GPU challenges the generative AI market
We have a supply-and-demand problem in the generative AI market for hardware availability across the world. Because most of the hardware needed for generative AI today is consumed by foundation model producers for large language model (LLM) training workloads, the mass market has limited access to capacity needed to evaluate and integrate LLMs to their business. The supply constraint is most notable for users who want to deploy LLMs within their own cloud tenancies and cloud subscriptions so they can have full control over data security and privacy.
For developers and data scientists looking to integrate the Generative AI technology in their existing business, they will need to first evaluate LLM models to see which models yield the best results to the business problem. Availability, cost, and right-sized compute are critical to getting started. For most self-hosted inference workloads, GPUs are often under-utilized which leads to idle capacity and higher cost. What are the alternative choices?
CPUs have been long used in the traditional AI and machine learning (ML) use cases. However, there aren’t many proof points for generative AI inference using ARM-based CPUs. We went through extensive evaluations and research to test popular open source LLM models like Llama 2, Mistral, and Orcas with Ampere Altra ARM-based CPUs. We chose Ampere A1 compute shapes that offer both virtual machine (VM) flexible shapes and bare metal options that are widely available across many regions. Ampere Altra ARM-based CPUs also has a competitive pricing and with a flex choice on the number of CPUs and memory that allowed us to run various open-source LLM models of different sizes to a CPU and memory combination.
By working with our partner, Ampere Computing, we evaluated different combinations of CPU cores and memory using optimized llama.cpp software stack on popular Llama & Mistral open-source models. Through continuous performance optimization, we achieved promising performance results balancing model latency for user request and server efficiency.
Performance methodology and results
Before we delve into our findings, let’s establish a baseline on what metrics are relevant when evaluating LLM inference performance on CPU and understand model type and quantization.
Traditionally, LLMs are trained and inferred on GPUs using full precision 32-bit or half precision 16-bit format for parameters and weights with model and weights stored separately. The combined size determines the amount of GPU memory needed to do the inference. However, in recent months, a convergence on the model file format called GGUF has occurred with compression techniques and quantization, changing the variable requirements needed to store model weights. By removing the dependency on FP32 and FP16, LLM models are suitable for CPU inference. While some model accuracy implications exist, the difference according to community perplexity standard tests are small. For more on perplexity scores, see quantization comparisons on GitHub. Our extensive validations are based on GGUF open-source models.
The following image is a simplified version of different phases inside the server handling inference requests. With higher memory available decode operations are efficient on CPU comparing to encode part.
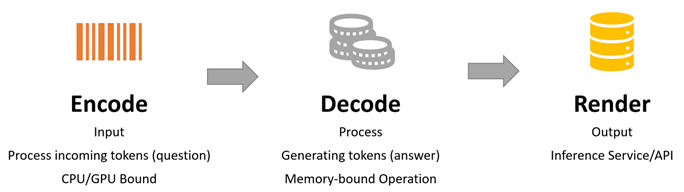
To better follow performance results, the following terms are important:
- Token per second (TPS): Number of token responses generated for the LLM inference request. This measurement includes Time to First Token and Inter Token Latency. Reported in # of tokens generated per second.
- Server-side throughput (TP): This metric quantifies the total number of tokens generated by the server across all simultaneous user requests. It provides an aggregate measure of server capacity and efficiency to serve requests across users. This metric is reported in terms of TPS.
- User-side inference speed (IS): This metric calculates the average token generation speed for individual user request. It reflects the server’s responsiveness to provide a service level of inference speed from the user’s perspective. This metric is reported in terms of TPS.
Use cases
Two main scenarios are common with LLM inference: online (chat bot and real time) and offline (batch analysis). There is a tradeoff between server throughput and inference speed when it comes to performance optimization. Though online scenario requires fast inference speed, we believe for some use cases the performance is satisfactory if the server can achieve a minimum 5 TPS per concurrent user request, also referred as service level objective (SLO). This number is calculated based on average human reading speed of 200–300 words per minute based on research. If the server generates faster token responses than 5 TPS, the end users will need time to catch up on responses leading surplus and higher price per token generated.
Performance results
We performed our validations and optimization using an improved version of the popular open-source project llama.cpp, which uses quantized LLM models. The results indicate that a single node Ampere A1 shape can process up to 16 concurrent user requests at 7.5 TPS per user (above the average human reading speed) for Llama 2 7B chat model while achieving maximum server throughput efficiency of 119 TP. In our experience hosting a Generative AI service, this TPScan be sufficient for self-hosted workloads like A/B testing, summarization, running embedded models for tokenization of data for LLM training, and batched inference use cases. See performance detail below:
| Model | Parameters/Spec | Throughout (TP) with Ampere + OCI improved llama.cpp | Inference Speed (IS) with Ampere + OCI improved llama.cpp | Analysis |
| llama-2-7b.Q4_K_M.gguf |
Input= 128 Output= 256 Batch Size= 1 | 33 TPS | 33 TPS | 30% faster that current upstream llama.cpp Batch size 1/Concurrency 1 TP and IS are the same |
| llama-2-7b.Q4_K_M.gguf |
Input= 128 Output= 256 Batch Size= 4 | 75 TPS | 19 TPS | 66% faster that current upstream llama.cpp 19 TPS per concurrent user |
| llama-2-7b.Q4_K_M.gguf |
Input= 128 Output= 256 Batch Size= 16 | 119 TPS | 7.5 TPS | 52% faster that current upstream llama.cpp 7.5 TPS per concurrent user. Much better than 5 TPS minimum. Most cost to performance optimized results that maximizes server utilization, also still delivering service level objective. |
| mixtral-8x7b-instruct-v0.1.Q4_K_M.gguf |
Input= 128 Output= 128 Batch Size= 1 | 19 TPS | 19 TPS | 8x7B = 56B parameter model inference with 19 TPS. Ideal for large model evaluations. |
Run specification: Ampere A1 Flex 64 OCPU, 512 GB, 4K_M quantized models, US Ashburn Location, Default LLM model parameter values. Llama.cpp uptream build number f020792
An offer and simple onboarding from Oracle to get you started
To help you try this inference example on Ampere across all OCI supported regions, we will be releasing a single-node Ampere Oracle Cloud Marketplace offering that deploys a Serge container with a llama.cpp packaged server and basic frontend and API interface in the coming weeks. As we continue working to further improve inference performance on Ampere, we’re offering one free VM A1 Flex Shape (64 OCPU and 360 GB memory) for three months to customers who sign up before December 31, 2024. The capacity is sufficient to perform one LLM model evaluation. We look forward to learning more about your needs, experiences, and use cases during this evaluation phase. To get started, fill out this sign-up form.
Next steps
Oracle Cloud Infrastructure and our partners like Ampere Computing plan to continue working with open-source communities to improve CPU performance for LLM inference and other workloads such as model fine-tuning and embeddings . Furthermore, we plan to add more developer-friendly capabilities to help you integrate with current ML toolchain and enable independent software vendor (ISV) partners to provide at scale deployment and management in the coming months.
The future of generative AI and the profound impact it can have on everyone is limitless. Sign up to receive one free VM A1 Flex Shape (with 64 OCPU and 360-GB memory) for three months to try optimized LLM inference in your Oracle Cloud Infrastructure (OCI) tenancy.
