Large language models (LLMs) have captivated global attention since the emergence of ChatGPT, marking substantial advancements in GPT-like generative models and moderate yet continuous progress in bidirectional encoder representations from transformers (BERT)-like discriminative models. As 2024 unfolds, we’ve witnessed significant strides in the domain of large representation models, also known as embedding models, which stand at the confluence of discriminative and generative models in the vanguard of generative AI.
While much of the industry’s focus has centered on the generative aspect, especially in applications like retrieval-augmented generation (RAG), our work with the OCI Generative AI service underscores a pivotal yet often underappreciated component: the quality of retrieval. As practitioners implementing RAG for real-world challenges, we’ve observed that without high-quality retrieval, the generative step lacks the necessary knowledge to deliver optimal outcomes. This realization has driven us to pioneer the industry-first initiative to extend cutting-edge serving solutions from large generative models to large embedding models, addressing a crucial bottleneck and advancing the field in a less-celebrated yet vital domain.
The emergence of large embedding models
Since “Attention is All You Need” was published in 2017, embedding models based on BERT-like architectures have revolutionized various areas, such as information retrieval and recommender systems, and become a key component in the latest retrieval-augmented generation. These successes underscore the symbiosis between generative and discriminative models, highlighting the importance of embedding quality in RAG applications. The advent of the E5 model in 2024, a large embedding model that uses a fine-tuned Mistral-7B enriched with diverse, high-quality synthetic data, has spotlighted the scalability and nuanced improvements large embedding models bring to the table.
Dominating the Massive Text Embedding Benchmark (MTEB) leaderboard, these embedding models with 7B to 47B parameters as of today aren’t just substantially larger than their predecessors but also foundational to enhancing the retrieval phase in RAG, enabling generative models to achieve their full potential. Our commitment to advancing large embedding model serving is rooted in this broader understanding of AI’s ecosystem, where enhancing the underexplored facets like retrieval is as crucial as advancing the celebrated generative capabilities.
Pioneering large embedding model serving
A popular solution for serving BERT-sized deep learning models, ONNX has recently been upgraded to accommodate large embedding models. However, the efficiency was not as expected during our initial evaluations. Other solutions, such as Hugging Face’s text embedding interface (TEI) repository and the Infinity project, have made strides toward serving embedding models but remain focused on BERT-sized models, leaving a gap for larger embeddings that we have now filled. We’ve also observed that, despite being on their roadmap, cutting-edge LLM serving solutions, including DeepSpeed MII, TensorRT-LLM, TGI, and vLLM haven’t systematically support the serving of large embedding models.
Among one of industry firsts, our team has devoted efforts to build a serving solution capable of supporting large embedding models, incorporating state-of-the-art technologies in large model-serving, such as dynamic batching, Flash Attention and Flash Infer, and tensor parallelism. Instead of reinventing the wheel, we followed industry best practices to build our solution on top of an open source solution, vLLM, using its cutting-edge serving technologies and production-level quality. Our solution not only generates embeddings through the Flash Attention and tensor parallelism built in vLLM, but also provides a support of OpenAI-compatible embedding API.
We have analyzed the differences between embedding and generative model serving and make several unique contributions. For embedding models, we improved the dynamic batching algorithm with a self-adaptive sliding window mechanism to allow for larger dynamic batch sizes, while keeping the latency overhead within a moderate threshold. We isolated the KV cache and CUDA graph, which are necessary only for generative models, optimizing GPU memory for batched embedding generations. Furthermore, we develop automatic profiling to tune the best configuration for request scheduling across different hardware settings.
Our enhancements have demonstrated remarkable performance advantages, significantly outpacing the latest ONNX updates for large models. For example, our serving of the E5 model with 7B parameters on 1 GPU (A100 or H100) shows a speedup of 1.2 times, with a batch size one, to over three times for larger batch sizes, compared to the latest ONNX. This advancement underscores our team’s pioneering role in enhancing the generative AI ecosystem, helping to address practical challenges with innovative solutions that establish new industry standards.
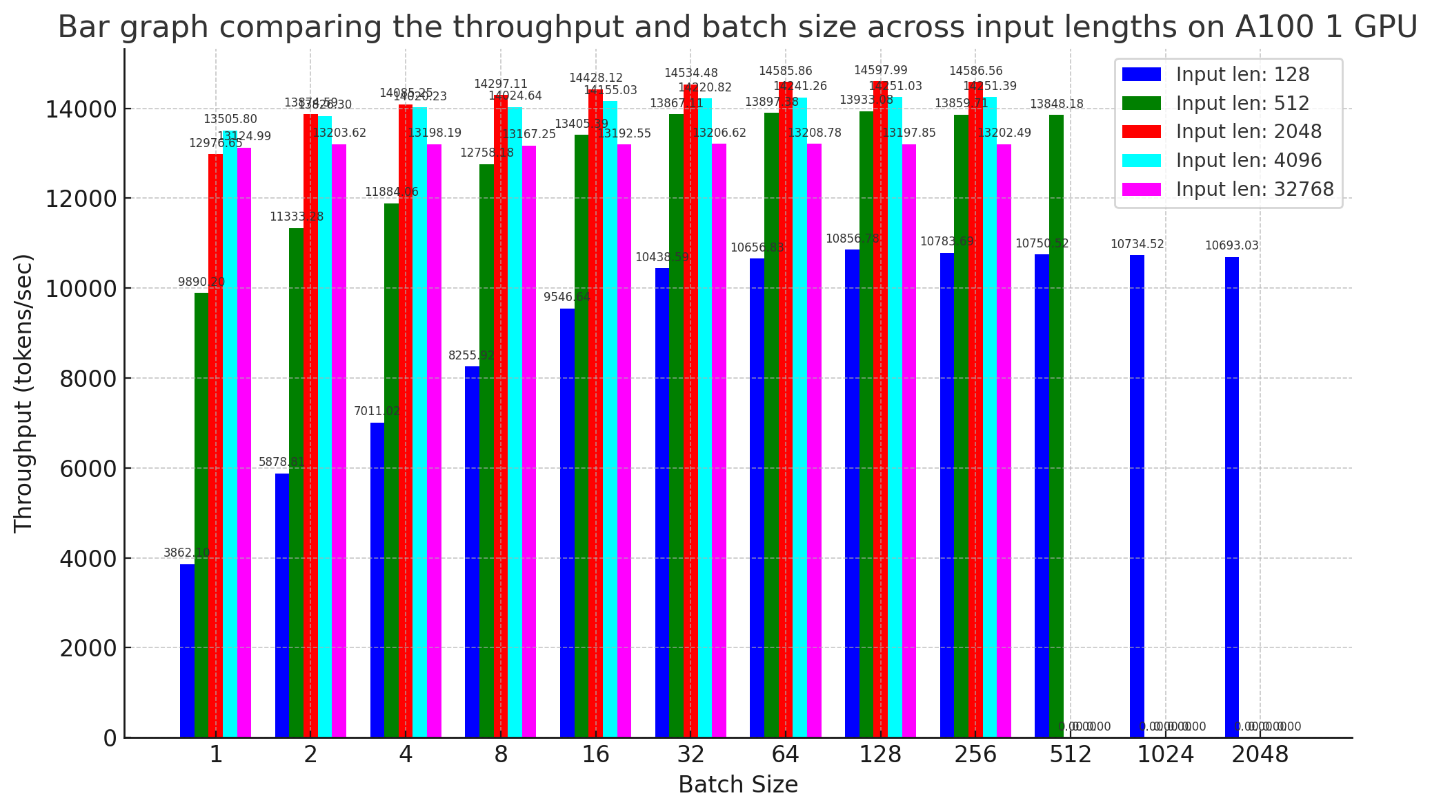
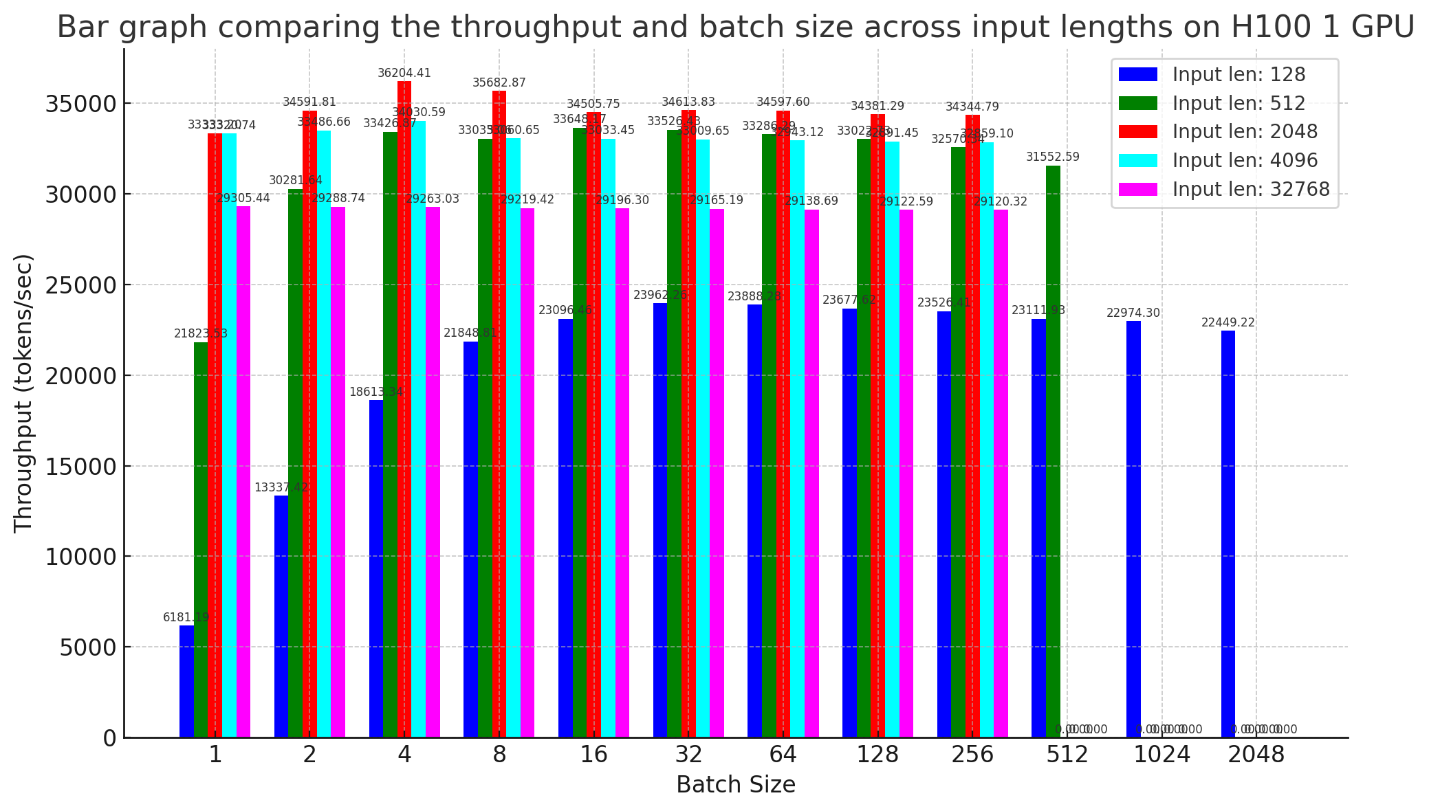
Refining the field
As we continue to navigate the complexities of large embedding models, we aim to contribute further and grow with the community and the broader field of generative AI. With a collaborative spirit, we have already upstreamed our developments to the vLLM community as part of our commitment to open source innovation. Our contributions are about more than pushing technological boundaries. They help make these technologies accessible, scalable, and, most importantly, applicable in real-world scenarios.
Conclusion
Our journey in advancing the serving of large models underscores the importance of addressing both the celebrated and the underexplored aspects of AI and anticipates the needs of future AI applications. Focusing on efficient serving for both generation and embedding models also lays the groundwork for innovations like multimodal models, where high-quality embeddings are crucial for integrating diverse data types.
Our contribution to enhancing large embedding model serving is a testament to our dedication to the AI community’s evolution. We’re excited about the potential of these models to drive the next wave of generative technologies, marking our continued effort towards transformative AI solutions. We invite you to experience the cutting-edge advancements we’ve made in large embedding model serving. Whether you’re implementing RAG in your projects or exploring new possibilities with AI, our innovations are designed to deliver high-performance solutions. Explore our open source contributions and see how our developments can enhance your AI workflows.


