This article discusses designing and deploying an Active GridLink (AGL) data source to handle database down times with an Oracle Database RAC environment.
AGL Configuration for Database Outages
It is assumed that an Active GridLink data source is configured as described Using Active GridLink Data Sources with the following.
– FAN enabled. FAN provides rapid notification about state changes for database services, instances, the databases themselves, and the nodes that form the cluster. It allows for draining of work during planned maintenance with no errors whatsoever returned to applications.
– Either auto-ONS or an explicit ONS configuration.
– A dynamic database service. Do not connect using the database service or PDB service – these are for administration only and are not supported for FAN.
– Testing connections. Depending on the outage, applications may receive stale connections when connections are borrowed before a down event is processed. This can occur, for example, on a clean instance down when sockets are closed coincident with incoming connection requests. To prevent the application from receiving any errors, connection checks should be enabled at the connection pool. This requires setting test-connections-on-reserve to true and setting the test-table (the recommended value for Oracle is “SQL ISVALID”).
– Optimize SCAN usage. As an optimization to force re-ordering of the SCAN IP addresses returned from DNS for a SCAN address, set the URL setting LOAD_BALANCE=TRUE for the ADDRESSLIST in database driver 12.1.0.2 and later. (Before 12.1.0.2, use the connection property oracle.jdbc.thinForceDNSLoadBalancing=true.)
Planned Outage Operations
For a planned downtime, the goals are to achieve:
– Transparent scheduled maintenance: Make the scheduled maintenance process at the database servers transparent to applications.
– Session Draining: When an instance is brought down for maintenance at the database server draining ensures that all work using instances at that node completes and that idle sessions are removed. Sessions are drained without impacting in-flight work.
The goal is to manage scheduled maintenance with no application interruption while maintenance is underway at the database server. For maintenance purposes (e.g., software and hardware upgrades, repairs, changes, migrations within and across systems), the services used are shutdown gracefully one or several at a time without disrupting the operations and availability of the WLS applications. Upon FAN DOWN event, AGL drains sessions away from the instance(s) targeted for maintenance. It is necessary to stop non-singleton services running on the target database instance (assuming that they are still available on the remaining running instances) or relocate singleton services from the target instance to another instance. Once the services have drained, the instance is stopped with no errors whatsoever to applications.
The following is a high level overview of how planned maintenance occurs.
–Detect “DOWN” event triggered by DBA on instances targeted for maintenance
–Drain sessions away from that (those) instance(s)
–Perform scheduled maintenance at the database servers
–Resume operations on the upgraded node(s)
Unlike Multi Data Source where operations need to be coordinated on both the database server and the mid tier, Active GridLink co-operates with the database so that all of these operations are managed from the database server, simplifying the process. The following table lists the steps that are executed on the database server and the corresponding reactions at the mid tier.
| Database Server Steps |
Command |
Mid Tier Reaction |
| Stop the non-singleton service without ‘-force’ or relocate the singleton service.
Omitting the –server option operates on all services on the instance. |
$ srvctl stop service –db <db_name>
or
$ srvctl relocate service –db <db_name> |
The FAN Planned Down (reason=USER) event for the service informs the connection pool that a service is no longer available for use and connections should be drained. Idle connections on the stopped service are released immediately. In-use connections are released when returned (logically closed) by the application. New connections are reserved on other instance(s) and databases offering the services. This FAN action invokes draining the sessions from the instance without disrupting the application. |
| Disable the stopped service to ensure it is not automatically started again. Disabling the service is optional. This step is recommended for maintenance actions where the service must not restart automatically until the action has completed. . |
$ srvctl disable service –db <db_name> -service <service_name> -instance <instance_name> |
No new connections are associated with the stopped/disabled service at the mid-tier. |
| Allow sessions to drain. |
|
The amount of time depends on the application. There may be long-running queries. Batch programs may not be written to periodically return connections and get new ones. It is recommended that batch be drained in advance of the maintenance. |
| Check for long-running sessions. Terminate these using a transactional disconnect. Wait for the sessions to drain. You can run the query again to check if any sessions remain. |
SQL> select count(*) from ( select 1 from v$sessionwhere service_name in upper(‘<service_name>’) union all |
The connection on the mid-tier will get an error. If using application continuity, it’s possible to hide the error from the application by automatically replaying the operations on a new connection on another instance. Otherwise, the application will get a SQLException. |
| Repeat the steps above. |
Repeat for all services targeted for planned maintenance |
|
| Stop the database instance using the immediate option. |
$ srvctl stop instance –db <db_name> |
No impact on the mid-tier until the database and service are re-started. |
| Optionally disable the instance so that it will not automatically start again during maintenance. This step is for maintenance operations where the services cannot resume during the maintenance. |
$ srvctl disable instance –db <db_name> -instance <instance_name> |
|
| Perform the scheduled maintenance work. |
Perform the scheduled maintenance |
|
| Enable and start the instance. |
$ srvctl enable instance –db <db_name> -instance <instance_name> |
|
| Enable and start the service back. Check that the service is up and running. |
$ srvctl enable service –db <db_name>
$ srvctl start service –db <db_name> |
The FAN UP event for the service informs the connection pool that a new instance is available for use, allowing sessions to be created on this instance at the next request submission. Automatic rebalancing of sessions starts. |
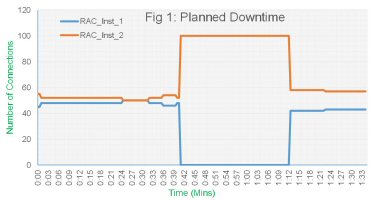
The following figure shows the distribution of connections for a service across two RAC instances before and after Planned Downtime. Notice that the connection workload moves from fifty-fifty across both instances to hundred-zero. In other words, RAC_INST_1 can be taken down for maintenance without any impact on the business operation.
Unplanned Outages
The configuration is the same for planned and unplanned outages.
There are several differences when an unplanned outage occurs.
- A component at the database server may fail making all services unavailable on the instances running at that node. There is not stop or disable on the services because they have failed.
- The FAN unplanned DOWN event (reason=FAILURE) is delivered to the mid-tier.
- For an unplanned event, all sessions are closed immediately preventing the application from hanging on TCP/IP timeouts. Existing connections on other instances remain usable, and new connections are opened to these instances as needed.
- There is no graceful draining of connections. For those applications using services that are configured to use Application Continuity, active sessions are restored on a surviving instance and recovered by replaying the operations, masking the outage from applications. If not protected by Application Continuity, any sessions in active communication with the instance will receive a SQLException.
