Introduction
WebLogic’s 12.2.1 release features a greatly simplified, easy to use JMS configuration and administration model. This simplified model
works seamlessly in both Cluster and Multi-Tenant/Cloud environments, making
JMS configuration a breeze and portable. It essentially lifts all major limitations for the initial version of
the JMS ‘cluster targeting’ feature that was added in 12.1.2 plus adds
enhancements that aren’t available in the old administration model.
- Now, all types
of JMS Service artifacts can take full advantage of a Dynamic Cluster
environment and automatically scale up as well as evenly distribute the load
across the cluster in response to cluster size changes. In other words, there
is no need for individually configuring and deploying JMS artifacts on every
cluster member in response to cluster growth or change. - New easily configured high availability
fail-over, fail-back, and restart-in-place settings provide capabilities that
were previously only partially supported via individual targeting. - Finally, 12.2.1 adds the ability to configure
singleton destinations in a cluster within the simplified configuration model.
These capabilities apply to all WebLogic Cluster types,
including ‘classic’ static clusters which combine a set of individually
configured WebLogic servers, dynamic clusters which define a single dynamic WL
server that can expand into multiple instances, and mixed clusters that combine
both a dynamic server and one or more individually configured servers.
Configuration Changes
With this model, you can now easily configure, control
dynamic scaling and high availability behavior for JMS in a central location,
either on a custom Store for all JMS artifacts that handle persistent data, or
on a Messaging Bridge. The new
configuration parameters introduced by this model are collectively known as
“High Availability” policies. These are
exposed to the users via management Consoles (WebLogic Administration Console,
Fusion Middleware Control (FMWc)) as well as through WLST scripting and Java MBean
APIs. When they’re configured on a store, all the JMS service artifacts that
reference that store simply inherit these settings from the store and behave
accordingly.
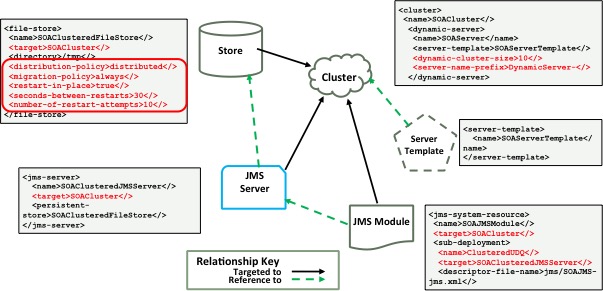
Figure 1. Configuration Inheritance
The most important configuration parameters are, distribution-policy and migration-policy, which control dynamic scalability
and high availability respectively for their associated service artifacts.
When a distribution-policy
is set to distributed on one
configured artifact, then at the deploy time, the system automatically creates
an instance on each cluster member that joins the cluster. When set to singleton, then the system creates a
single instance for the entire cluster.
Distributed instances are uniquely named after their host WebLogic
Server (their configured name is suffixed with the name of their server), where
it is initially created and started for runtime monitoring and location tracking
purposes. This server is called the home or preferred server for the
distributed instances that are named after it. A singleton
instance is not decorated with a server name, instead it’s simply suffixed with
“-01” and the system will choose one of the managed servers in the cluster to
host the instance.
A distribution-policy works in concert with a new high
availability option called the migration-policy,
to ensure that instances survive any unexpected service failures, server
crashes, or even a planned shutdown of the servers. It does this by automatically migrating them
to available cluster members.
For the migration-policy,
you can choose one of three options: on-failure,
where the migration of instances will take place only in the event of
unexpected service failures or server crashes; always, where the migration of instances will take place even
during a planned administrative shutdown of a server; finally, you can choose
to have off as an option to disable
the service level migration if needed.

Figure 2. Console screenshot: HA Configuration
In addition to the migration-policy, the new model offers
another high availability notion for stores called the restart-in-place capability. When enabled, the system will first
try to restart failing store instances on their current server before failing over
to another server in the cluster. This option can be fine tuned to limit the
number of attempts and delay between each attempt. This capability prevents the
system from doing unnecessary migration in the event of temporary glitches,
such as a database outage, or unresponsive network or IO requests due to
latency and overload. Bridges ignore restart-in-place settings as they already
automatically restart themselves after a failure (they periodically try to reconnect).
Note that the high availability enhancement not only offers
failover of the service artifacts in the event of failure, it also offers
automatic failback of distributed instances when their home server gets
restarted after a crash or shutdown – a high availability feature that isn’t
available in previous releases. This allows the applications to achieve
high-level server/configuration affinity whenever possible. Unlike in previous releases, both during
startup and failover, the system will also try to ensure that the instances are
evenly distributed across the cluster members thus preventing accidental
overload of any one server in the cluster.
Here’s a table that summarizes the new distribution,
migration, and restart-in-place settings:
| Attribute Name |
Description |
Options |
Default |
| distribution-policy |
Controls JMS service instance counts and names. |
[Distributed | Singleton] |
Distributed |
| migration-policy |
Controls HA behavior. |
[Off | On-Failure | Always] |
Off |
| restart-in-place |
Enables automatic restart of a failing store instance(s) with a healthy WebLogic server. |
[true | false ] |
true |
| seconds-between-restarts |
Specifies how many seconds to wait in between attempts to restart-in-place for a failed service. |
[1 … {Max Integer}] |
30 |
| number-of-restart-attempts |
Specifies how many restart attempts to make before migrating the failed services |
[-1,0 … {Max Long}] |
6 |
| initial-boot-delay-seconds |
The length of time to wait before starting an artifact’s instance on a server. |
[-1,0 … {Max Long}] |
60 |
| failback-delay-seconds |
The length of time to wait before failing back an artifact to its preferred server. |
[-1,0 … {Max Long}] |
30 |
| partial-cluster-stability-seconds |
The length of time to wait before the cluster should consider itself at a “steady state”. Until that point, only some resources may be started in the cluster. This gives the cluster time to come up slowly and still be easily laid out |
[-1,0 … {Max Long}] |
240 |
Runtime Monitoring
As mentioned earlier, when targeted to cluster, system
automatically creates one (singleton) or more (distributed) instances from a
single configured artifact. These instances are backed by appropriate runtime
mbeans, named uniquely and made available for accessing/monitoring under the
appropriately scoped server (or partition, in case of multi-tenant environment)
runtime mbean tree.
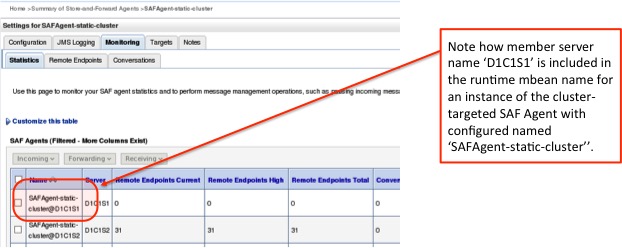
Figure 3. Console screenshot: Runtime Monitoring
The above screenshot shows how a cluster targeted SAF Agent runtime instance is decorated with cluster member server name to make it unique.
Validation and Legal
Checks
There are legal checks and validation rules in place to
prevent the users from configuring invalid combinations of these new
parameters. The following two tables list the supported combinations of these
two new policies by service types as well by resource type respectively.
|
Service Artifact |
Distribution Policy |
Migration Policy |
||
| Off |
Always |
On-Failure |
||
| Persistent Store |
Distributed |
✓ |
✓ |
✓ |
| Singleton |
✓ |
✓ |
||
| JMS Server |
Distributed |
✓ |
✓ |
✓ |
| Singleton |
✓ |
✓ |
||
| SAF Agent |
Distributed |
✓ |
✓ |
✓ |
| Path Service |
Singleton |
✓ |
||
| Messaging Bridge |
Distributed |
✓ |
✓ |
|
| Singleton |
✓ |
|||
In the above table, the legal combinations are listed based
on the JMS service types. For example, the Path Service, a messaging service
that persists and holds the routing information for messages that take
advantage of a popular WebLogic ordering extension called unit-of-order or
unit-of-work routing, is a singleton service that should be made highly
available in a cluster regardless of whether there is a service failure or
server failure. So, the only valid and legal combinations of HA policies for
this service configuration are: distribution-policy
as singleton and migration-policy as always.
Some rules are also derived based on the resource types that
are being used in an application. For example, for any JMS Servers that host uniform
distributed destinations or for SAF Agents that would always host imported
destinations, the distribution-policy
as singleton does not make any sense
and is not allowed.
| Resource Type |
Singleton |
Distributed |
| JMS Servers (hosting Distributed Destinations) |
✓ |
|
| SAF Agent (hosting Imported Destinations) |
✓ |
|
| JMS Servers (hosting Singleton Destinations) |
✓ |
|
| Path Service |
✓ |
|
| Bridge |
✓ |
✓ |
In the event of an invalid configuration that violates these
legal checks there will be error or log messaging indicating the same and in
some cases it may cause deployment server startup failures.
Best Practices
To take full advantage of the improved capabilities, first design
your JMS application by carefully identifying the scalability and availability
requirements as well as the deployment environments. For example, identify
whether the application will be deployed to a Cluster or to a multi-tenant
environment and whether it will be using uniform distributed destinations or
standalone (non-distributed) destinations or both.
Once the above requirements are identified then always
define and associate a custom persistent store with the applicable JMS service
artifacts. Ensure that the new HA parameters are explicitly set as per the
requirements (use the above tables as a guidance) and that both a JMS service
artifact and its corresponding store are similarly targeted (to the same
cluster or to the same RG/T in case of multi-tenant environment).
Remember, the JMS high availability mechanism depends on WebLogic
Server Health and Singleton Monitoring services, which in turn rely on a
mechanism called “Cluster Leasing”. So you need to setup valid cluster leasing
configuration particularly when the migration-policy
is set to either on-failure or always or when you want to create a
singleton instance of a JMS service artifact. Note that WebLogic offers two
leasing options: Consensus and Database, and we highly recommend using Database
leasing as a best practice.
Also it is highly recommended to configure high availability
for WebLogic’s transaction system, as JMS apps often directly use transactions,
and JMS internals often implicitly use transactions. Note that WebLogic transaction high
availability requires that all managed servers have an explicit listen-address
and listen-port values configured, instead of leaving to the defaults, in order
to yield full transaction HA support. In case of dynamic cluster configuration,
you can configure these settings as part of the dynamic server template definition.
Finally, it is also preferred to use NodeManager to start all the managed servers of a cluster over any
other methods.
For more information on this feature and
other new improvements in Oracle WebLogic Server 12.2.1 release, please see What’s
New chapter of the public documentation.
Conclusion
Using these new enhanced capabilities of WebLogic JMS, one
can greatly reduce the overall time and cost involved in configuring and
managing WebLogic JMS in general, plus scalability and high availability in
particular, resulting in ease of use with an increased return on investment.