To get started understanding ZDT Patching, let’s take a look at it in its
simplest form, the rolling restart. In
many ways, this simple use case is the foundation for all of the other types of
rollouts – Java Version, Oracle Patches, and Application Updates. Executing the rolling restart requires the
coordinated and controlled shutdown of all of the managed servers in a domain
or cluster while ensuring that service to the end-user is not interrupted, and
none of their session data is lost.
The administrator can start a rolling restart by issuing the WLST command
below:
rollingRestart(“Cluster1”)
In this case, the rolling restart will affect all managed servers in the
cluster named “Cluster1”. This is called
the target. The target can be a single
cluster, a list of clusters, or the name of the domain.
When the command is entered, the WebLogic Admin Server will analyze the
topology of the target and dynamically create a workflow (also called a
rollout), consisting of every step that needs to be taken in order to
gracefully shutdown and restart each managed server in the cluster, while
ensuring that all sessions on that managed server are available to the other
managed servers. The workflow will also
ensure that all of the running apps on a managed server are fully ready to
accept requests from the end-users before moving on to the next node. The rolling restart is complete once every
managed server in the cluster has been restarted.
A diagram illustrating this process on a very simple topology is shown
below. In the diagram you can see that a node is taken offline (shown in red) and end-user requests that would have gone to that node are re-routed to active nodes. Once the servers on the offline node have been restarted and their applications are again ready to receive requests, that node is added back to the pool of active nodes and the rolling restart moves on to the next node.
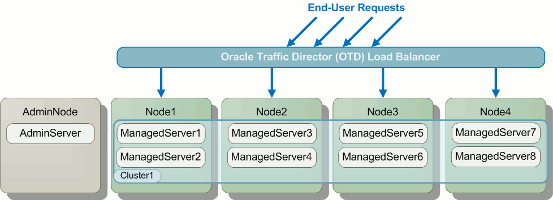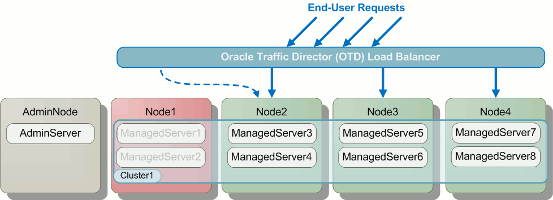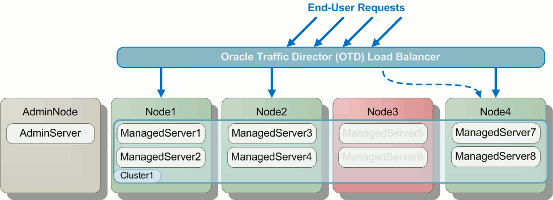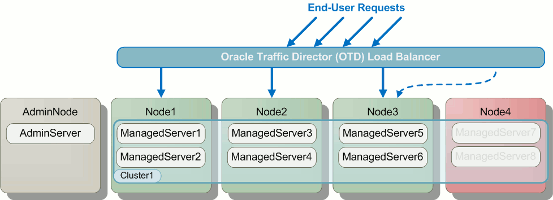
Illustration of a Rolling Restart Across a Cluster.
The rolling restart functionality was introduced based on customer
feedback. Some customers have a policy
of preemptively restarting their managed servers in order to refresh the memory
usage of applications running on top of them. With this feature we are greatly simplifying that tedious and time
consuming process, and doing so in a way that doesn’t affect end-users.
For more information about Rolling Restarts with Zero Downtime Patching,
view the documentation.