The recent explosion in LLM usage has skyrocketed demand for GPUs, particularly high-end NVIDIA chips such as H100 and GB200. Deep tech startups, however, typically have computational workloads that fall outside of the LLM and deep learning spaces. Examples include Computational Fluid Dynamics (CFD), Computational Structural Mechanics, Molecular Dynamics (MD), and Density Functional Theory (DFT). The bottlenecks and figures of merit can also be different for startups that utilize these methods to screen new materials or designs at scale, where GPU-hours per data point becomes a more meaningful metric than raw compute power. Innovation-driven businesses looking for solutions to these use cases can accomplish their goals without breaking the bank on premium GPUs or bottlenecking their screening throughput.
This blog presents a proof of concept for GPU-accelerated computational materials screening workloads jointly conducted by Aionics, Inc. and Oracle Cloud Infrastructure utilizing a VM cluster accelerated with NVIDIA A10 GPUs. The focus will be on two use cases: molecular density functional theory with GPU4PySCF and high-throughput Machine-Learned Interatomic Potential (MLIP) inference.
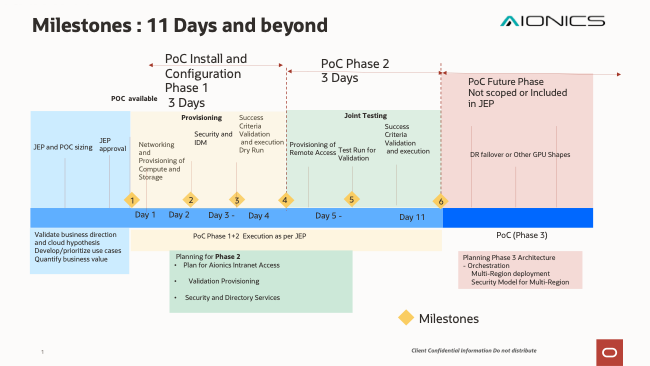
Milestones and Timelines
Figure 1 shows Expected Timeline for Proof of Concept in calendar days *note it’s not listed in deployment hours we were able to complete this POC four days early:
Architecture and Functionality
Figure 2 shows the reference architecture used for POC:
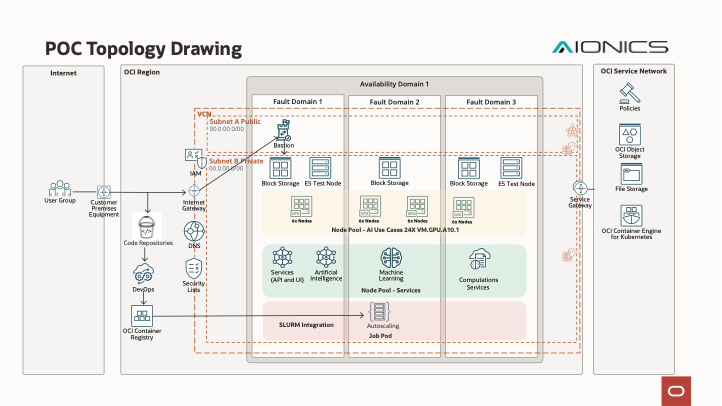
This architecture ensures the user has access to all the tools and workflows typically found in on-premises compute clusters and supercomputing centre:
- Login and Compute nodes are all connected to a single Network File system (NFS).
- Compute nodes are provisioned on-demand and scaled as needed using a scheduler (e.g. SLURM).
- The user’s software stack can be managed using an environment module tool (e.g. Lmod or EnvironmentModules) for consistency and modularity.
Performance
First, we look at GPU-accelerated atomic orbital DFT. This is a widely utilized computational chemistry framework for studying molecules in electrolyte and drug development. Recently, this framework was engineered for GPU acceleration by Li et al. in the GPU4PySCF Python package [1]. OCI’s A10 GPUs can run geometry relaxation [2] of small-to-medium organic molecules in seconds to minutes, showing up to two-orders-of-magnitude speedup over CPU parallelization (8 tasks) and up to 40% speedup over L4 GPUs, which are of comparable VRAM and pricing.
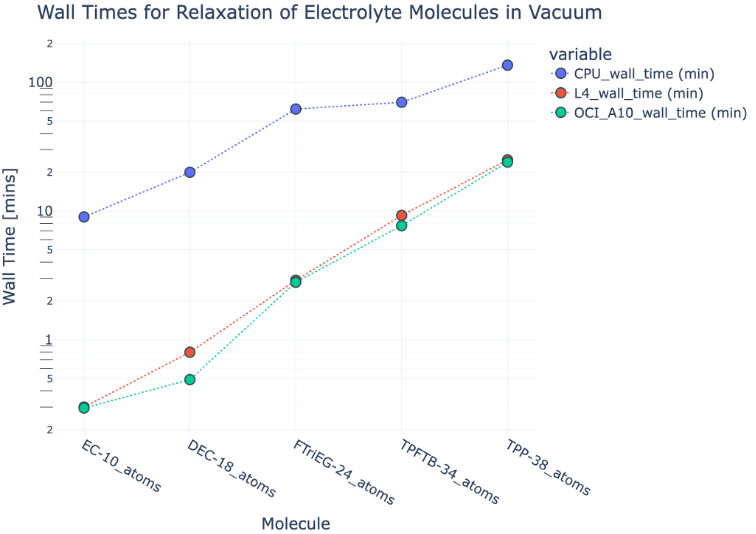
Figure 3 – Atomic-orbital DFT structural relaxation wall times for various known electrolyte molecules
Next, we look at geometry relaxation with a Machine-Learned Interatomic Potential (MLIP) for a molecule-on-a-surface material system. Studying molecular adsorption on surfaces has wide ranging applications from catalysis to energy storage, but using DFT for such studies is typically computationally prohibitive at a large scale. MLIPs are machine learning models that are pretrained on large DFT datasets to predict molecular and/or solid-state material structures. These models can accelerate structural relaxation and screening by multiple orders of magnitude since they essentially replace the iterative solving of high-dimensional equations with ML inference.
In this example, we look at average MLIP relaxation wall time for 70 initial configurations of a 27-atom organic molecule on a 300-atom surface, with 6 chemical species in total, using the Orb v2 MLIP [3]. Once again, the data shows a significant speedup of 2.3x for A10 shapes over L4s. The queuing system also enables high-throughput submission of these jobs. At 2.5 minutes per simulation, a single cluster can relax hundreds or thousands of structures in a few hours.
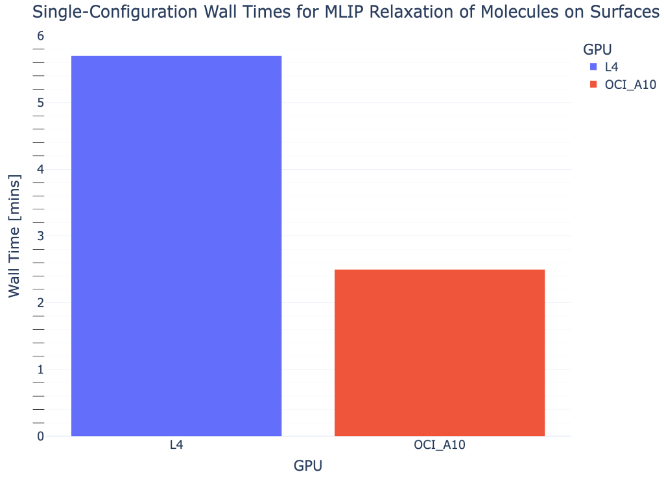
Figure 4 – Average single-configuration wall times for MLIP relaxations of a medium-sized molecule on a crystal surface
Conclusion
When considering how to design compute infrastructure for your deep tech company, there are a variety of factors to balance: cost, wall time, and the most likely performance bottlenecks. For GPU workloads, it is not enough to think of raw specifications like tensor cores and VRAM. OCI’s VM clusters and A10 shapes enable this flexibility in design, where you can extract the most data points per dollar by increasing GPU utilization while leveraging data parallelism and dynamic resource scheduling.
About Oracle Cloud Infrastructure (OCI)
Oracle Cloud is the first public cloud built from the ground up to be a better cloud for every application. By rethinking core engineering and systems design for cloud computing, OCI created innovations that solve problems that customers have with existing public clouds. OCI accelerate migrations of existing enterprise workloads, deliver better reliability and performance for all applications, and offer the complete services customers need to build innovative cloud applications.
To learn more information on OCI creating OKE with GPU instances https://docs.oracle.com/en-us/iaas/Content/ContEng/Tasks/contengrunninggpunodes.htm
About Aionics, Inc.
Founded in 2020, Aionics is pioneering a new era of formulation design by combining artificial intelligence, quantum simulation, and proprietary data to develop custom, high-performance materials for mission-critical applications. Headquartered in Palo Alto, Aionics works with leading companies in automotive, aerospace, defense, and energy to design drop-in chemical solutions that improve performance, safety, and sustainability.
To learn more, visit www.aionics.io
Contributors
Mohamed K. Elshazly, PhD – Aionics, Inc.
Randy Trampush – Oracle Enterprise Cloud Architect
Ryan Helferich – Oracle Enterprise Cloud Architect
Mac Stephen – Oracle AI-GPU Cloud Engineer
Footnotes
[1] https://arxiv.org/abs/2407.09700
[2] Relaxations conducted using GeomeTRIC package at the B3LYP/6-31+G* level of theory with density fitting.
