The OCI + WEKA Partnership
More organizations are choosing to run AI inference in their own environments to protect sensitive data, reduce long-term costs, avoid dependence on third-party APIs, and gain more control over model choice, uptime, and operations. But as they make that shift, early infrastructure choices can determine how much AI they can actually serve at scale.
Long-context and agentic AI workloads share a common bottleneck: unnecessary re-computation. When a system runs out of memory and evicts KV cache entries, it pays a prefill toll of wasted GPU cycles, higher latency, and lower throughput. Solving that at scale is what brought OCI and WEKA together.
In 2025, OCI and WEKA published a joint blog post showing that WEKA’s Augmented Memory Grid on OCI H100 infrastructure delivered nearly 20x faster time to first token (TTFT) at 128K context versus baseline vLLM. At SC25, WEKA announced the commercial availability of Augmented Memory Grid on NeuralMesh, with OCI as the exclusive launch partner through Oracle Cloud Marketplace.
This post is the next chapter: moving from early validation to production-relevant workload testing on OCI bare-metal H100s, and showing what this partnership can enable at scale.
What This Benchmark Effort Set Out to Accomplish
The first phase of OCI + WEKA testing proved that Augmented Memory Grid works. This phase was about proving what it enables. Specifically, our teams set out to:
- Validate at scale: Confirm Augmented Memory Grid sustains its advantage beyond synthetic TTFT tests and into production-like LLM serving behavior at cluster scale — 72 GPUs across 9 nodes.
- Test real inference economics: Measure how Augmented Memory Grid changes serving density and throughput when DRAM is no longer sufficient, specifically for long-context, cache-sensitive workloads on OCI infrastructure.
- Establish a reference architecture: Show that OCI bare-metal H100 infrastructure can support a validated, cost-efficient LLM serving architecture with Augmented Memory Grid.
- Go beyond steady-state: Test operationally important behaviors like cache persistence and SLO stability under high concurrency load — conditions that expose how systems behave when they’re pushed, not just warmed up.
System and Workload Details
Cluster configuration:
- 9-node OCI bare-metal H100 cluster, 8 GPUs per node — 72 GPUs total
- Multiple TP4 instances of MiniMax-M2.5-NVFP4
- 16x Gen4 NVMe drives per node (3.84 TiB each), pooled into a converged Augmented Memory Grid layer
- 287 TiB usable NVMe via Augmented Memory Grid vs. ~8.64 TiB available DRAM in the baseline
- 2x 200Gb RDMA NICs per node
Workload definition:
- Each simulated “user” = 100K-token input + 100-token response per turn
- Tests configured to maximize potential cache hit rate, isolating the effect of offloading vs. recompute
Comparison baselines:
- Baseline: HBM + DRAM only (standard vLLM serving)
- Augmented Memory Grid: HBM + NVMe only
- Augmented Memory Grid full stack: HBM + DRAM + NVMe
Results: Three Benchmarks That Matter
The results were clear across every dimension tested. Here are the three that tell our story most directly.
1. 10x More Concurrent Users
DRAM-only hit a hard ceiling at approximately 600 concurrent users. Augmented Memory Grid scaled past 5,000 in unbounded testing.
Augmented Memory Grid changes serving density at the GPU level. More users per GPU means your OCI bare-metal investment stretches further. The same cluster handles dramatically more demand without adding a single node.
When DRAM saturates, it’s not just that the system can’t take on more users. It starts failing the users it already has. Cache entries get evicted, TTFT climbs unpredictably, and SLOs slip. Users experience longer waits, and the variance makes it hard to maintain any consistent quality of service. Augmented Memory Grid avoids that cliff entirely: by offloading KV cache to NVMe over RDMA, it maintains cache hits as concurrency grows, keeping TTFT stable and SLOs intact even as load increases well beyond what DRAM can support.
2. 10x Higher Token Throughput
Augmented Memory Grid reached approximately 2 million tokens per second, versus under 200K per second for DRAM-only, a 10x gain in raw output.
In reality, this could mean that a product team running real-time AI features on OCI (search, summarization, or code assist) that was hitting throughput limits at 200K tokens per second now has 1.8 million more to work with. Same infrastructure, same OCI investment, but a fundamentally different ceiling.
3. 7x More Tokens Served
In the same test window, Augmented Memory Grid served 5 billion tokens versus 700 million for DRAM-only, a 7x increase in total volume. For organizations running agentic workflows on OCI, where each session can consume 500K to several million tokens, DRAM saturates quickly and recomputation quietly drains GPU capacity. Augmented Memory Grid changes that equation, allowing the same footprint that was capped at 700M tokens to now deliver 5 billion.
The chart below shows this in real time across a one-hour, 2,400-user test. At the inflection point where DRAM cache saturates, baseline response time climbs and stays volatile, while AMG stabilizes and the 7x gap in completed requests widens from there.
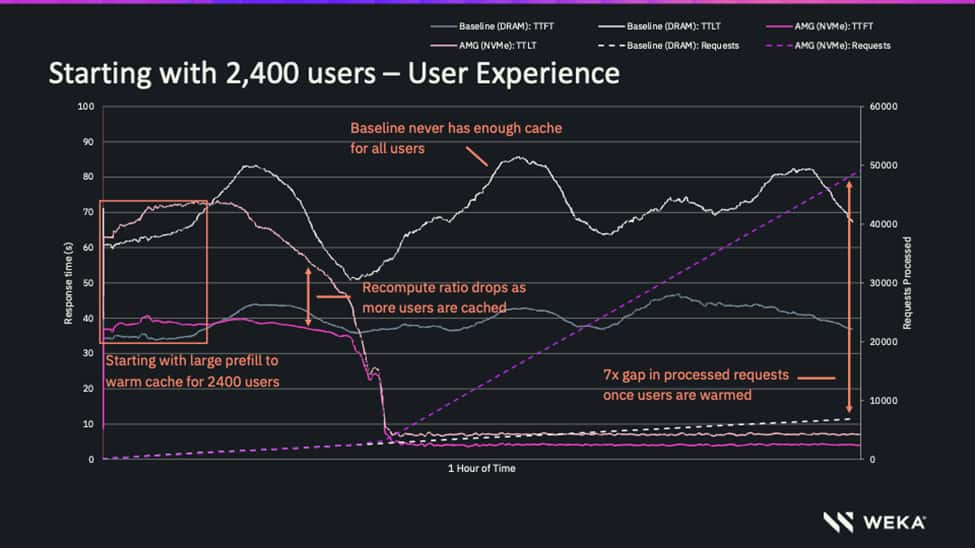
Why This Helps Stabilize SLOs
One of the most important lessons from the testing is that the performance gap between DRAM-only caching and Augmented Memory Grid does not appear gradually. It appears at the point where DRAM cache saturates.
Below that point, the systems can look similar. Above it, the DRAM-only configuration hits a wall. Cache misses increase, re-computation rises, throughput falls, and latency becomes harder to predict. Augmented Memory Grid keeps scaling because the active cache working set has a much larger place to live.
This is why Augmented Memory Grid is not just a throughput story. It is also an SLO story.
When a user’s session misses cache, the system has to rebuild context. For a short prompt, that may be acceptable. For a 100K-token input, a multi-turn coding session, or an agent workflow with a long project history, the user experiences that miss as a pause. At scale, those pauses become SLO risk.
By expanding the cache tier and improving persistence, Augmented Memory Grid reduces the conditions that lead to cache eviction and recomputation. That helps make performance more predictable under concurrency, especially for workloads where demand is bursty, context is large, and users expect interactive responsiveness.
Operational Lessons from the Field
The testing also reinforced several operational realities.
First, production inference is a full-stack problem. This work ran across Kubernetes, GDS, RDMA, vLLM, OCI bare-metal GPUs, and Augmented Memory Grid. The result depends not just on raw device performance, but on the full data path between cache, network, runtime, and GPU.
Second, cache capacity and cache movement both matter. Capacity alone is not enough if the system cannot retrieve KV cache fast enough to avoid stalling GPUs. Third, the operational value extends beyond a single request. By decoupling KV cache from local GPU memory and storing it in a high-performance token warehouse, Augmented Memory Grid can allow any host to serve a session with cache hits intact — reducing the need for rigid session stickiness, improving load balancing, and simplifying scaling.
Key Stats at a Glance
| Metric | DRAM Baseline | Augmented Memory Grid | Improvement |
| Max concurrent users | ~600 | 5,000+ | 10X |
| Requests completed, 2,400-user test | ~6,700 | 47,000+ | 7X |
| Tokens served | 700M | 5B | 7X |
| Token throughput | <200K tokens/sec | ~2M tokens/sec | 10X |
What This Means for OCI Customers
For OCI customers building long-context inference services, these results point toward a validated architecture for getting more from the same GPU infrastructure.
The value is broader than faster Time to First Token (TTFT). It includes more users per cluster, more tokens served per test window, higher throughput, better cache persistence, and more predictable behavior as concurrency increases. Those are the characteristics customers need as they move from experimentation to production-scale AI applications.
This is especially important for agentic AI. Agents depend on memory. They need to preserve project history, prior tool calls, documents, code, instructions, and intermediate reasoning across many turns. When that context is repeatedly evicted and recomputed, the infrastructure cost rises and the user experience degrades. When that context can persist and be reused efficiently, long-context AI becomes more practical to operate at scale.
Conclusion & Next Steps
OCI and WEKA have moved from early validation to production-scale proof points for long-context inference.
The first phase showed that Augmented Memory Grid could reduce TTFT by avoiding unnecessary prefill. This next phase shows the broader impact: higher concurrency, higher throughput, more tokens served, and more stable performance when DRAM-only caching reaches its limit.
With WEKA Augmented Memory Grid on NeuralMesh and OCI bare-metal H100 infrastructure, customers can extend KV cache beyond local memory, reduce recomputation, and serve more inference on the same GPU footprint.
To get started with Augmented Memory Grid on OCI, visit the Oracle Cloud Marketplace solution.
Blog co-authored with WEKA:

Anton Bykov, Senior Director of ProdOps – WEKA

Betsy Chernoff, AI/ML Product Marketing Lead – WEKA

