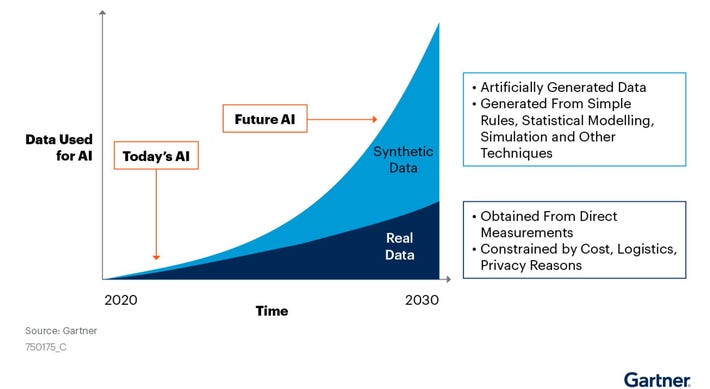
The generation of synthetic data has seen a major uprise in the last few years. According to The Executive’s Guide to Accelerating Artificial Intelligence and Data Innovation with Synthetic Data, synthetic data generation is a privacy-preserving method where the private and sensitive data in the original data is replaced by the synthetic data and predominantly used in machine learning (ML) model training.
In the development of AI, by 2024, an estimated 60% of all data used in ML model training will be synthetically generated. Similarly, Gartner expects synthetic data to overrule the use of real data in machine learning soon.
Synthetic data types
Different forms of synthetic data exist, ranging from synthetically generated text, images, audio recordings, to relational data. Well-known examples of synthetically generated images are showcased on thispersondoesnotexist.com. As the name implies, the person in the image doesn’t actually exist but is generated based on many images of human faces. Similarly, deep learning algorithms can produce new, synthetic texts, audio recordings, and relational data. In a famous example in generating synthetic text, a college student used OpenAI’s GPT-3 to create a synthetic blog by providing a headline and an introduction. The blog went viral with only a few people noticing that the blog was generated by AI.
Generative adversarial networks
In the generation of synthetic data, generative adversarial networks (GANs) are a popular method. Since the introduction of GANs by Goodfellow in 2014, researchers have developed many different GANs specific to a task. For example, thispersondoesnotexist.com uses StyleGAN2 to generate synthetic images. Similarly, TextGAN generates text, and CTGAN can generate relational data, such as tables. GANs can not only generate full blown images but also enhance, change, or append an existing image. GANpaint, enables you to change an existing painting by adding or deleting elements in the painting by brushing over the painting.
Think about casually removing a chair in a painting or adding a tree to a painting. In the same way, a collective of researchers named Obvious used a GAN to generate a portrait displayed and auctioned by the well-known auction house Christie’s in New York. The artwork sold at auction for 4300% of its estimated price.
The inner workings of a GAN consist of two competing neural networks: A generator and a discriminator. A good comparison is an imposter trying to generate fake money (The generator) and the police detecting fake or real money (The discriminator). At the start, the imposter randomly produces fake money. However, the quality is low, and the police detect the fake bills. Importantly, like in real life, the imposter gets punished by the police when producing fake money. As a result, the imposter knows what went wrong and adjusts its methods until the money becomes very realistic. On the other hand, the police also get trained more in detecting fake money, competing against the imposter until the difference between fake and real money is relatively unclear. Then we could ask the imposter to generate new, synthetic money.
Synthetically generated relational data
Often, machine learnings models are built on relational data. Think about .csv files or database tables containing all relevant information to build an ML model. GANs enable companies to generate synthetic data, mimicking the original data without the privacy risks. All synthetically generated relational data is based on the original data but doesn’t contain any actual personal identifiable information.
For that reason, synthetically generated relational data is often used in publishing data that couldn’t be published when using the original data. An important example is synthetically generated patient records, which can be shared with fellow researchers without any privacy risk. That way, researchers can use similar patient records data with the same dynamics and are in compliance with privacy regulations.
Generate synthetic relational data using OCI Data Science
You can generate new, synthetic data based on an original data set in many ways. In the following section, this blog showcases two examples using a notebook session in Oracle Cloud Infrastructure (OCI) Data Science. In both examples, you can make the following decisions:
-
What’s the Excel file or database table you want to extend with synthetic data from?
-
How many new rows of synthetic data do you need?
-
What’s the unique ID of the data set?
Example 1: Generate synthetic relational data based on a .csv file
Example 1 assumes a .csv file has been stored in Object Storage. The notebook picks up the original .csv file, loads it, and uses CTGan to train. Automatically, a new .csv file is generated containing solely synthetically generated data. The .csv file is stored again in Object Storage.
Example 2: Generate synthetic relation data based on a database table
Example 2 assumes an existing database table. The notebook queries directly from the database table, loads it, and uses CTGan to train. Automatically, a new database table is generated containing solely synthetically generated data.
Both examples shown in the notebook are available on GitHub.
Automation in synthetic relational data generation
The previous examples are both run in the notebook. OCI Data Science enables you to easily deploy the entire script. That way, any application can trigger the following flow:
-
Upload an Excel file or select from a database table.
-
Determine the number of synthetic rows you want.
-
Train the CTGAN (or any other GAN) on the Excel file or database table.
-
Generate the synthetic relational data.
-
Output a new, synthetic Excel file or database table containing the synthetic relational data.
Conclusion
That’s all for this blog. Thanks for reading and stay tuned for more content! Want to experiment further? Try an Oracle Cloud free trial! A 30-day trial with US$300 in free credits gives you access to Oracle Cloud Infrastructure Data Science service.
Want to learn more? See the following resources:
-
Read the Data Science documentation.
-
Configure your OCI tenancy with these setup instructions and start using OCI Data Science.
-
Star and clone our new GitHub repo! We included notebook tutorials and code samples.
-
Subscribe to our Twitter feed.
-
Try one of our LiveLabs. Search for “data science.”
-
Join the AI and Data Science public Slack channel.
-
Contact us directly for preview access to new features.
