Customizing AI and large language models (LLMs) is often considered expensive, time-consuming, and requiring specialized, powerful hardware, but is this always the case?
General-purpose LLMs, like ChatGPT, are revolutionizing business workflows. However, they fall short when it comes to company-specific needs and suffer from inaccurate response and hallucinations, particularly when the answer lies in proprietary data that the LLM hasn’t been trained on. Training LLMs to a fit a business’s unique requirements is costly and requires ongoing fine-tuning as company information and policies evolve.
So how can we achieve accurate, up-to-date, company-specific responses without breaking the bank? The solution lies in retrieval-augmented generation (RAG), which optimizes LLMs output by utilizing relevant, proprietary company data without modifying the model itself.
In this blog post, we explore a real-world scenario where a RAG architecture, powered by Oracle Cloud Infrastructure (OCI) Generative AI (GenAI) services, addresses a customer’s challenge.
The challenge: Answering employee questions efficiently
Let’s set the scene: Like many large enterprises, Supremo have a plethora of employee sites, documents, and scattered resources pertaining to their employee policies. This spread produces a heavy load on HR and other departments from employees asking routine questions, such as the following examples:
- Can I carry over unused time-off?
- What is the day rate for a level-4 consultant?
- How many days of annual leave am I entitled to?
The complexity grows with mergers and acquisitions because different employees might have entirely different HR policies. This complexity increases the effort required by HR and other departments in responding to such repetitive queries. RAG can streamline this process by combining the power of LLMs and your company’s proprietary data.
Introducing RAG: Retrieval-augmented generation
RAG consists of the following essential components:
- Retrieval: Searching through a collection of information to find relevant data that can address a user query.
- Augmented generation: Utilizes the retrieved information to create a more informed and contextually relevant response.
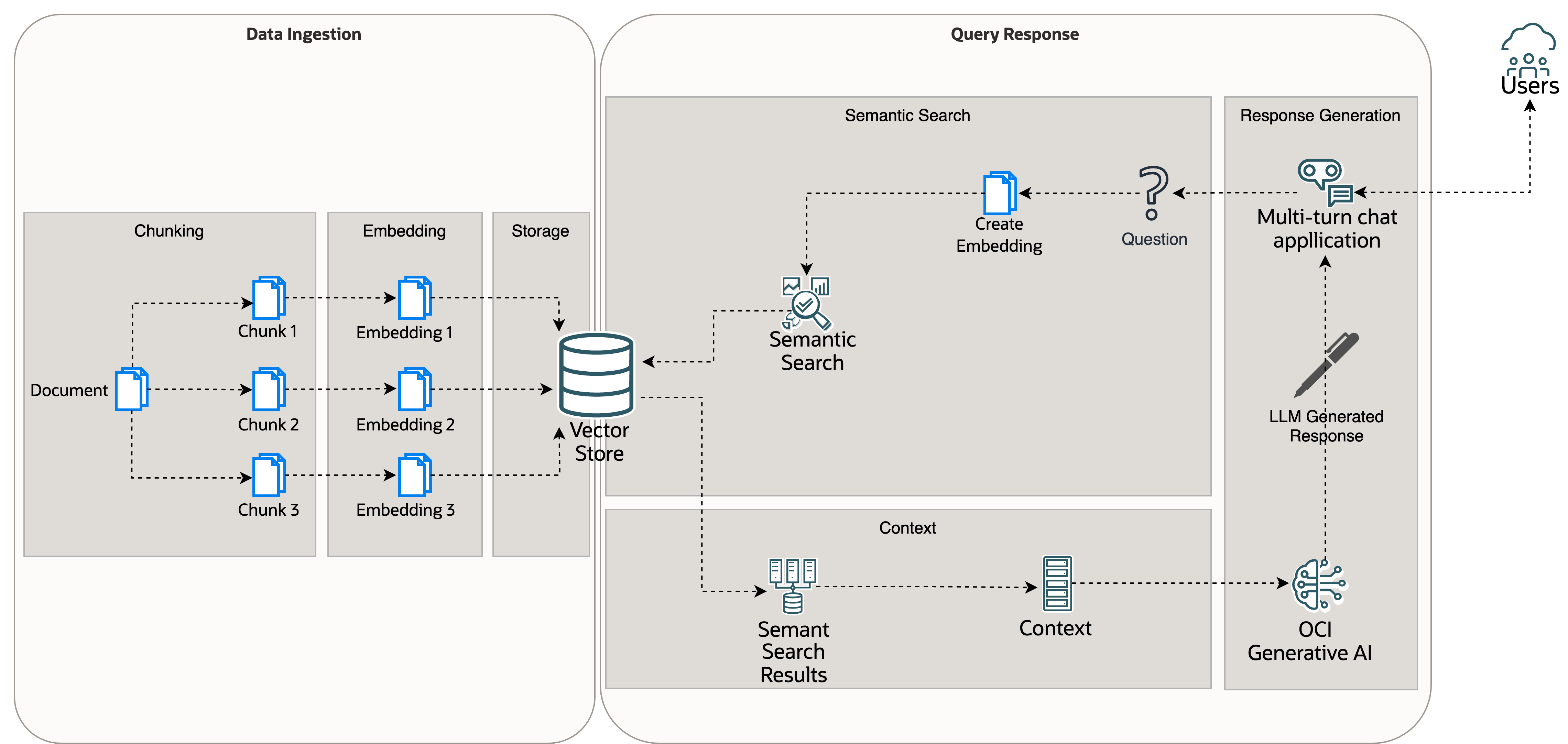
To help explain a RAG system, we can split it into two sections: Data ingestion and query response.
Data ingestion involves the following processes:
- Chunking: Divide the corpus of documents into smaller text segments, typically limited to a few hundred tokens each.
- Embedding: Apply an embedding model to transform these text chunks into vector embeddings that capture their semantic meaning.
- Storage: Store these embeddings in a vector database that supports semantic similarity searches.
Query Response involves the following processes:
- Semantic search: Converting a user’s query into a vector and searching the vector store to find semantically related documents.
- Context: The relevant document chunks from the semantic search result, the question and other pertinent information are packaged together to send to the LLM. Other pertinent information typically includes the following parts:
- Preamble – Custom prompt to control the behavior of the LLM. For example, “Base your response on the documents supplied and ignore previous learnt information.”
- Chat history: The history of previous interactions, which helps create a context and history aware response.
- Response generation: The LLM produces a bespoke response based on the pertinent documents, the question, and all other relevant information supplied.
A real-life example: RAG using OCI Generative AI services
Let’s look at two differing architectures that we can implement to create a RAG solution for the presented challenge. Both architectures have the following salient features:
- Oracle Digital Assistant (ODA): ODA assists users in asking questions, such as “Can I carry forward unused time-off,” and facilitates interactions across multiple channels, such as Slack, website, teams, and Oracle Apps.
- Oracle Autonomous Database 23ai: Autonomous 23ai acts as a vector store for embedded document chunks, such as HR policies. It also provides semantic search functionality. So, when a user asks, “Can I carry forward unused time-off,” the related document chunks, based on similarity or distance, are identified, irrespective of keyword matching.
- OCI Generative AI: This service has the following components:
- Embedding model: Converts documents and user queries into vectors, allowing the service to run a vector search to find documents that are semantically related to the user question.
- Chat or LLM: Uses LLMs, such as Meta Llama 3.1 70B and Cohere Command R, to generate responses based on retrieved document chunks, user question, and other context.
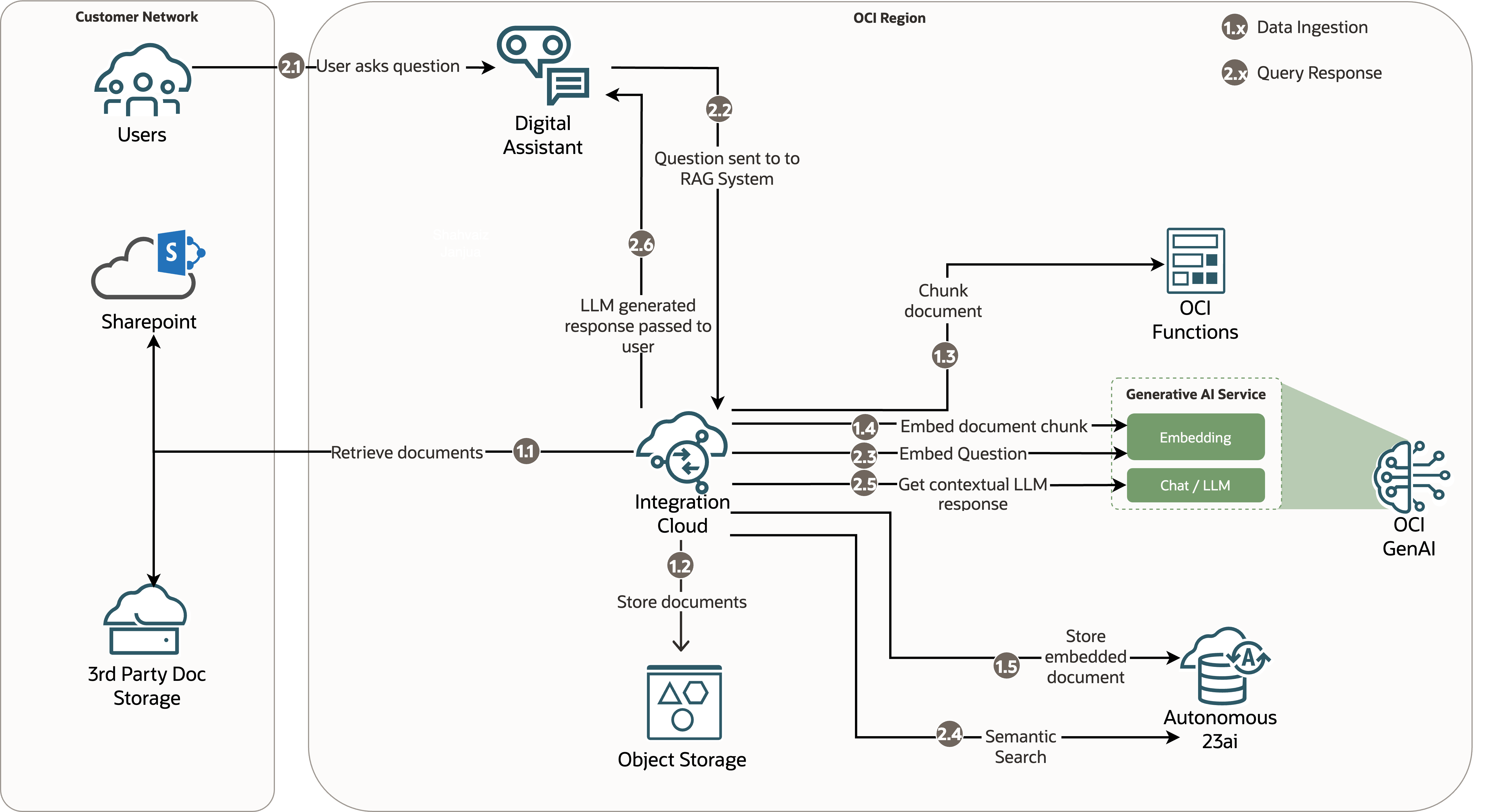
Architecture 1: OCI Functions
This architecture has the following unique, salient features:
- Oracle Integration Cloud (OIC) for orchestration: OIC is used to orchestrate, automate, and manage the entire RAG process, from document reception, document chunking, embedding, and storing (data ingestion) to question embedding, semantic search, LLM invocation with semantic search results and context, and passing the LLM response back to ODA (query response).
- OCI Functions: OCI Functions is invoked, during data ingestion, to perform the chunking of documents so they can be embedded and stored in the vector store.
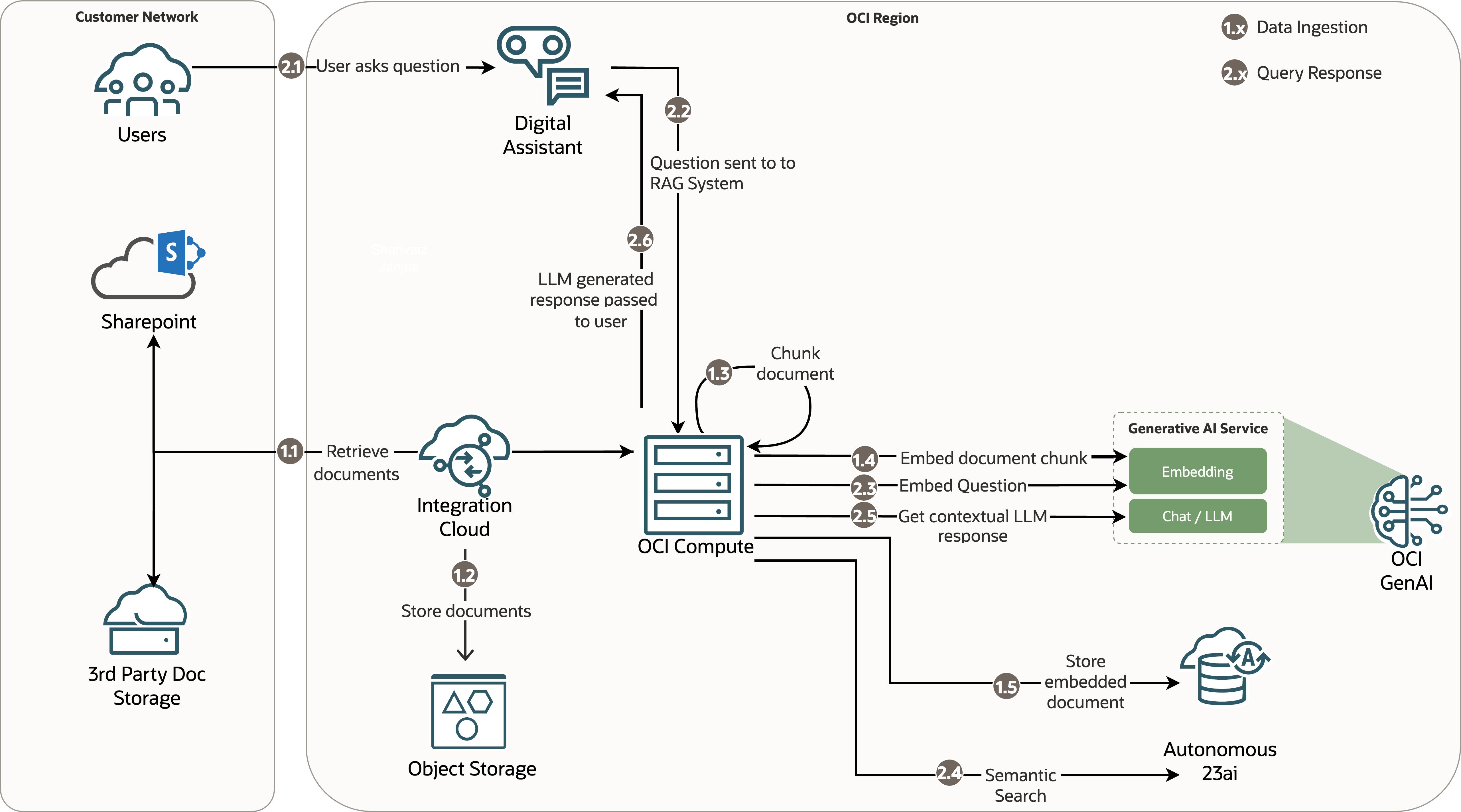
Architecture 2: Virtual machine
Architecture 2 has the following unique, salient features:
- OCI virtual machine (VM) for orchestration: The OCI VM takes the place of Oracle Integration Cloud in architecture 1, managing the orchestration and automation of the RAG process. As with Architecture 1, OIC retrieves documents from the document storage source.
- OCI VM for document chunking: The VM also takes the place of OCI Functions in performing the chunking of documents for the data ingestion process.
Each architecture has pros and cons, which we briefly compare in next section.
Architecture 1 and architecture 2 analysis
| Base |
OCI Functions |
OCI virtual machine |
| Runtime |
Max 300 s |
Unlimited |
| Payload |
Max 6 MB |
Unlimited |
| Memory |
Max 2,048 MB |
Max 10,496 GB (based on E5 flex shape) |
| Managed model |
Serverless (managed by Oracle) |
Self-managed |
| Scaling |
Automatic scaling based on events |
Manual vertical scaling or slower, automated horizontal scaling using instance pools |
| Cost structure |
Pay per run time |
Pay for allocated resources |
Choosing between an OCI Functions-based and VM-based architecture depends largely on the application’s functional and operational requirements. OCI Functions excel in scenarios where event-driven processing and scalability are paramount, while VMs offer flexibility and control for application deployments.
Conclusion
Can you build an AI system that can produce accurate, up-to-date, company specific responses without breaking the bank? As we’ve seen with the power of RAG, the answer is a resounding yes!
With RAG, businesses can harness AI efficiently, stay up-to-date, and manage costs, while ensuring high-quality and accurate responses based on your company’s proprietary data. The RAG architecture helps to manage costs by not only eliminating the need to obtain expensive GPUs, but also by optimizing the runtime costs with the OCI Generative AI pricing model, as shown in the following illustrative cost for OCI GenAI service. OCI GenAI offers the following price options:
- Embed text: $1 per month for 10,000 calls to the Cohere Embed model, with each call embedding text of 1,000 characters.
- LLM interaction: $4 / month for 10,000 calls to Cohere Command R, with each call containing a total of 1,000 characters, including request and response.
We’ve gone through our case study with Supremo and demonstrated the theoretical framework of the RAG solution and two practical architectures for implementation. We also compared these two options to show how they fit different business needs. Finally, let’s highlight the power of RAG and how it addresses challenges of general-purpose LLMs.
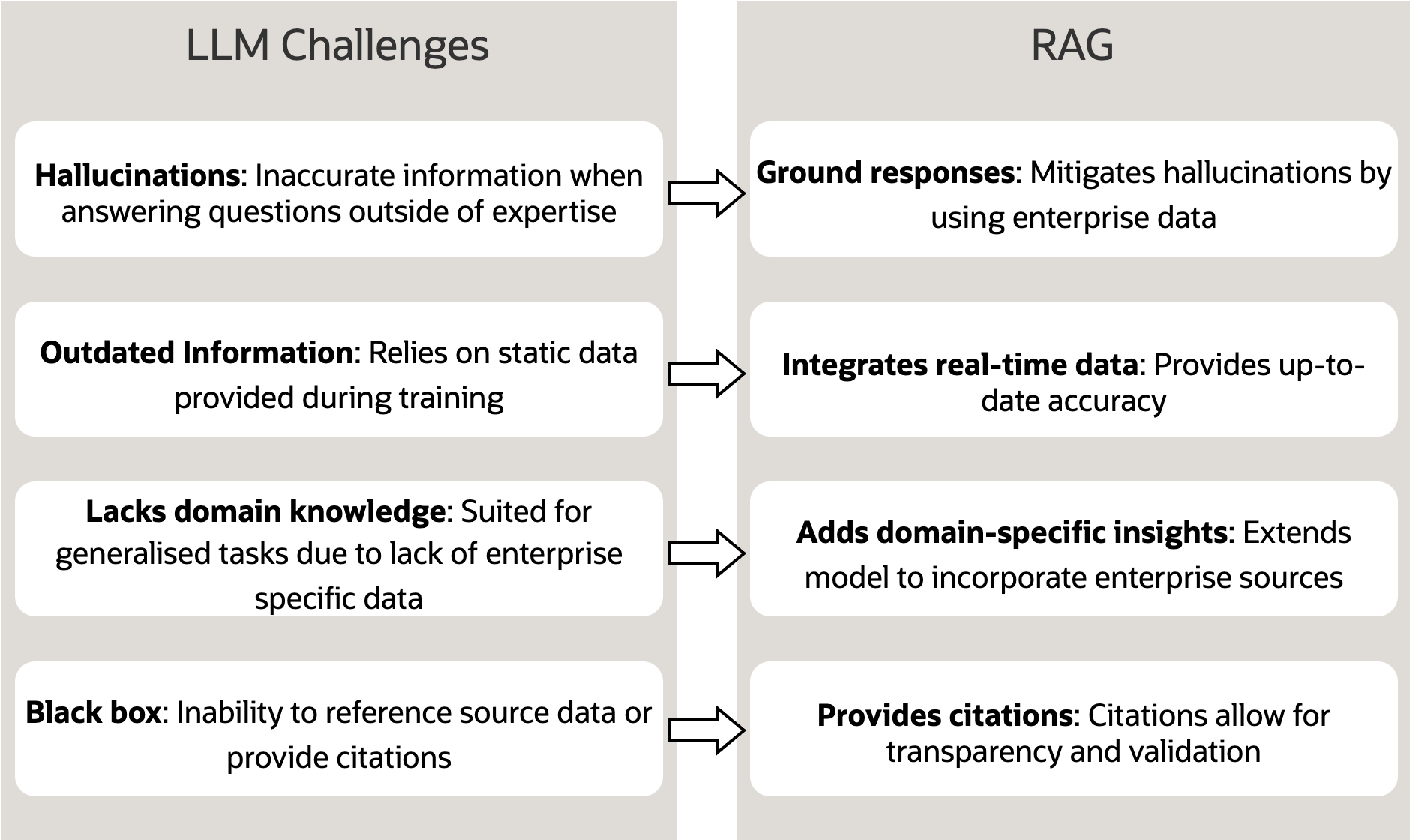
To further explore the potential of RAG solutions with Oracle Cloud Infrastructure, check out the following resources:
