In a previous blog post, we explored the architecture design and principle steps on how to deploy fine-tuned large language model (LLM) inference containers on Oracle Container Engine for Kubernetes (OKE) using Hugging Face TGI. As a follow-up, this post dives deeper into building Docker images for model-downloader and the web inference client, enabling an interactive demo for your fine-tuned model. We also cover how to restrict access to the Oracle Cloud Infrastructure (OCI) Object Storage bucket and safeguard your LLM models in the repository. By the end, you have the practical knowledge to implement the design and deploy the solution to OCI.
Model download container
As discussed in the previous post, we create a Python script to load model from Object Storage bucket for TGI Inference server. We then wrap this script in a Docker image to run it as a container on OKE. Use the following steps:
- Create a Python application:
- Write a Python script to download objects from the model repo bucket.
- Use environment variables defined in the tgi-server deployment manifest to pass in the bucket name, prefix, region, and tenancy OCID.
- Create a requirements file: List OCI as dependency to ensure that the OCI software developer kit (SDK) is installed.
- Build a Docker file:
- Copy the Python app and requirements files into the Docker image.
- Install the required dependencies.
- Configure the container to run the Python application on startup.
- Build the Docker Image:
- Build the Docker image.
- Upload image to OCI Container Registry (OCIR).
To get started, you can use the following example image:
Inference client container
Huggingface-hub is a Python package that features the InferenceClient class, which streamlines calling the TGI endpoint hosting your machine learning (ML) model. Complementing this feature, Gradio is an open source Python library that makes it easy to create user-friendly, customizable UI for interacting with your ML models, APIs, and other Python functions. Gradio includes a ChatInterface wrapper that enables you to build chatbot UI in a few lines of codes. To package Huggingface-hub and Gradio ChatInterface together as inference client container, follow these general steps:
- Create a Python application:
- Write a Python application using the Gradio ChatInterface and Huggingface-hub libraries.
- Pass in the tgi-server-service URL (tgi_endpoint), and other optional variables, such as ‘title’ and ‘max_token,’ defined in the Inference client deployment manifest.
- Create a requirements file: List huggingface-hub and Gradio as dependencies.
- Build a Dockerfile:
- Copy the Python app and requirement files into the Docker image.
- Install required dependencies.
- Configure the container to run the Python application on startup.
- Expose the port 7860, which the application runs on.
- Build the Docker image and upload it to OCIR.
You can use the following example image:
Model access control
OKE Workload Identity provides fine grained access control to OCI resources, including Object Storage. A workload resource is identified by the OKE cluster OCID and Kubernetes pod attributes, such as namespace and associated service account. This feature enables users to grant OCI resource access by writing a standard Identity and Access Management (IAM) policies, as illustrated in the following example.
For demonstration purposes, we download the llama3-8b-Instruct model to the tgi-model-repo bucket under llama3-8b-instruct subfolder. You can substitute it with any model of your choice. We created a service account in the llm namespace using the following command:
kubectl create serviceaccount oci-os-model-repo -n llm
Next, I create the following OCI IAM policy to allow the model-downloader to access the models in the bucket.
Allow any-user to read objects in compartment demo where all {target.bucket.name='tgi-model-repo', request.principal.type = 'workload',request.principal.namespace = 'llm',request.principal.service_account = 'oci-os-model-repo',request.principal.cluster_id = '<oke cluster ocid> '}
Use the Workload identity signer for the model-downloader python script.
signer = oci.auth.signers.get_oke_workload_identity_resource_principal_signer()
The final step is to ensure that you associate the oci-os-model-repo service account with the model-downloader pod when you create the tgi-server deployment.
serviceAccountName: oci-os-model-repo
Putting It all together
Now that we have built the Docker images and configured IAM permissions, we’re ready to create Kubernetes deployments and services on OKE. For the tgi-server deployment, create a pod spec that includes both the TGI server and model-downloader init container, specifying your bucket name, prefix, region, and tenancy OCID. Associate the service account, oci-os-model-repo, and specify number of GPU required. The following code block shows a snippet of the manifest.
containers:
- name: tgi-server
image: "ghcr.io/huggingface/text-generation-inference:2.0.4"
resources:
limits:
nvidia.com/gpu: 1
args: ["--model-id","/model"]
volumeMounts:
- name: shared-data
mountPath: /model
ports:
- containerPort: 80
name: http-tgi
initContainers:
- name: model-downloader
image: "iad.ocir.io/idqr4wptq3qu/llm-blog/model-downloader:v1"
env:
- name: bucket
value: "<model_repo_bucket>"
- name: prefix
value: "<model_folder>"
- name: region
value: "<oci_region>"
- name: tenancy
value: "<oci_tenancy_id>"
volumeMounts:
- name: shared-data
mountPath: /model
serviceAccountName: oci-os-model-repo
volumes:
- name: shared-data
emptyDir: {}
Next, create the inference client deployment using the custom-built image. Configure the tgi_endpoint environment variable to reference the tgi-server-service created in the previous step. You can also create optional environment variables to customize the appearance and behavior of Gradio, tailoring the user interface to meet your specific needs.
containers:
- name: gradio
image: iad.ocir.io/idqr4wptq3qu/llm-blog/inference-client:v1
env:
- name: tgi_endpoint
value: "http://tgi-server-service"
- name: example1
value: "<your example prompt>"
- name: example2
value: "<your example prompt>"
resources:
ports:
- containerPort: 7860
For a complete list of Kubernetes manifests, Python scripts, and Dockerfiles, check out the detailed resources available in this GitHub repository.
To access the inference client, open your browser and navigate to the load balancer IP of the llm-webui service on port 7860.
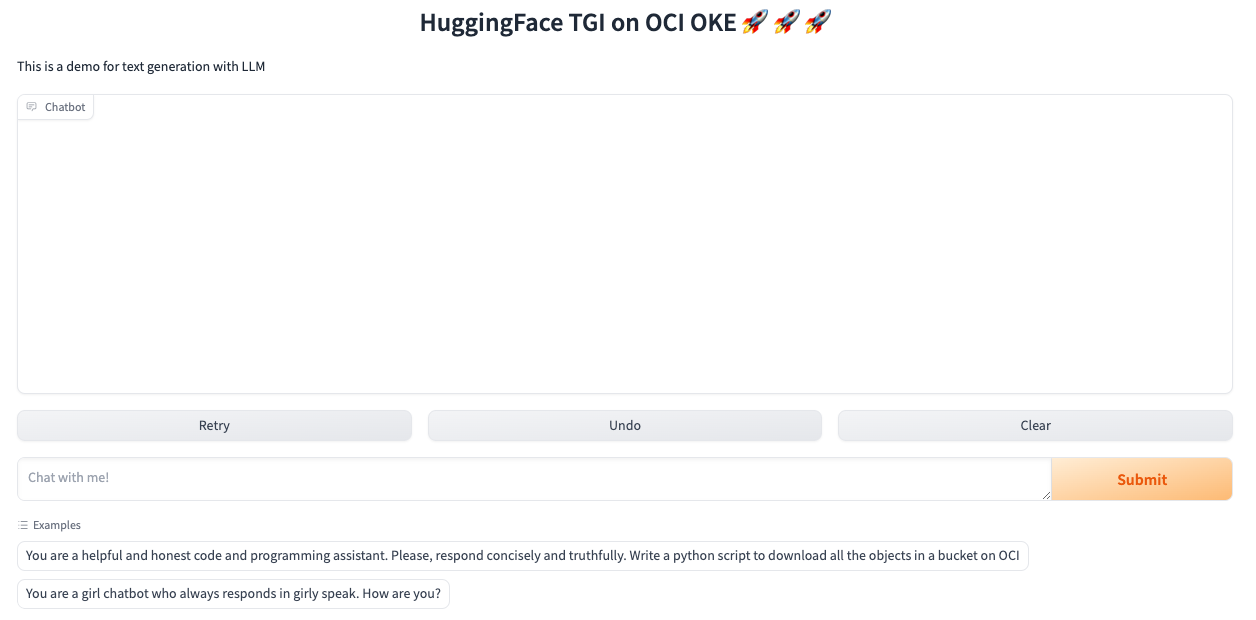
Conclusion
Storing your fine-tuned LLM model in OCI Object Storage and controlling access through the Workload Identity feature allow you to adhere to the principle of least privilege. Utilizing OKE and GPU instances on Oracle Cloud Infrastructure, you can build a reliable and scalable inference infrastructure for your LLM workload without the management overhead. By using Gradio, you can quickly create and customize a web UI, enabling you to showcase your LLM model from anywhere. This approach offers a flexible and repeatable solution, allowing you to experiment with different models effortlessly.
For more information, see the following resources:
