In the rapidly evolving field of Large language models, deploying large-scale language models effectively is crucial for harnessing their full potential. One such is the Falcon 7b model, with its extensive capabilities in natural language processing and representing a significant step forward. The Falcon 7b is a 7-billion-parameter foundational Large Language Model (LLM) that was trained on 1500 billion tokens using TII’s RefinedWeb dataset. This represents the longest single-epoch pre-training for an open model. Leveraging the power of NVIDIA’s Triton Inference Server, we can deploy Falcon 7b on the Oracle Cloud Data Science platform, providing a seamless and scalable solution for businesses. This deployment strategy not only ensures the high-speed inferencing provided by Triton but also capitalizes on the robust and secure cloud infrastructure offered by OCI, setting a new standard for AI deployments in the cloud. By integrating these technologies, organizations can unlock new insights, automate complex tasks, and deliver enhanced data-driven services at an unprecedented scale.
Boosting Inference Speed with TensorRT for Large Language Models
The TensorRT-LLM open-source library accelerates inference performance of the latest LLMs on NVIDIA GPUs. It is used as the optimization backbone for LLM inference in NVIDIA NeMo, an end-to-end framework to build, customize, and deploy generative AI applications into production. NeMo provides complete containers, including TensorRT-LLM and NVIDIA Triton, for generative AI deployments. Highlights of TensorRT-LLM include the following:
- Support for LLMs such as Llama 1 and 2, ChatGLM, Falcon, MPT, Baichuan, and Starcoder
- In-flight batching and paged attention
- Multi-GPU multi-node (MGMN) inference
- NVIDIA Hopper transformer engine with FP8
- Support for NVIDIA Ampere architecture, NVIDIA Ada Lovelace architecture, and NVIDIA Hopper GPUs
- Native Windows support (beta)
In this blog, we aim to demonstrate how developers can tackle issues tied to performance during large language model (LLM) inference. Previously, they needed to reprogram and partition the AI model manually, managing its operation across various GPUs. TensorRT-LLM leverages tensor parallelism—a form of model parallelism where individual weight matrices are distributed over multiple devices. This facilitates efficient, large-scale inference with models operating simultaneously over numerous GPUs linked by NVLink and across different servers, all without the need for developers to step in or modify the model. As novel models and architectures emerge, TensorRT-LLM allows for the optimization of these models using the latest NVIDIA AI kernels, which are openly accessible in TensorRT-LLM. The advanced kernel fusions it supports include state-of-the-art versions of FlashAttention and masked multi-head attention for both the context and generation stages of GPT model processing, among others
High level Architecture
The following high level architecture depicts each step for deploying Falcon-7B. The goal of TensorRT-LLM backend is to let you serve TensorRT-LLM models with Triton Inference Server. The inflight_batcher_llm directory contains the C++ implementation of the backend supporting inflight batching, paged attention and more.
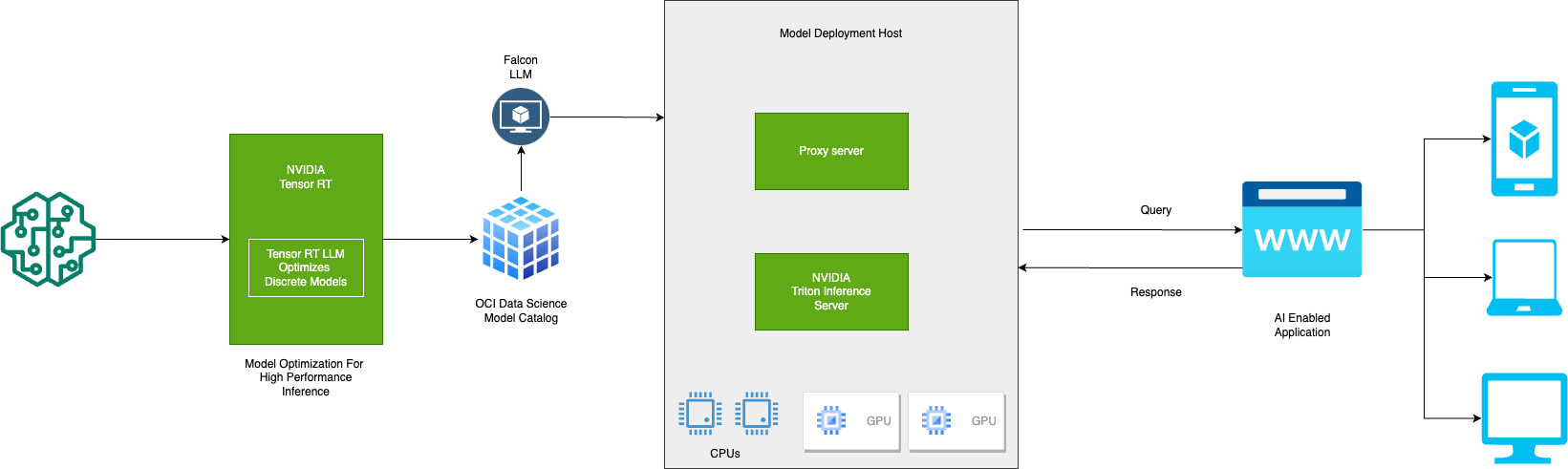
Source: https://developer.nvidia.com/ai-inference-software
Getting Started
Falcon 7b offers two variants:
- Falcon 7B (link – https://huggingface.co/tiiuae/falcon-7b)
- Falcon 7B Instruct (link – https://huggingface.co/tiiuae/falcon-7b-instruct)
Falcon-7B is a 7B parameters causal decoder-only model. in this blog we would be using falcon-7b based model as its useful to fine tune your own data. For the step-by-step walkthrough of the process, see the AI samples GitHub repository
Deep Dive
Start by building a docker image which contain the tool chain required convert a huggingface hosted model into tensorRT-llm compatible artifact, We can also use the same docker image for deploying the model for evaluation:
Step 1 – Build the base image
git clone https://github.com/triton-inference-server/tensorrtllm_backend.git cd tensorrtllm_backend/ git submodule update --init —recursive DOCKER_BUILDKIT=1 docker build -t triton_trt_llm -f dockerfile/Dockerfile.trt_llm_backend . |
Step 2 – Downloading and Retrieving the model weights
To utilize TensorRT-LLM, a dedicated library for inferencing large language models, one must provide a trained model’s weights. These can originate from your own models trained using a framework such as NVIDIA NeMo, or you can acquire pretrained weights from sources like the HuggingFace Hub.
git lfs install git clone https://huggingface.co/tiiuae/falcon-7b-instruct |
Note:Usage of this model is subject to a particular license and acceptable usage policy. To download the necessary files, agree to the terms and authenticate with Hugging Face.
Step 3 – Compiling the Model
The subsequent phase involves converting the model into a TensorRT engine. This requires having both the model weights and a model definition crafted using the TensorRT-LLM Python API. Within the TensorRT-LLM repository, there is an extensive selection of pre-established model structures. For the purpose of this blog, we’ll employ the provided Falcon model definition rather than creating a custom one. This serves as a basic illustration of some optimizations that TensorRT-LLM offers.
Run the container image and enter into container command prompt:
# -v /falcon-7B/:/model:Z , This statement mounts the downloaded model directory into tooling container docker run --gpus=all --shm-size=1g -v /falcon-7B/:/model:Z -it triton_trt_llm bash # Inside the container , Run following command export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-12.2/compat/lib.real/ |
Apply Quantisation and TensorRT-LLM conversion
# Run following commands in container prompt
cd tensorrt_llm/examples/falcon/
# Install model specific dependencies
pip install -r requirements.txt
# Apply quantisation
python quantize.py --model_dir /model \
--dtype float16 \
--qformat fp8 \
--export_path quantized_fp8 \
--calib_size 16
# Apply TensorRT-LLM Conversion
# Build Falcon 7b TP=2 using HF checkpoint + PTQ scaling factors from the single-rank checkpoint
python build.py --model_dir /model \
--dtype bfloat16 \
--use_gemm_plugin bfloat16 \
--remove_input_padding \
--use_gpt_attention_plugin bfloat16 \
--enable_context_fmha \
--output_dir falcon/7b/trt_engines/bf16/2-gpu/ \
--world_size 2
# --tp_size 2 Indicates, Tensor parallelism 2
# --output_dir falcon/7b/trt_engines/bf16/2-gpu/ Indicates that converted model artifacts will be placed in this location. |
When utilizing the TensorRT-LLM API to craft your model’s blueprint, you’re essentially piecing together a sequence of operations using NVIDIA TensorRT’s building blocks to construct your neural network’s architecture. These operations are aligned with specific kernels, which are pre-established GPU programs.The TensorRT compiler methodically traverses the operational graph to select optimal kernels for each function relative to the GPU at hand. Importantly, it has the capability to detect sequences within the graph where it’s beneficial to amalgamate several operations into a single kernel execution. This fusion minimizes the amount of memory transactions and the overhead associated with initiating numerous GPU kernels. Furthermore, TensorRT can consolidate the entire operations graph into a unified CUDA Graph, which can be executed in one action, thereby diminishing the overhead of kernel launches even further. While the TensorRT compiler excels at merging layers and boosting processing velocity, certain complex fusions, such as FlashAttention which intertwines various operations, are not automatically recognizable. For these scenarios, you can proactively substitute segments of the graph with plugins during the compilation phase. In this case, the script integrates the gpt_attention plugin that emulates a FlashAttention-like fused attention mechanism, along with the gemm plugin for conducting matrix multiplications with FP32 accumulation. The script also specifies FP16 as the desired precision for the entire model, consistent with the precision of the weights obtained from HuggingFace.
Upon completion of the script, the examples/falcon/out directory contains several key outputs:
- falcon_float16_tp1_rank0.engine: This is the primary output from the build script, encapsulating the executable operations graph with the embedded model weights.
- config.json: This file contains comprehensive details about the falcon model, including its structural design and precision level, along with data on the integrated plugins.
- model.cache: This file stores certain timing and optimization details from the model’s compilation to expedite future builds.
Prepare Triton Compatible TensorRT-LLM ensemble Model Artifact for Falcon-7B
model_repository | +-- ensemble | +-- config.pbtxt +-- 1 +-- postprocessing | +-- config.pbtxt +-- 1 | +-- model.py +-- preprocessing | +-- config.pbtxt +-- 1 | +-- model.py +-- tensorrt_llm | +-- config.pbtxt +-- 1 | +-- model.py +-- falcon_float16_tp1_rank0.engine +-- model.cache +-- config.json +-- falcon-7b. |
Note – falcon-7b inside tensorrt_llm/1 is a folder which will have tokenizer files from actual model Falcon 7B.
Deploying the Inference Server
Using Python SDK, with below sample payload to create Model deployment with TensorRT BYOC image. Public documentation for Triton model deployment can be referred here.
|
# create a model configuration details object
model_config_details = ModelConfigurationDetails(
model_id=<model_id>,
bandwidth_mbps=<bandwidth_mbps>,
instance_configuration=<instance_configuration>,
scaling_policy=<scaling_policy>
)
# create the container environment configuration
environment_config_details = OcirModelDeploymentEnvironmentConfigurationDetails(
environment_configuration_type="OCIR_CONTAINER",
environment_variables={
'STORAGE_SIZE_IN_GB': '500',
'MODEL_DEPLOY_PREDICT_ENDPOINT': '/v2/models/ensemble/versions/1/generate',
'MODEL_DEPLOY_HEALTH_ENDPOINT': '/v2/health/ready'
},
image="iad.ocir.io/ociodscdev/triton-tensorrt:1.1.1",
image_digest="sha256:243590ea099af4019b6afc104b8a70b9552f0b001b37d0442f8b5a399244681c",
cmd=[
"tritonserver",
"--model-repository=/opt/ds/model/deployed_model/model_repository",
"--http-port=9000"
],
server_port=8000,
health_check_port=8000
)
# create a model type deployment
single_model_deployment_config_details = data_science.models.SingleModelDeploymentConfigurationDetails(
deployment_type="SINGLE_MODEL",
model_configuration_details=model_config_details,
environment_configuration_details=environment_config_details
)
# set up parameters required to create a new model deployment.
create_model_deployment_details = CreateModelDeploymentDetails(
display_name=<deployment_name>,
model_deployment_configuration_details=single_model_deployment_config_details,
compartment_id=<compartment_id>,
project_id=<project_id>
)
|
Performance Comparison
To facilitate a comparative analysis, we utilized a VM.GPU.A10.2. Compute shape on a Falcon 7B model. This setup allowed us to discern the distinct differences in functionality and performance optimization among the Text Generation Interface (TGI), NVIDIA’s Triton Inference Server, and TensorRT for LLMs. Primarily tailored for text generation, TGI offers an intuitive interface and excels in generating coherent and context-relevant text. However, its performance optimization might not be as robust in high-throughput scenarios as its counterparts.
In contrast, NVIDIA’s Triton is a versatile inference server, supporting a range of frameworks, designed for high-performance machine learning (ML) inference in production environments. It’s adept at managing multiple models and maximizing GPU efficiency, though it might not specialize as much in text generation as TGI. TensorRT for LLMs, specifically engineered for large language models, stands out in boosting inference performance. It optimizes neural network models for NVIDIA GPUs, resulting in faster processing and lower latency, which is especially beneficial for intricate LLM tasks. In our benchmarking tests on the Falcon 7B model, TGI demonstrated its strengths in ease of use and tailored text outputs, but TensorRT surpassed the other frameworks in throughput, latency, and resource efficiency, establishing itself as the most optimized solution for LLMs in terms of speed and performance.
The following table shows the response times for different LLM frameworks:
| Tokens | Response Time In Seconds | ||
| TensorRT | vLLM | TGI | |
| 25 | 0.78 | 0.80 | 0.82 |
| 50 | 1.57 | 1.61 | 1.65 |
| 100 | 3.14 | 3.21 | 3.28 |
| 200 | 6.26 | 6.58 | NA |
| 500 | 15.64 | 16.55 | NA |
| 1000 | 31.41 | 33.16 | NA |
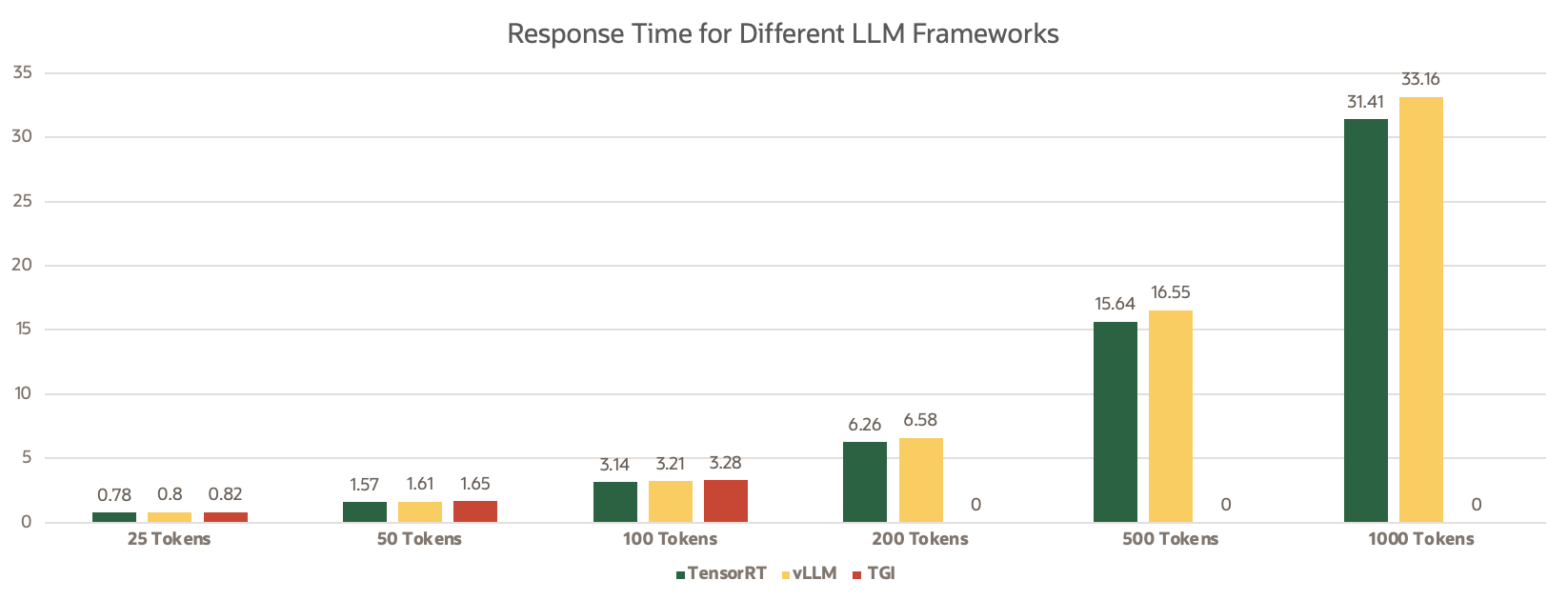
Note: During the benchmarking process, it was observed that the TGI framework did not generate responses for token sizes exceeding 150 tokens, leading to the exclusion of these cases beyond this threshold
As we can see from the above graphs, that TensorRT LLM provides the fastest response among for 25 tokens, 50 tokens, and for 100 tokens. Similarly when we compared against memory utilization, triton LLM provides the most optimized memory utilization with about 15.9GB utilized for Falcon 7B model where as TGI used about 21.1GB out of 23GB and vLLM utilizing about 20GB out of 23GB respectively.

Conclusion
In conclusion, deploying the Falcon 7B large language model using OCI Data Science and NVIDIA Triton with TensorRT-LLM inference server represents a cutting-edge approach to harnessing the power of AI. The OCI Data Science platform provides a robust, scalable cloud environment that complements the high-performance computing capabilities of NVIDIA Triton. This combination ensures that the Falcon 7B model is not only deployed efficiently but also runs with optimized inference capabilities, thanks to TensorRT-LLM’s advanced optimizations.
Together, these tools offer a seamless pipeline from deployment to deployment, enabling businesses to integrate sophisticated language processing into their services and unlock new opportunities in AI-driven analytics and customer engagement. By applying the strengths of OCI Data Science for resource management and NVIDIA’s Triton for performance, enterprise organizations and data scientists can deploy Falcon 7B at scale, making the most of their AI investments to drive innovation and growth.
Acknowledgements
We would like to extend our heartfelt gratitude to Richard Wang Cloud – AI/ML Solutions Architect and Ikroop Dhillon – Director, Developer Relations – Data Science, Cloud, Enterprise Database, AI from NVIDIA for their invaluable support in the creation of this blog post. NVIDIA’s expertise and guidance have been instrumental in navigating the complexities of this advanced deployment. Their team provided detailed insights and practical advice, particularly in optimizing the model’s performance using NVIDIA’s cutting-edge hardware and software solutions. Their willingness to share knowledge and provide hands-on assistance greatly enhanced the accuracy and depth of the content. This collaboration not only made the technical aspects more accessible but also illuminated the potential of Falcon 7B LLM when leveraged with NVIDIA’s powerful technology. Their support underscores NVIDIA’s commitment to fostering a collaborative and innovative tech community.
[Update from 4/18] OCI Data Science released AI Quick Actions, a no-code solution to fine-tune, deploy, and evaluate popular Large Language Models. You can open a notebook session to try it out. This blog post guides you on how to work with LLMs via code, for optimal customization and flexibility.
Try Oracle Cloud Free Trial! A 30-day trial with US$300 in free credits gives you access to Oracle Cloud Infrastructure Data Science service. For more information, see the following resources:
- Full sample, including all files in OCI Data Science sample repository on GitHub.
- Visit our service documentation.
- Watch our tutorials on our YouTube playlist.
- Try one of our LiveLabs. Search for “data science.”
- Got questions? Reach out to us at ask-oci-data-science_grp@oracle.com




