Enterprises today are fast moving beyond proof-of-concepts — they want to embed AI deeply into their core applications. But delivering real-world, production-grade AI isn’t just about choosing the right model or infrastructure: it’s about building a resilient, scalable, and maintainable application architecture that supports diverse workloads, from web front-ends to GPU-accelerated AI inference, while meeting enterprise requirements for reliability, cost efficiency, and compliance.
That’s where OKE shines. By combining serverless-style virtual nodes for web applications with GPU-powered managed nodes for AI inference — all inside a single Kubernetes cluster — OKE offers a unified, container-native platform where both stateless front-ends and stateful AI workloads coexist seamlessly.
In the architecture we describe below, the front-end uses serverless Kubernetes to autoscale with demand, while backend AI workloads run on dedicated GPU nodes for predictable performance. A persistent data layer (powered by Oracle Autonomous AI Database) stores user interactions, context, and model memory — enabling advanced, personalized, and compliant AI experiences.
Whether you’re modernizing legacy systems or launching new AI-driven applications, this architecture shows how to deliver full-stack, high-availability AI applications — leveraging the elasticity, portability, and operational simplicity of Kubernetes, together with GPU acceleration and enterprise-grade data services.
Let’s explore how this design brings together serverless web, GPU inference, and persistent data into a robust architecture for intelligent applications.
For readers interested in the infrastructure and GPU high-availability foundation that complements this application-level design, see the companion article “Designing High-Availability AI Apps with GPU Infrastructure” published on the Oracle AI & Data Science blog.
Application Architecture Perspective
While the infrastructure layer establishes a scalable and resilient foundation, the application architecture deployed on Oracle Kubernetes Engine (OKE) completes the solution by enabling intelligent, container-native workloads capable of supporting demanding enterprise use cases across healthcare, financial services, retail, telecom, and more.
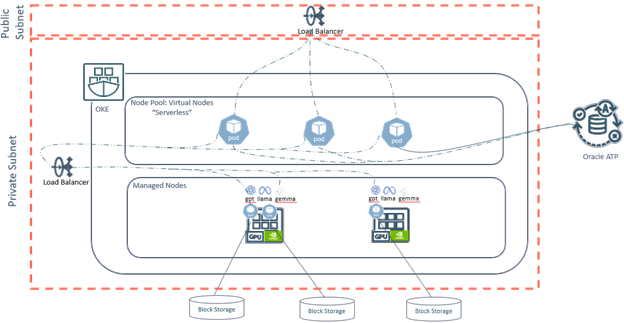
This end-to-end architecture was deployed entirely inside an OKE cluster, organized into two specialized node pools:
- Front-End Node Pool (Virtual Nodes / Serverless Kubernetes) Optimized for web applications, scaling instantly and automatically without managing nodes.
- Backend Node Pool (GPU Managed Nodes for AI Inference) Dedicated to running AI models, providing predictable performance with local GPU acceleration.
This layout brings together the best of serverless elasticity and GPU-optimized stateful AI workloads inside a unified Kubernetes platform.
Benefits of Using OKE for Containerized Application
By unifying the application stack inside OKE, the solution gains key advantages:
- Flexibility: Run heterogeneous workloads (serverless, GPU, AI, databases, microservices) in one cluster.
- Elasticity & Autoscaling: Virtual nodes and managed node autoscaling enable dynamic scaling based on traffic and AI computational needs.
- Portability: Applications and models remain cloud-agnostic and Kubernetes-native.
- High Availability: Multi-node pools, internal/external load balancers, and ATP serverless ensure reliable, fault-tolerant deployments.
- Optimal Resource Usage: GPU workloads run only in dedicated nodes, while front-end uses serverless nodes to minimize cost.
This hybrid K8s pattern is especially relevant for enterprises modernizing legacy systems or introducing intelligent workflows into existing applications.
Backend: AI Model Serving on GPU Managed Nodes
To achieve a local AI application architecture with high availability, the backend was deployed as a stateful AI service. Key configurations included:
- StorageClass: Defines storage parameters for GPU nodes, throughput, replication, and performance.
- PersistentVolumeClaim (PVC): Ensures the AI models workloads have durable storage attached to each pod.
Statefull for AI Pods
Using StatefulSet instead of Deployment allowed the backend to:
- Pin AI workloads to specific GPU-managed node pools.
- Maintain a dedicated PVC per AI pod, ensuring persistence and isolation.
- Host different AI models like Gemma, GPT, and LLaMA.
Users can dynamically switch models depending on: the use case, desired model behavior, accuracy requirements, or latency/size tradeoffs.
- Each pod operates as an independent AI inference endpoint with its own persistent storage and model files.
- This architecture enables many users to connect simultaneously by balancing traffic across independent GPU-backed pods for reliable, scalable AI performance.
Internal Private Load Balancer
A Private Flexible Load Balancer was deployed in a private subnet, ensuring:
- Secure communication between the frontend and backend.
- No exposure of the AI engines to the public internet.
- Compliance with healthcare, financial services, and other regulated industries.
Front-End: Serverless Web Application on OKE Virtual Nodes
The frontend application was deployed to OKE Virtual Nodes, providing a fully serverless Kubernetes experience:
Application Characteristics:
Operates as an interface with the ability to:
- Query different AI models hosted in the backend.
- Switch models instantly depending on the user or use case.
- Store interactions in Oracle Autonomous AI Database for long-term personalization and model memory.
Advantages of Virtual Nodes:
- Zero need to manage VM infrastructure.
- Instant autoscaling based on user demand.
- Perfect for web, APIs, and event-driven logic.
- Seamless integration with private services via VCN.
Public Load Balancer
A Public Load Balancer exposes the frontend securely to business users, enabling global high-availability access.
Persistent Data Layer: Oracle Autonomous AI Database
A critical part of the architecture is the persistent history of interactions.
For the solution integrates Oracle Autonomous AI Database, which stores:
- User-specific conversations
- Prompt history
- Assistant responses
This database plays a key role in:
- Auditing and compliance for regulated industries.
- Improving AI quality through contextual memory.
- Providing cross-session continuity for users.
- Enabling AI-driven personalization and insights.
Oracle Autonomous AI Database auto-scaling, automated patching, and resilience further support the HA/DR application model.
End to End Value of This Architecture
By integrating front-end, backend AI, and persistent data inside OKE, the architecture delivers:
- Seamless orchestration of serverless Kubernetes, GPU AI workloads, and transactional databases.
- Support for highly regulated industries through isolation, private routing, and HA patterns.
- Future growth opportunities such as: Agentic AI orchestration, RAG implementations using Oracle Autonomous AI Database or Object Storage, Streaming integration with OCI Streaming / Kafka or Full enterprise CI/CD with OCI DevOps
This architecture demonstrates how organizations can deploy modern AI applications with backend intelligence and scalable frontend delivery—fully powered by Oracle Kubernetes Engine and GPU Compute Capabilities.

