Large language models (LLMs) have become increasingly popular in recent years because of their impressive capabilities, which include language translation, natural language processing (NLP), and content generation. They have proven to be incredibly useful in a wide range of industries, including finance, healthcare, and education. These models use deep learning techniques to analyze vast amounts of text data, learning patterns, and structures in language that allow models to mimic human-like behavior. This analysis performs best on GPUs because of their ability to process those calculations quickly in parallel.
LLMs are continually improving as researchers develop more advanced algorithms and training methods, making them an exciting area of development in the field of artificial intelligence (AI). One of the major challenges of LLMs is that they require substantial amounts of memory to store the numerous parameters and intermediate results during inference. Managing this memory usage efficiently can be a daunting task, particularly when dealing with limited resources or large input sizes.
OCI Data Science model deployments
Oracle Cloud Infrastructure (OCI) Data Science is a fully managed service to deploy machine learning (ML) models as HTTP endpoints for serving requests for model predictions. It offers flexibility to either bring your own inference server or a service-managed inference server. Data Science also offers both CPU and GPU support various Compute shapes for inference. The service offers flexibility to deploy your own inference container. Learn more about the bring your own container (BYOC) feature of OCI Data Science.
Model deployments also support the deployment of NVIDIA Triton Inference Server, an open source inference serving software, also available with enterprise-grade security and support in the NVIDIA AI Enterprise software suite. This availability standardizes and delivers fast and scalable AI in production and streamlines the deployment of models, including LLMs, on both CPUs and GPUs, providing a fast and efficient inference experience.
As an example of an LLM, GPT-2 is a transformer-based model, capable of generating texts from an input text corpus. GPT-2 is compute-intensive. The smallest variant has 124 million parameters. The GPT-2 model pipeline takes text as input, and generates the most probable output token, as shown in the following diagram:
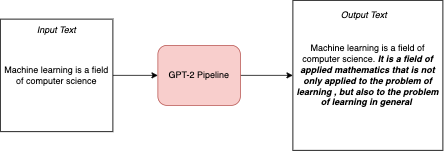
The GPT-2 model pipeline has the following components:
-
Encoder: Converts the user input text corpus to word embedding vectors
-
GPT2: The core unsupervised model that can generate the most probable output token from given word embedding vectors
-
Decoder: Converts the input plus the generated token embeddings to output text
In this blog post, we use NVIDIA Triton Inference Server to deploy a GPT-2 model in a Data Science model deployment using Triton’s capability of creating model pipeline as an ensemble.
Among the benefits of using NVIDIA Tritin Inference Server with OCI Data Science Model Deployment service are automatic detection of GPUs and optimization of the GPU infrastructure management, built in support for sharding and ensembles, which are building blocks of LLMs.
Deployment topology
Model deployments use the Triton’s model ensemble feature to break up components of a model pipeline and use different compute backends, on either CPU or GPU on any of various GPU shapes that OCI supports, including A10 and A100. In this example, we assign an encoder and decoder to run on CPU, and the GPT-2 model to run on GPU, as shown in the following deployment strategy:
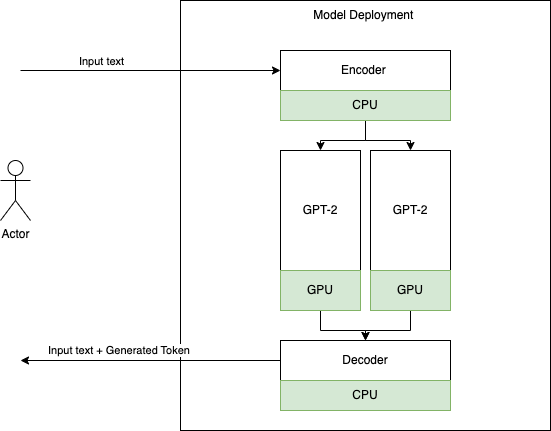
Deploy GPT-2 using the model deployment’s custom container feature, NVIDIA Triton, and NVIDIA GPUs
A usual workflow of deploying custom containers involves the following steps:
-
Prepare and register a model artifact.
-
Build a Triton image and push it to the OCI Container Registry (OCIR).
-
Deploy an image using a Data Science model deployment.
-
Generate tokens invoking predict endpoints.
For the step-by-step guide, see the AI samples GitHub repository.
We deployed an LLM GPT-2 on a GPU Compute shape using NVIDIA Triton Inference Server within the fully managed OCI Data Science service. The results are a flexible and scalable LLM that you can easily deploy in GPUs and use securely with OCI’s enterprise-grade services.
Conclusion
You can use this example as a reference to deploy other LLMs. We plan to publish more samples soon. Stay tuned!
Try Oracle Cloud Free Trial! A 30-day trial with US$300 in free credits gives you access to Oracle Cloud Infrastructure Data Science service. For more information, see the following resources:
-
Full sample including all files in OCI Data Science sample repository on GitHub.
-
Visit our service documentation.
-
Try one of our LiveLabs. Search for “data science.”

