Establish Multi Cloud Connectivity with OCI Cloud
With the rapid growing popularity of OCI Cloud, many customer’s wants to migrate to OCI or use OCI as their multi cloud solution. Likewise, many Customers want to access other Cloud Data platforms from OCI and use OCI as the their processing/computing solutions when dealing with Big Data solution.
This Blog will demonstrate how to connect GCP BigQuery from OCI DataFlow Spark Notebook. Following that will perform some read operation on BigQuery Table using Spark & write down the resultant Spark dataframe to OCI Object Storage & also on Autonomous DataWarehouse.
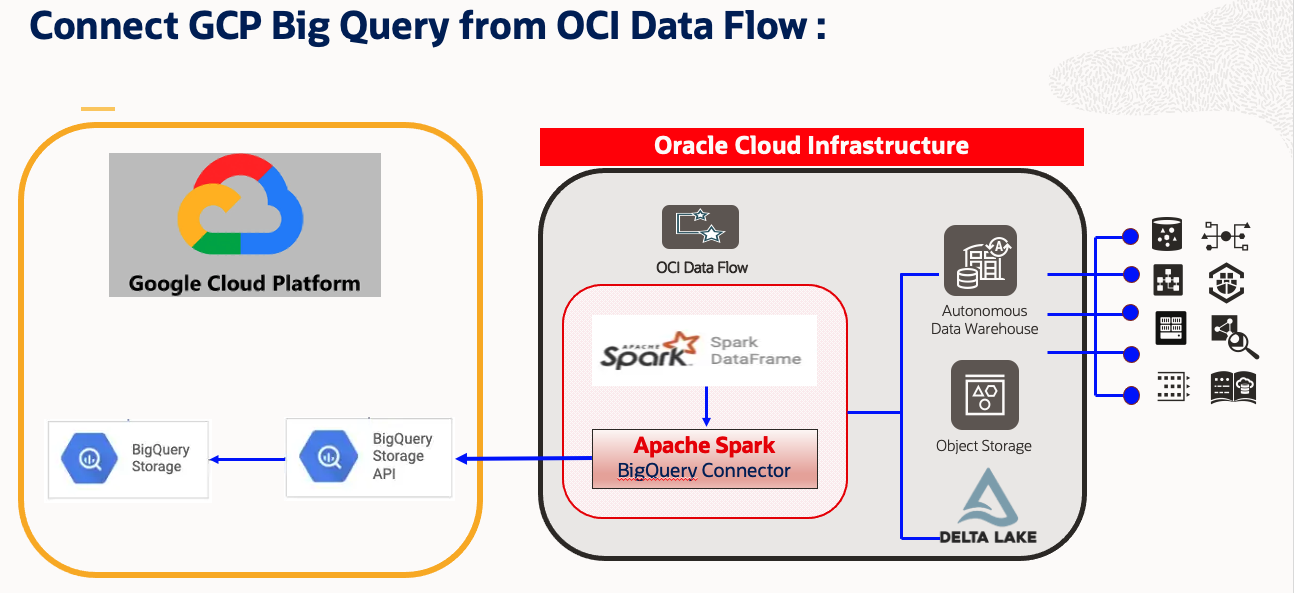
This solution will leverage Apache Spark capability like parallel processing and distributed in memory computation. OCI Data Flow application also can be scheduled/orchestrated through OCI Data Integration Service. In this approach, user can develop their Spark Script on OCI Data Flow & Interactive Notebook which itself leverages OCI Data Flow Spark cluster.
Highlights:
- Connect with GCP Platform : GCP BigQuery using Apache Spark BigQuery Connector:
- Develop complete ETL Solution :
- Extract Data from BigQuery.
- Transform the data using Apache Spark Cluster on OCI Data Flow.
- Ingest data in OCI Object Storage or Autonomous Data Warehouse.
- Use Developer’s friendly Interactive Spark Notebook.
- Integrate any supported open source spark packages.
- Orchestrate your Script using OCI Data Integration Service.
Before you begin, please refer Prerequisites steps:
1. Assuming you already have active OCI & GCP Subscription &have access to portal.
2. Setup OCI Data Flow, OCI Object Storage Bucket and OCI Data Science Notebook.
Please refer below Oracle & Blog:
https://docs.oracle.com/en-us/iaas/data-flow/using/data-flow-studio.htm#data-flow-studio
https://blogs.oracle.com/ai-and-datascience/post/oci-dataflow-with-interactive-data-science-notebook
3. Create & Download “Google API JSON Key secret OCID” for the Project where BigQuery Database is residing on GCP.
4. Upload the “Google API JSON Key secret OCID” to OCI Object Storage
Sample OCI Object Storage : “oci://demo-bucketname@OSnamespace/gcp_utility/BigQuery/ocigcp_user_creds.json”
5. Download Spark BigQuery Jar and upload it to Object Storage:
Sample: spark-bigquery-with-dependencies_2.12-0.23.2.jar
Download Spark BigQuery Jar from : https://mvnrepository.com/artifact/com.google.cloud.spark/spark-bigquery-with-dependencies_2.12/0.23.0
6. Collect below parameters for you GCP BigQuery Table.
7. Download ADW Wallet from OCI Portal & keep the User & Password handy.
Access GCP BigQuery Using OCI Data Science Notebook with OCI Data Flow:
1. Open OCI Data Science Session, where you have already created Conda environment for OCI Data Flow. [Refer] : Prerequisite Point 2.
2. Open New Notebook with DataFlow as Kernel.
3. Now, Create livy session for OCI Data Flow & provide other required information including GCP BigQuery.
Sample Code to create SparkSession with Livy Session for OCI DataFlow:
command = {
“compartmentId”: “ocid1.compartment.oc1..xxxxxxx”,
“displayName”: “Demo_BigQuery2ADW_v1”,
“sparkVersion”: “3.2.1”,
“driverShape”: “VM.Standard.E3.Flex”,
“executorShape”: “VM.Standard.E3.Flex”,
“driverShapeConfig”:{“ocpus”:1,”memoryInGBs”:16},
“executorShapeConfig”:{“ocpus”:1,”memoryInGBs”:16},
“numExecutors”: 10,
“configuration”:{“spark.archives”:”oci://demo-ds-conda-env@osnamespace/conda_environments/cpu/PySpark 3.2 and Data Flow/1.0/pyspark32_p38_cpu_v1#conda”,
“spark.files”:”oci://demo-ds-conda-env@osnamespace/gcp_utility/BigQuery/ocigcp_user_creds.json”,
“spark.oracle.datasource.enabled”:”true”,
“spark.hadoop.google.cloud.auth.service.account.enable”:”true”,
“spark.jars”:“oci://demo-ds-conda-env@osnamespace/gcp_utility/BigQuery/bigquery_spark-bigquery-with-dependencies_2.12-0.23.2.jar”
}
}
command = f’\'{json.dumps(command)}\”
print(“command”,command)
%create_session -l python -c $command
4. Import required modules:
%%spark #Import required libraries. import json import os import sys import datetime import oci import google.cloud.bigquery as bigquery import google.cloud import pyspark.sql from pyspark.sql.functions import countDistinct
5. Read GCP BigQuery Table:
Sample Code1:
%%spark
# Read from BigQuery : "bitcoin_blockchain.transactions". i.e. At Source "BigQuery"
#Number of rows : 340,311,544
#Total logical bytes : 587.14 GB
df_bitcoin_blockchain = spark.read.format('bigquery').option('project','bigquery-public-data').option('parentProject','core-invention-366213').option("credentialsFile","/opt/spark/work-dir/ocigcp_user_creds.json").option('table','bitcoin_blockchain.transactions').load()
print("Total Records Count bitcoin_blockchain.transactions : ",df.count())
Sample Code2:
%%spark
#Read another BigQuery Table
df_RetailPOS_15min = spark.read.format('bigquery').option('project','core-invention-366213').option('parentProject','core-invention-366213').option("credentialsFile","/opt/spark/work-dir/ocigcp_user_creds.json").option('table','Retail_Channel.RetailPOS_15min').load()
df_RetailPOS_15min.show()
6. Load Data into Object Storage:
%%spark
#Write in Object Storage
df_RetailPOS_15min.write.format("json").option("mode","overwrite").save("oci://ds-Raw@osnamespace/TargetData/bitcoin_blockchain_transactions")
7. Load Data into ADW using Wallet Password
%%spark
print("Set Parameters for ADW connectivity.")
USERNAME = "admin"
PASSWORD = "xxxxx"
connectionId= "demolakehouseadw_medium"
walletUri = "oci://demo-ds-conda-env@osnamespace/oci_utility/Wallet_DemoLakeHouseADW.zip"
properties = {"connectionId": connectionId,"user" : USERNAME,"password": PASSWORD,"walletUri": walletUri}
print("properties:",properties)
%%spark
#Load into ADW:
TARGET_TABLE = "ADMIN.RETAILPOS_15MINUTES"
print("TARGET_TABLE : ",TARGET_TABLE)
# Write to ADW.
df_RetailPOS_15min.write.format("oracle").mode("append").option("dbtable",TARGET_TABLE).options(**properties).save()
print("Writing completed to ADW.....")
That’s the end of today’s blog. Thanks for reading!
See for yourself
With the Data Flow, you can configure Data Science notebooks to run applications interactively against Data Flow. Watch the tutorial video on using Data Science with Data Flow Studio. Also see the Oracle Accelerated Data Science SDK documentation for more information on integrating Data Science and Data Flow. More examples are available from Github with Data Flow samples and Data Science samples.
To get started today, sign up for the Oracle Cloud Free Trial or sign in to your account to try OCI Data Flow. Try Data Flow’s 15-minute no-installation-required tutorial to see just how easy Spark processing can be with Oracle Cloud Infrastructure.
