MyOracle is the centralized intranet portal available to all Oracle employees to get access to all of Oracle’s resources. It receives over 5 million hits monthly from remote and Oracle office-based employees facilitating employee experience related to HR applications, including payroll, hiring and team management, accessing content related to employees’ daily jobs. One of the most important features of this portal is MyOracle Search, an enterprise search service that gets over 500,000 queries per month. MyOracle Search is an Oracle JET-based user interface that runs in Oracle Container Engine for Kubernetes (OKE) and uses cloud native architecture to ingest data from the many data sources at Oracle.
Historical problems with search
Working for over a decade across different search technologies, we at Oracle Cloud Infrastructure (OCI) have realized that search is a difficult problem, and many face the following challenges:
Lack of semantic understanding
Lexical search works only because it involves searching for exact matches of terms or keywords in a document without understanding the underlying meaning or context. This lack of context can lead to inaccurate results, especially when dealing with ambiguous terms or variations in language. A good example to understand this issue is through the interpretation of synonyms.
Suppose that you’re using a search engine with a lexical search approach, and you input the query: “Reset SSO password.” In a system that primarily relies on lexical search, it can retrieve documents containing the exact phrase “reset SSO password” but might not consider documents that use synonymous terms, such as “not able to log in” or “not able to authenticate.”
A semantic-aware search system understands that terms like “SSO,” “single sign-on,” and “login” can be used interchangeably in certain contexts. However, a purely linguistic search might miss relevant documents with equivalent information but different wording. This lack of semantic understanding could lead to incomplete search results and might not effectively capture the user’s intent.
In contrast, a semantic search system recognizes the relationships between related terms and provide more comprehensive results by considering synonyms and context. This approach enhances the search experience by understanding the meaning behind the words, resulting in more accurate and relevant information retrieval.
Limited relevance ranking
Lexical search often lacks sophisticated relevance ranking mechanisms. Consequently, results might be presented based on keyword frequency or document relevance without considering the importance of certain terms in a specific context.
Inability to capture intent
Lexical search fails to effectively capture the user’s intent behind the query, potentially missing documents semantically related to the user’s goal, despite containing the keywords used in the query.
Limited natural language understanding
Lexical search doesn’t incorporate advanced natural language understanding capabilities. It might need help with complex queries, negations, or queries framed in natural language, limiting its ability to handle diverse user inputs. One example includes their inability to comprehend complex queries, especially those involving context, intent, or nuances.
Consider the following query: “My Mac is locked. How do I log in?”. In a lexical search engine with limited natural language understanding, the system might focus solely on the individual keywords in the query, such as “mac,” “locked,” and “log in.” It can retrieve documents that contain these exact terms without including the broader context or the user’s underlying intent. In this context, limited natural language understanding has the following limitations:
- Inability to account for intent: The search engine struggles to parse the user’s intent behind the query, missing documents that discuss the broader topic of users locked from their computers over SSO login issues.
- Limited context awareness: Lexical search engines lack the ability to understand the context in which words are used. In this example, the engine might not recognize that “Mac” refers to the Apple Macbook.
How OCI improves searching
In the last few years, we have upgraded search using the OCI Data Science platform and transformer models to support semantic search which focuses on understanding the meaning of the query and the context of the information instead of only matching keywords. It uses natural language processing (NLP), machine learning (ML), and other advanced techniques to comprehend the intent behind a user’s query.
To get relevant results based on user intent, we designed numerous ML models using OCI Data Science for metadata enrichment, identification, and retrieval of the most relevant results based on user intent. We have also built ML flows that allow us to tweak ML models or the underlying knowledge and compare results to allow for continuous improvement cycles.
“With the rollout of semantic search on MyOracle Search, we noticed our click-through rates on search increased from 30–40% to 65%–70%,” said Sudhir Dureja, senior director of Enterprise Engineering.
After conducting multiple employee usability studies, we noticed that despite finding the most relevant knowledge article, employees might not read the article completely. We concluded that the length of article is still a deterrent in getting the information employees need. Considering the employee experience needs with immense benefits for providing the right answer in the desired format, we decided to extend the search results with generative AI methods.
In early 2024, we introduced search generative experience (SGE) on MyOracle Search, an information retrieval process incorporating generative AI models to enhance the overall user experience during the search process. This enhancement involves adding a generative AI model that utilizes the AI-generated search results, which then deliver specific answers to the user’s query.
Retrieval-Augmented Generation
The SGE is based on the Retrieval-Augmented Generation (RAG) model architecture used in NLP, particularly in question-answering and text generation. The RAG system combines the vector database, embeddings model, and text generation model to synthesize grounded responses based on retrieved documents. Instead of displaying the list of records found like traditional searches do, RAG architecture uses the text generation model to produce a natural language response that answers the original question. To help users further, the generated answer is supported by references and links to the source documents.
Figure 1 demonstrates the enhanced search functionality using RAG. Here’s how it works: When an employee asks something like “How do I reset my VPN password” the search uses generative AI and RAG to generate the most contextually relevant results. These results are delivered inline as step-by-step instructions within the response, eliminating the need for document access to initiate problem-solving. Additionally, a reference to the source document(s), used to create the step-by-step answers, is also provided if the employee chooses to investigate more deeply.
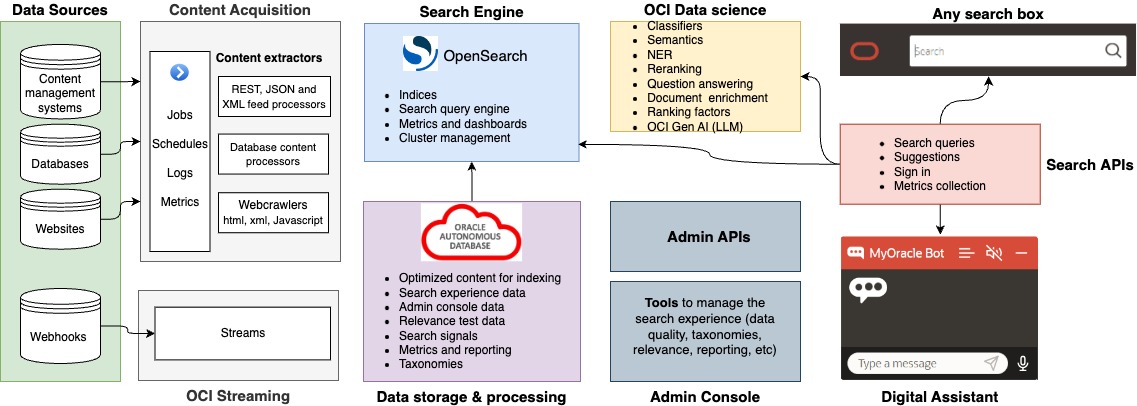
Figure 3 below showcases in detail how the RAG architecture works with MyOracle Search.
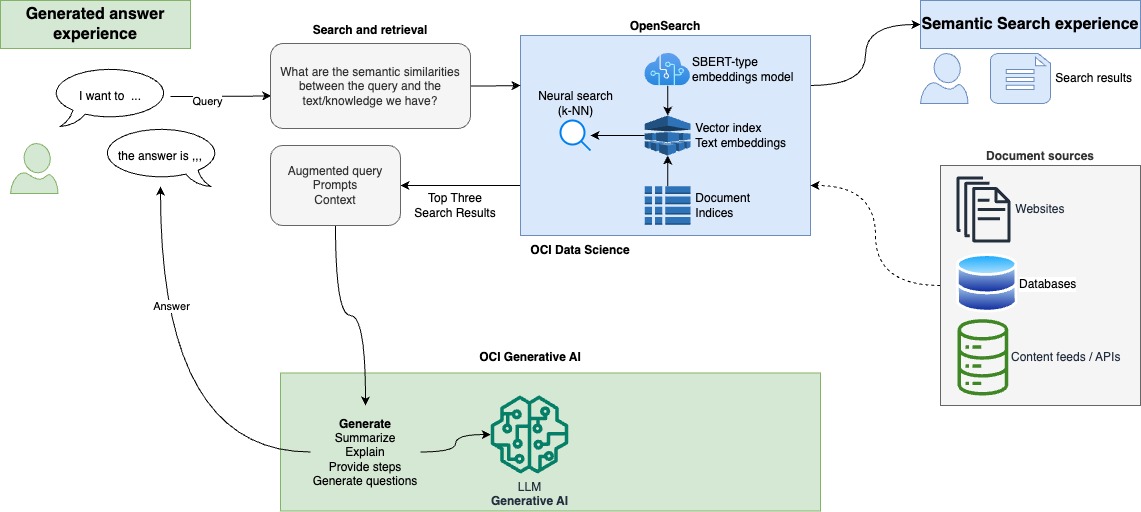
Conclusion
The release of SGE in MyOracle Search with semantic search and generative AI has significantly enhanced the search experience for all Oracle employees leading to increased click-through rates and improved content comprehension. “Since the release of the SGE experience for employees, over 75% of employees have provided positive feedback on the quality of generated answers.” said Sudhir Dureja, senior director of Enterprise Engineering.
The RAG model uses AI-generated content and NLP to provide focused and contextually relevant responses, supported by grounded references to source documents. As Oracle continues to innovate in enterprise search, employees can expect more intuitive and intelligent search capabilities that truly understand their intent and deliver precise, actionable information.
We plan to expand the knowledge sources with both structured and unstructured data so that RAG model can help employees find answers to any question from any domain. For more information, see the following resources:
