Enterprises are rapidly moving from text-only AI to multimodal systems that understand and generate across language, images, audio, and video—often tuned on proprietary data. Oracle Cloud Infrastructure (OCI) was among the first to offer orderability of NVIDIA GB300 NVL72 clusters to deliver a step-change in throughput for these emerging workloads. In this post, we highlight performance gains across representative multimodal training and inference scenarios—CLIP-style encoders, diffusion-based image generation (Flux), and vision-language model (NVIDIA Nemotron Nano 2 VL) inference—and show how scaling translates into higher end-to-end throughput. For the first time, we present systematic studies of scaling within and across GB300 NVL72 systems.
Next-Gen Multimodal AI Applications
Businesses are turning large, heterogeneous datasets—proprietary video, multimodal documents (presentations, PDFs, charts), and dense reports—into new products and revenue. Multimodal RAG is a leading example: agents can ingest and reason over text, images, and tables (and, increasingly, audio/video) to produce grounded answers. Beyond RAG, multimodal representation learning is powering semantic search, content discovery, and video understanding for analytics at scale.
In parallel, image and video generation are moving from novelty to enterprise capability, enabling faster, lower-cost personalization and more automated visual workflows. Use cases span consumer experiences like virtual try-on for retail and rich content generationacross industries, and enterprise applications such as dynamically tailoring ads and product placement in streaming video and accelerating product visualization pipelines—shortening production cycles and time-to-market.
Multimodal AI workloads generally fall into three task types—representation learning, understanding, and generation—each with distinct enterprise value and compute profiles. Representation learning builds high-quality embeddings from mixed data (e.g., powering semantic search and content discovery across videos and documents); understanding focuses on reasoning over multimodal inputs (e.g., a multimodal RAG agent answering questions grounded in text, tables, and images); and generation synthesizes new content (e.g., creating personalized product visuals or short-form video variants for marketing). Because these tasks stress the system differently—throughput vs. latency, training vs. inference, and communication vs. memory bandwidth—the “best” hardware scaling strategy can vary materially by workload.
The Hardware Advantage: Powering AI with NVIDIA GB300 ON OCI
As multimodal use cases scale, so do their compute requirements—but not uniformly. Differences in model architecture and data modality can change the bottlenecks, yet the common reality is that multimodal workloads are compute-intensive and bandwidth-hungry: high-dimensional visual and temporal signals drive large sequence lengths, heavy attention compute, and significant memory pressure. Even a few seconds of video can translate into thousands of tokens, pushing transformer-based understanding and generation models toward throughput, memory capacity, and interconnect limits.To help customers meet these demands, Oracle Cloud Infrastructure (OCI) is sharing new benchmark results on next-generation NVIDIA GB300 NVL72 clusters built on the NVIDIA Blackwell architecture. NVIDIA GB300 NVL72 delivers a major step up in BF16 compute and High Bandwidth Memory (HBM): a rack-scale GB300 NVL72 provides up to 360 PFLOPS (BF16) and 20 TB of GPU memory—designed for workloads such as real-time video analytics, domain-tuned multimodal RAG, and high-fidelity image and video generation.
Benchmarking Multimodal Performance at Scale
To rigorously evaluate the capabilities of OCI’s NVIDIA GB300 NVL72 clusters, we structured our benchmarking results into three critical categories that represent the core pillars of multimodal enterprise AI.
1. Multimodal Encoder: Unprecedented Training Throughput with CLIP
Training a vision-language encoder from scratch—or fine-tuning it on proprietary enterprise documents— requires substantial scale and compute. Using CLIP as our representative multimodal encoder, we observed performance improvements in both batch sizes (up to 3x) and training throughput (up to 5x) as shown in Figure 1.
The contrastive loss in CLIP training is both communication and memory intensive. It increases the number of all-to-all primitives (all_gather, all_reduce) during loss computation, as the negative samples across all the GPUs have to be taken into account for each training step, increasing the GPU-to-GPU communication. The effectiveness of contrastive loss also depends strongly on using large batch sizes, which improves the quality and diversity of negative samples. In our experiments, we therefore scaled along two axes—batch size and GPU count—to understand how performance evolves under these demands. This approach deliberately stresses the system, placing additional pressure on GPU memory capacity as well as the cluster interconnect bandwidth and latency.
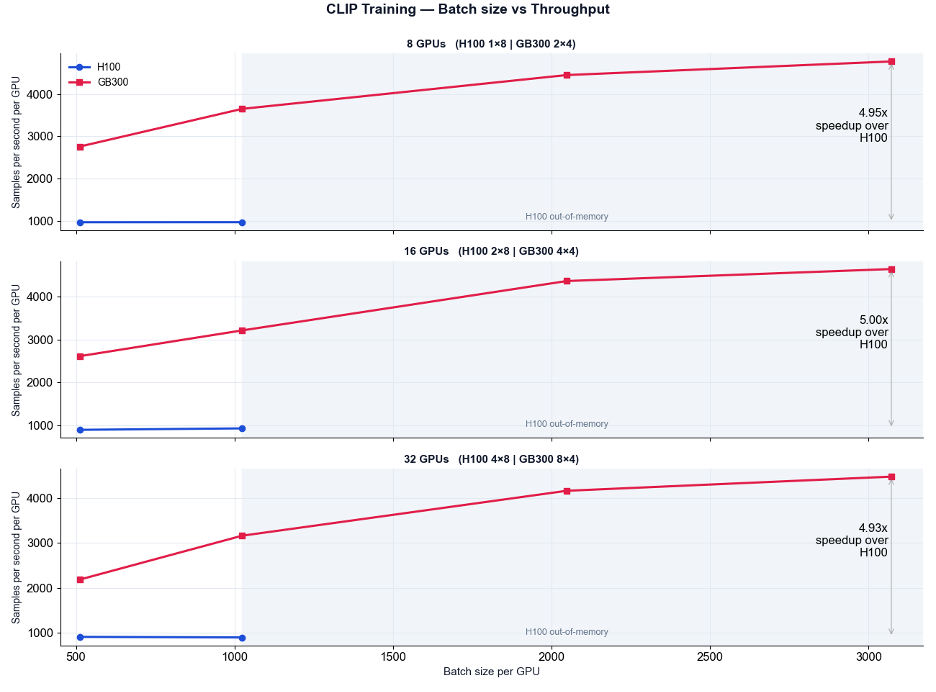
Figure 1: Comparison of throughput and speedup of GB300 over H100 in CLIP training when using different batch sizes. Leveraging the 288GB HBM3e memory on GB300, we achieve higher sample throughput and an overall 5x speedup over H100.
Key Takeaways:
• Massive Throughput Gains: We achieved a 5x improvement in training throughput on the GB300 compared to previous-generation H100 clusters.
• Expanding Batch Sizes: Thanks to the vastly increased HBM on the GB300, we successfully explored and validated 3x larger training batch sizes compared to H100 clusters which vastly improves the effectiveness of contrastive loss. This ensures faster, more stable, and highly efficient model convergence during training on large-scale domain-specific corpora.
2. Image Generation Training: First ever scaling study on GB300
Image and video generation models are at the heart of the customized marketing and media revolution. Our training benchmark of the popular Flux model on OCI GB300 instances highlighted not just raw performance, but that push-button developer experience on OCI slightly exceeds NVIDIA’s own MLPerf v5.1 results as shown in Figure 2.
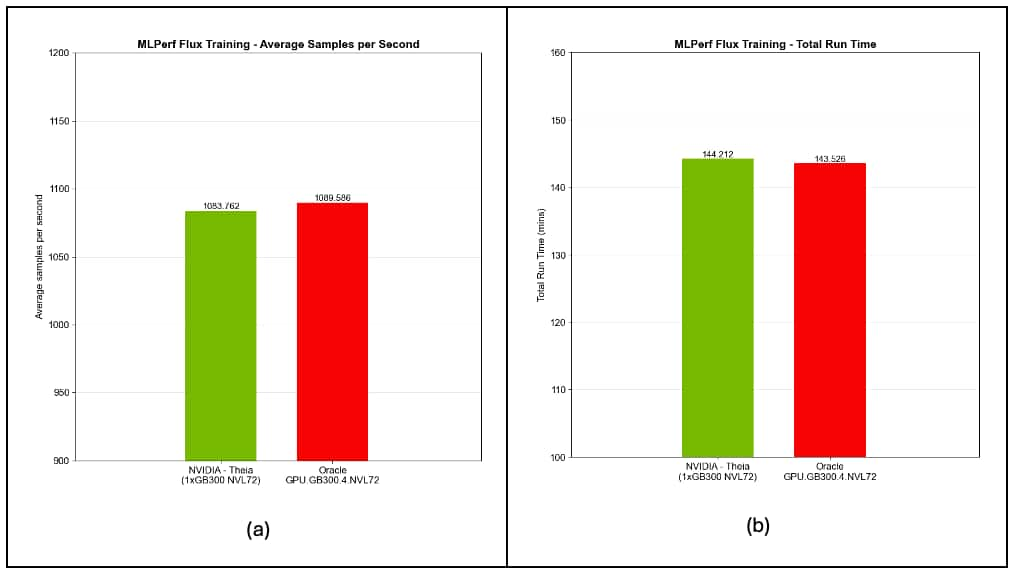
Figure 2: Throughput metrics on MLPerf Flux training using OCI GPU.GB300.4.NVL72 compared to official MLPerf v5.1 results submitted by Nvidia. Results show that we achieve 0.6% improvements on metrics (a) average samples per second throughput, and (b) total run time of MLPerf Flux Training.
In addition to competitive throughput, our experiments indicate that the GB300s on OCI scale remarkably well with a scaling efficiency of 72% compared to the theoretical maximum (linear scaling) for training runs up to 128 GB300 GPUs. See Figure 3 for a visualization of the scaling trend.
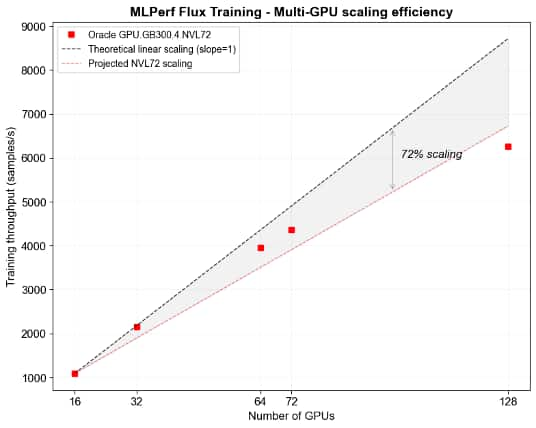
Figure 3: Scaling efficiency of OCI GPU.GB300.4NVL72 on MLPerf Flux training benchmark in a distributed computing workload. As we increase the number of GPUs used in training up to 128 cards, we observe a scaling efficiency of 72% compared to theoretical upper bounds.
We evaluated scalability both within a single NVL72 block and across two NVL72 blocks. Within an NVL72 block, GPU-to-GPU communication runs over NVLink, while scaling across two NVL72 blocks continues to rely on NVLink for intra-block traffic and engages RoCE for inter-block communication. To measure any effect on latency and overall throughput, we ran a systematic comparison using 72 GPUs in two configurations: (1) Singe-block: all 72 GPUs contained within a single NVL72 block, and (2) Cross-block a 36+36 split across two NVL72 blocks. Figure 4 shows the throughput measurements for both configurations, with the cross-block throughput at 99.4% of the single-block throughput. Overall, these results suggest there is minimal loss in scaling efficiency when expanding outside a single NVL72 block.
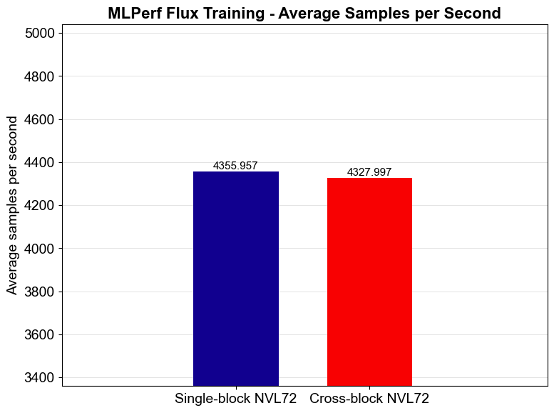
Figure 4: Comparison of single versus cross NVL72 block throughput. We observe a 99.4% throughput measurement in cross block throughput due to GPU-to-GPU communication overhead..
Key Takeaways:
• Ease of Use on Blackwell: We delivered out-of-the-box performance that matches or exceeds of NVIDIA’s official MLPerf v5.1 (Nov’25) submission results, demonstrating the exceptional ease of deploying the GB300 architecture on OCI’s Blackwell clusters.
• Exceptional Scalability: Our comprehensive scaling study—evaluating performance both within a single NVL72 rack and across multiple NVL72 racks—showcased near-linear scaling. This ensures that as your generation demands grow, OCI’s infrastructure seamlessly scales with you.
3. VLM Inference: High-Throughput Deployment via vLLM
Serving large Vision Language Models in a production environment requires a delicate balance of high token throughput and low latency, and a single GB300 was capable of supporting more than 30 concurrent sessions through a vLLM server as shown in Figure 5.
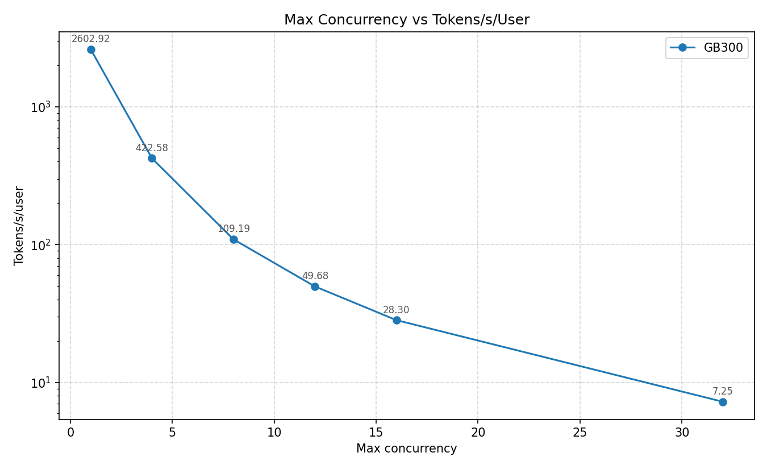
Figure 5: Tokens per second throughput under various concurrency configurations for multimodal LLM inference on GB300. A vLLM inference server is run on a single GPU to serve user queries related to video understanding. The model used is NVIDIA-Nemotron-Nano-VL-12B-V2-FP8, which is an auto-regressive vision language model.
Key Takeaway:
• By benchmarking VLM inference on Nemotron Nano 2 VL through a vLLM server, we validated the GB300’s ability to serve interactive, real-time multimodal workloads with the reliability required for production-grade enterprise agents.
Conclusion: Ready for Primetime
The convergence of language, image, and video data is driving the next major leap in enterprise AI. As our benchmarking results across training CLIP, Flux, and inference of Nemotron Nano 2 VL demonstrate, NVIDIA-based Blackwell clusters at OCI are officially ready for enterprise-scale deployment.
Whether you are customizing vision-language models for complex document intelligence or generating dynamic content for personalized media, OCI provides the exact compute infrastructure you need. By leveraging the GB300 architecture, organizations can seamlessly scale their most demanding multimodal workloads, drastically reduce time-to-market for custom AI solutions, and disrupt industry verticals.
We would like to acknowledge the OCI AI Foundations team members Sarthak Sharma, Anu Kalra, Vikas Upadhyay, Shaoyen Tseng, Vasudev Lal, and Sujeeth Bharadwaj for their contributions to this blog.
