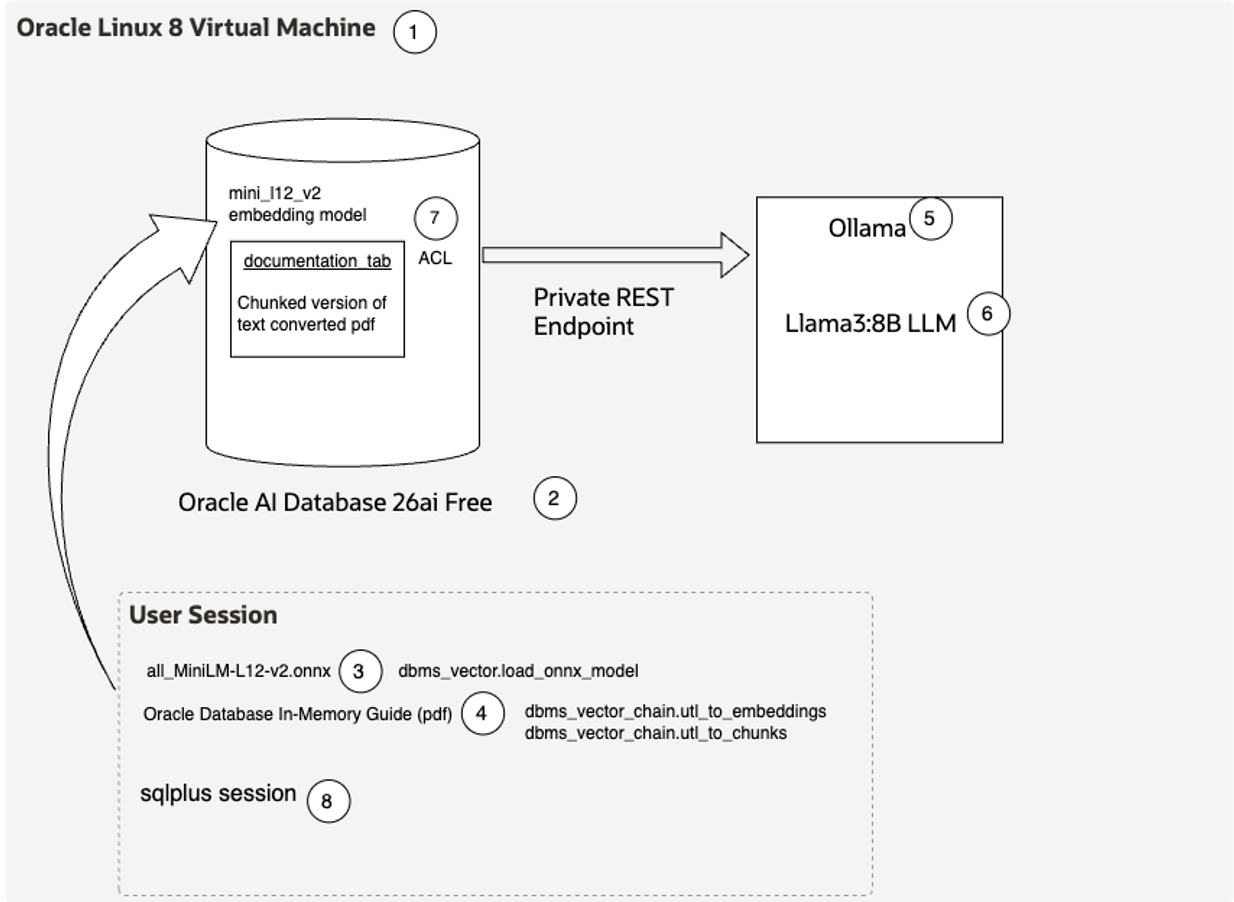
For this post I used the Oracle Linux 8 RPM version in an Oracle Linux 8 virtual box that I had already set up. I then installed an Oracle AI Database 26ai Free database and created a user with the appropriate privileges and space.
Once I had a running Oracle AI 26ai Free database I installed the pre-built all-MiniLM-L12-v2 vector embedding model into the database. That process is described in the Getting Started with Oracle AI Database AI Vector Search blog post and has been used in my other posts as well. I then loaded a pdf version of the 26ai Database In-Memory Guide into the database and, we will address this in more detail later in the post, I created vector embeddings in the database for the Database In-Memory Guide by converting the pdf to text and then creating smaller chunks of the text before using the all-MiniLM-L12-v2 embedding model to create the actual vector embeddings.
My next step was to install the Ollama application in my database server. The Ollama application is open-source software that runs LLMs and can provide a REST endpoint. It runs directly in the Linux OS and it does not get installed in the database. If that sounds confusing, and it did for me, then you can get more details about Ollama in this Oracle documentation. I then ran Ollama and pulled down the latest version of the Llama3:8B LLM since that was small enough to work on my machine. You have choices as to what LLM you would like to use, but I tried to keep things as simple as possible. And lastly, I had to create a network ACL to allow my Oracle AI Database to access Ollama. If you have a network proxy then you may also have to define that as well, but I did not. This is all documented in the SQL RAG Example in the AI Vector Search User’s Guide.
I created the following diagram, with step numbers in circles, to help you visualize all of the steps involved. For the rest of the post, I ran each of the queries in a SQL*Plus session (step 8 in the diagram), but they could be run in pretty much any tool you want since everything is run in the Oracle AI Database that we created in step 2.
Part 1: Simple LLM SQL Query
To start, I wanted to ensure that I could ask the LLM a question from the database via SQL. I also wanted to see what kind of response I would get back so that I could compare that response with an augmented RAG query. The question I asked was, “How to size the IM column store”. This question is passed as a bind variable called user_question in the query below.
I also needed to set up a parameter string to tell Oracle how to access the LLM. That string gets passed as a bind variable called llm_params, and you can see another example in the Oracle AI Vector Search User’s Guide in the section Generate Summary Using the Local REST Provider Ollama. Some additional parameters will be explained later.
The SQL run was the following:
variable llm_params varchar2(1000);
variable user_question varchar2(1000);
exec :llm_params := '{"provider":"ollama","host":"local","url":"http://localhost:11434/api/generate",
"model":"llama3","transfer_timeout":600,"temperature":0,"topP":0.000001,"num_ctx":8192}';
exec :user_question := 'How to size the IM column store';
with
llm_prompt as
(select ('Question: ' || :user_question ) as prompt_text from dual)
select to_char(dbms_vector_chain.utl_to_generate_text(prompt_text, json(:llm_params)))
as llm_response from llm_prompt;The following is the answer that came back:
LLM_RESPONSE
--------------------------------------------------------------------------------
Sizing an In-Memory (IM) column store in an Oracle database! That's a crucial
step to ensure your system performs well and efficiently uses memory. Here's a
step-by-step guide to help you size your Oracle Database IM column store:
**Understand the basics**
Before we dive into sizing, make sure you understand the following:
1. **IM Column Store**: A storage area in Oracle Database 12c Release 2 (12.2)
and later that stores data in memory.
2. **Memory-to-Disk Ratio**: The ratio of memory used for IM column store versus
disk storage.
**Gather requirements**
To size your IM column store, you'll need to consider the following factors:
1. **Data Size**: Estimate the total amount of data you want to store in the IM
column store.
2. **Query Patterns**: Understand the types of queries that will be executed on
the IM column store data (e.g., read-only, update-heavy).
3. **System Configuration**: Know your system's CPU, memory, and disk resources.
4. **Oracle Version**: Verify you're running Oracle Database 12c Release 2
(12.2) or later.
**Calculating the Memory-to-Disk Ratio**
To determine the optimal memory-to-disk ratio, follow these steps:
1. **Estimate the total size of data**: Based on your business requirements and
query patterns, estimate the total amount of data you want to store in the IM
column store.
2. **Calculate the required memory**: For a typical IM column store, allocate
10-20% of the total data size as memory (e.g., if you have 100 GB of data,
allocate 10-20 GB for memory).
3. **Determine the disk space needed**: Calculate the remaining data size that
will be stored on disk (e.g., 80-90 GB in our example).
**Example calculation**
Let's use the above example:
* Total data size: 100 GB
* Required memory (10-20%): 10-20 GB
* Disk space needed: 80-90 GB
In this case, you'd allocate around 15 GB of memory for the IM column store and
leave about 85 GB of disk space for storing the remaining data.
**Additional considerations**
When sizing your IM column store:
1. **Leave room for overhead**: Consider adding 10-20% extra memory to account
for Oracle's internal management and indexing structures.
2. **Adjust based on query patterns**: If you expect a large number of read-only
queries, you may be able to reduce the memory allocation. For update-heavy
workloads, you may need to increase memory allocation.
3. **Monitor performance**: After deploying your IM column store, monitor system
performance and adjust memory-to-disk ratios as needed.
By following these steps and considering your specific use case, you'll be well
on your way to sizing an efficient Oracle Database IM column store for your
application.Unfortunately, that is not a very good answer, but it is not really unexpected since it is doubtful that the Llama3 LLM was trained on Oracle Database documentation. However, this gives us a good opportunity to see how RAG works and if we can improve upon this answer.
For those of you who might not be familiar with Oracle Database In-Memory, the above answer treats the IM column store, which is where Oracle Database can store columnar formatted data, as just another cache, like the database buffer cache. Sizing the IM column store doesn’t really have anything to do with the total amount of database disk space, and instead the answer should describe how to size the IM column store, that is, setting the INMEMORY_SIZE parameter, and ideally mention something about how to determine the size to use.
LLM Answers are Probabilistic, not Deterministic
The other disturbing thing that I discovered is that LLMs tend to give different answers to the same question. As I experimented with questions, I discovered that I would get different answers to the same question. For a database guy who is used to getting the same results from a query, this lack of reproducibility was quite concerning. After doing a bit of research, it turns out that this is a well-known issue in the world of LLMs. Without going into a lot of detail, and you can search for blogs about this phenomenon yourself if you are interested, it turns out that there are parameters available that can influence the reproducibility of answers. It appears from my testing that in most cases, you cannot achieve true determinism, but it seems that you can get pretty close. I experimented with two parameters, part of the parameter llm_params list mentioned previously, that affect how the LLM generates output, temperature and top_p. These parameters affect how tokens are evaluated, and I settled on a temperature of 0 and a very small top_p of 0.000001.
Part 2: Supplemental Data Similarity Search
Our second query will run a similarity search based on the PDF version of the 26ai Database In-Memory Guide that I described at the beginning of the post. This involved loading the PDF into the database as a BLOB, converting it into text using DBMS_VECTOR_CHAIN.UTL_TO_TEXT and then chunking the text into smaller chunks using DBMS_VECTOR_CHAIN.UTL_TO_CHUNKS.
Creating the Data Set
When working with large textual data, it needs to be split into smaller “chunks” that can be processed by embedding models. You can read more about how this process works in the Oracle AI Vector Search User’s Guide. This can enhance the relevance of the text being vectorized. Large portions of text often contain many different concepts that are not necessarily relevant to each other, and embedding models limit the size of the text they can work on. The process of how I decided to do the chunking will be the subject of a follow up blog post.
Running a Vector Search Query
The following is the AI Vector Search query that I ran and the result:
variable user_query varchar2(1000);
exec :user_query := 'How to size the IM column store';
with
top_k as
(select embed_data from doc_chunks
where doc_id = 1
order by vector_distance(embed_vector, VECTOR_EMBEDDING(minilm_l12_v2
USING :user_query as data), COSINE)
fetch first 3 rows only)
select LISTAGG('Chunk: ' || embed_data, CHR(10)) as prompt_text from top_k;
PROMPT_TEXT
--------------------------------------------------------------------------------
Chunk: Prerequisites
To increase the size of the IM column store dynamically using
ALTER SYSTEM, the instance must meet the following prerequisites:
The IM column store must be enabled.
The compatibility level must be 12.2.0or higher.
The database instances must be started with an SPFILE.
The new size of the IM column store must be at least 1 granule.
Steps
1.In SQL*Plus or SQL Developer, log in to the database with administrative
privileges.
2.Optionally, check the amount of memory currently allocated for the IM column
store: SHOW PARAMETER INMEMORY_SIZE
3.Set the INMEMORY_SIZE initialization parameter to a value greater than the current size of
the IM column store with an ALTER SYSTEM statement that specifies SCOPE=BOTH or SCOPE=MEMORY.
?
When you set this parameter dynamically, you must set it to a value that is higher than its current value, and there must be enough memory available in the SGA to increase the size of the IM column store dynamically to the new value.
Chunk: 3-5
< Text deleted here that related to the Table of Contents. If you want to see all of the text you can review the actual output here on my Github repository. >
Chunk: Chapter 3
< Text deleted here that related to the Table of Contents. If you want to see all of the text you can review the actual output here on my Github repository. >
Increasing the Size of the IM Column Store Dynamically For example, the following statement sets INMEMORY_SIZE to 500M dynamically:
ALTER SYSTEM SET INMEMORY_SIZE = 500M SCOPE=BOTH;
See Also:
"Enabling the IM Column Store for a CDB or PDB"
Oracle Database Reference for more information about the INMEMORY_SIZE initialization parameter Views for Working Automatic Sizing of the IM Column Store V$INMEMORY_SIZE_ADVICE
estimates usage and performance statistics for different simulated sizes of the In-Memory Column Store (IM Column Store).
For various sizes of the CDB In-Memory column store, this view forecasts the cumulative time
spent by database in processing user requests. This includes wait time and CPU time for all
non-idle user sessions
See Also: V$INMEMORY_SIZE_ADVICE is described in the Oracle Database Reference.
Disabling the IM Column Store
You can disable the IM column store by setting the INMEMORY_SIZE initialization parameter to
zero, and then reopening the database.
Assumptions
This task assumes that the IM column store is enabled in an open database.
To disable the IM column store:
1.Set the INMEMORY_SIZEnitialization parameter to 0 in the server parameter file (SPFILE).
2.Shut down the database.
3. Start a database instance, and then open the database.There are a couple of things to note in addition to the information that was returned:
- The format above has been condensed slightly and part of it removed as described in the notes above to make it easier to read. The entire second chunk contained Table of Contents information, so it was really not useful. If you want to see the original output you can view it on my Github repository.
- The embedding model used to create the vector embeddings and to embed the question must be the same. In this case, it is the all-MiniLM-L12-v2 embedding model described earlier.
- The data being passed to the LLM will be used for the response. If extraneous information not relevant to the question is sent, I found that it will affect the response by being included in it. This is why I limited the return set to just three rows. For this example, I found that any more than three rows included additional information that was not relevant to actually sizing the IM column store. This will also be mentioned in the RAG Query section below.
Part 3: RAG Query
Now let’s run our RAG query by putting both our question and our additional supplemental information together into one final SQL query:
variable llm_params varchar2(1000);
variable user_question varchar2(1000);
exec :llm_params := '{"provider":"ollama","host":"local","url":"http://localhost:11434/api/generate",
"model":"llama3","transfer_timeout":600,"temperature":0,"topP":0.000001,"num_ctx":8192}';
exec :user_question := 'How to size the IM column store';
with
top_k as
(select embed_data from doc_chunks
order by vector_distance(embed_vector, VECTOR_EMBEDDING(minilm_l12_v2
USING :user_question as data), COSINE)
fetch first 3 rows only),
llm_prompt as
(select ('Question: ' ||
:user_question || ', Context: ' || LISTAGG(embed_data, CHR(10))) as prompt_text
from top_k)
select to_char(dbms_vector_chain.utl_to_generate_text(prompt_text, json(:llm_params))) as
llm_response from llm_prompt;
LLM_RESPONSE
--------------------------------------------------------------------------------
To size the In-Memory (IM) column store, follow these steps:
1. **Enable the IM Column Store**: Set the `INMEMORY_SIZE` initialization
parameter to a value greater than zero before restarting the database instance.
2. **Estimate the Required Size**: Estimate the required size of the IM column
store based on the expected number of rows and data density in your tables.
3. **Sizing the In-Memory Area**: Ensure that the `INMEMORY_SIZE` is set to a
value that allows for sufficient space to store your data.
Additional Tips:
* You can dynamically increase the `INMEMORY_SIZE` size setting by using an
`ALTER SYSTEM` statement.
* Views are available to help with automatic sizing of the IM column store.
* Disabling the IM Column Store: Set `INMEMORY_SIZE` to 0 to disable the IM
column store.
* Not all columns will be populated in the IM column store, including
out-of-line columns (varrays, nested table columns, and out-of-line LOBs).
* Inline LOB columns may require up to 4 KB or 32 KB of contiguous buffer storage.
For more information, refer to Chapter 3: Enabling and Sizing the IM Column
Store in your documentation.That’s a much better answer than what we saw from just the LLM. As I mentioned earlier in the “Part 1: Simple LLM SQL Query” section, the answer should describe how to size the IM column store, that is, setting the INMEMORY_SIZE parameter, and ideally mention something about how to determine the size to use.
Note that we only retrieved 3 “rows” from the DOC_CHUNKS table, as I mentioned previously in “Part 2: Supplemental Data Similarity Search” section (and we know that the second row did not contain helpful information). One of the interesting things that I found is that the LLM will essentially use just the augmented data as the basis for its answer. In this case, using more than three rows started returning even more data that was not directly relevant to our question. This means that any chunks further in vector distance from our question than the third chunk have a negative effect on the answer to the question.
There are also size limits for database datatypes and the LLM, just like there are limits for the embedding model. Using LISTAGG to concatenate the vector search output limits you to the size of the supported VARCHAR2, that is either 4K or 32K if extended string support is enabled. This can be overcome by using PL/SQL to concatenate the query output into a CLOB and then passing that CLOB to the LLM. However, the LLM used will only support a limited amount of text. For the Llama3 model used, the context length was 8K. In addition, Ollama has a default input of 2048, which is why I used the "num_ctx":8192 setting to increase the size to 8192.
To summarize, in our final RAG example, we have been able to direct the LLM to give us a more accurate response than what we would have gotten from just the LLM alone. We were able to do this by using data returned from an AI Vector Search query. In this example, we were able to do all of this with a simple SQL statement directly in Oracle AI Database.
